Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

AI男の娘イラスト生成術入門4(上級編) (Pixiv Fanbox)
Content
1. はじめに
今回の記事は上級編です。
前回の中級編に引き続き、AI男の娘イラスト生成術の解説をしていきます。
今回はNSFW画像(オリキャラが複数の画像で連続して登場するもの)をターゲットにします。
「オリキャラが複数の画像で連続して登場するもの」というのは、例えば次のものです。
{kind=link}
{kind=link}
{kind=link}
有名キャラの場合は、そのキャラ名をプロンプトに指定するだけで生成されます。
これは、前回の内容からも明らかです。
また、マイナーキャラの場合でも、誰かしらがLoRAモデルを作っている可能性があります。
そうでなくても、学習素材となる画像が豊富ならば、自分でLoRAモデルを作る方法もあります。
問題なのは、オリキャラの場合です。
LoRAモデルを作るにしても、学習素材がありません。
自分である程度描けるならそれで良しですが、そうでない場合はどうしたらよいのか?
そうでない場合での対応について、一つの方法を解説していきます。
ざっくり言うと、3Dキャラクターを作って、そのキャラクター画像からのプロンプト生成とimg2imgでキャラ属性を固定していきます。
※この方法だと大きな特徴は反映されますが、小さな特徴はあまり反映されません。
なお、前回の記事と同様に手順を示しますが、こちらでも自己責任での対応をお願いします。
2. 準備
1. 3Dキャラクターを作ります。VRoid Studioなら直感的で作りやすいので、それをオススメします。もちろんBlenderなどに習熟されている方には、そちらもオススメします。
ライセンス次第ですが、他の方が作られた3Dキャラクターを使うのもありだと思います。
embed: hub.vroid.com2. 次の2つのExtensionをインストールします。インストール方法は前回説明した通りです。
「https://github.com/hnmr293/sd-webui-cutoff」
※プロンプト内のタグ(トークン)の有効範囲を限定する為の拡張機能です。例えば、「green hair, orange eyes」(緑の髪、オレンジの目)とした場合、実はorangeはhairにかかる可能性もあります。そのようなことを防止するために使います。
「https://github.com/Mikubill/sd-webui-controlnet」
※プロンプトと元画像以外で、生成される画像をコントロールする方法を提供する拡張機能です。例えば、輪郭線情報や深度情報やポーズ情報などを別途入力し、それに従ってもらう形で画像生成ができます。
3. 後者のものを使うには、追加でモデルのインストールが必要になります。
以下のサイトから、次のファイルをダウンロードし、「{Stable Diffusion web UIのインストールフォルダ}\stable-diffusion-webui\models\ControlNet」に入れてください。
・cldm_v15.yaml ……設定ファイル
・cldm_v21.yaml ……設定ファイル
・control_canny-fp16.safetensors ……輪郭線情報でのコントロールを可能にするモデル
※他のモデルも有用なので、一緒にダウンロードしておいても良いと思います。
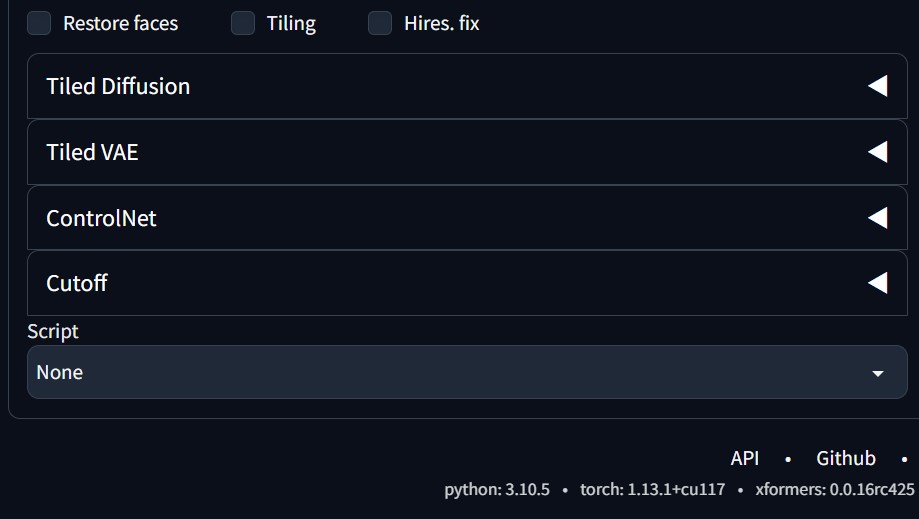
4. Extensions画面のApply and restart UIボタンを押した後、txt2img画面やimg2img画面に「ControlNet」と「Cutoff」の欄が追加されていたら成功です。
{kind=link}
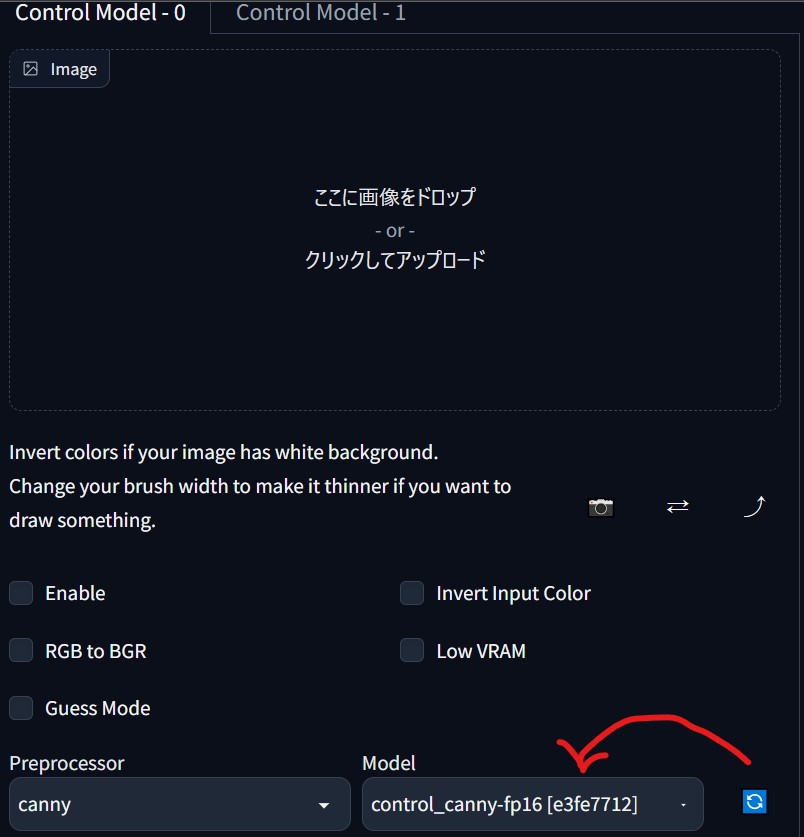
5. 念のために、ControlNet欄でダウンロードしたモデルが使えるようになっているかも確認してください。右の青いボタンを押した後、Model項目でダウンロードしたものが選択できるのを確認してください。
{kind=link}
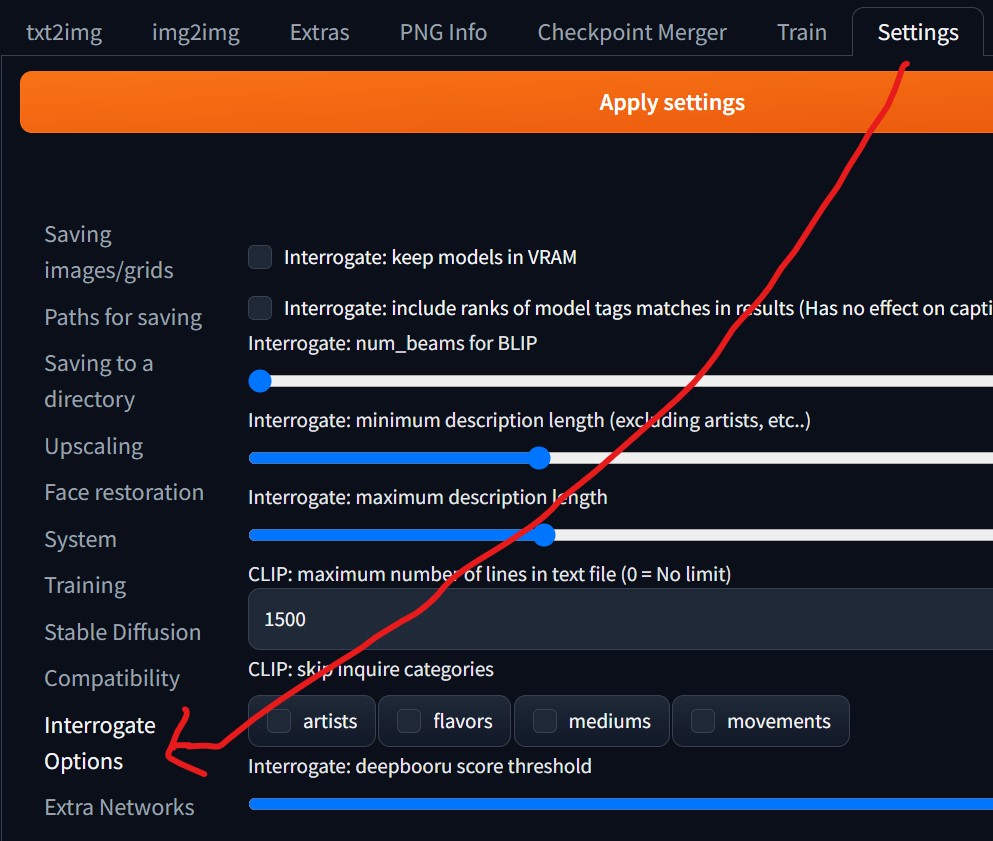
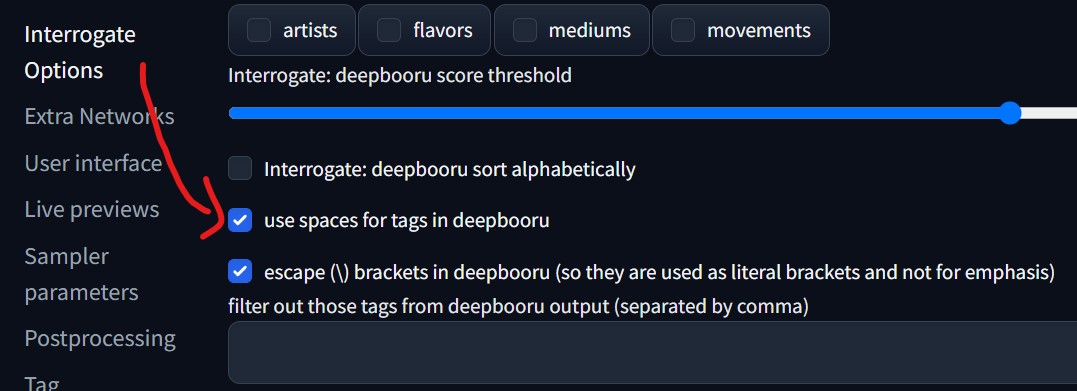
6. そして、プロンプト生成のためにSettings画面から「Interrogate Options」を選択し、「use spaces for tags in deepbooru」をONにします。
※画像からタグ(プロンプト)を生成する時のオプションで、タグ内の「_」を半角スペースにします。例えば、「green_hair, orange_eyes」なら「green hair, orange eyes」に置き換えられます。
{kind=link}
{kind=link}
これで準備ができました。
3. 生成
1. 3Dキャラクターにポーズを取らせ、画像を撮ります。(VRoid Studioを使う場合は、そのツール本体で撮影できます。VRoid Studioから出力したVRMファイルを別のツールから操作して、撮影することもできます)
2. その画像を編集し、生成したい画像のサイズ(デフォルトでは、縦横512px)に合わせます。必要に応じて、背景なども編集します。
※元画像は別途残しておいてください。
■サンプル画像
{kind=link}
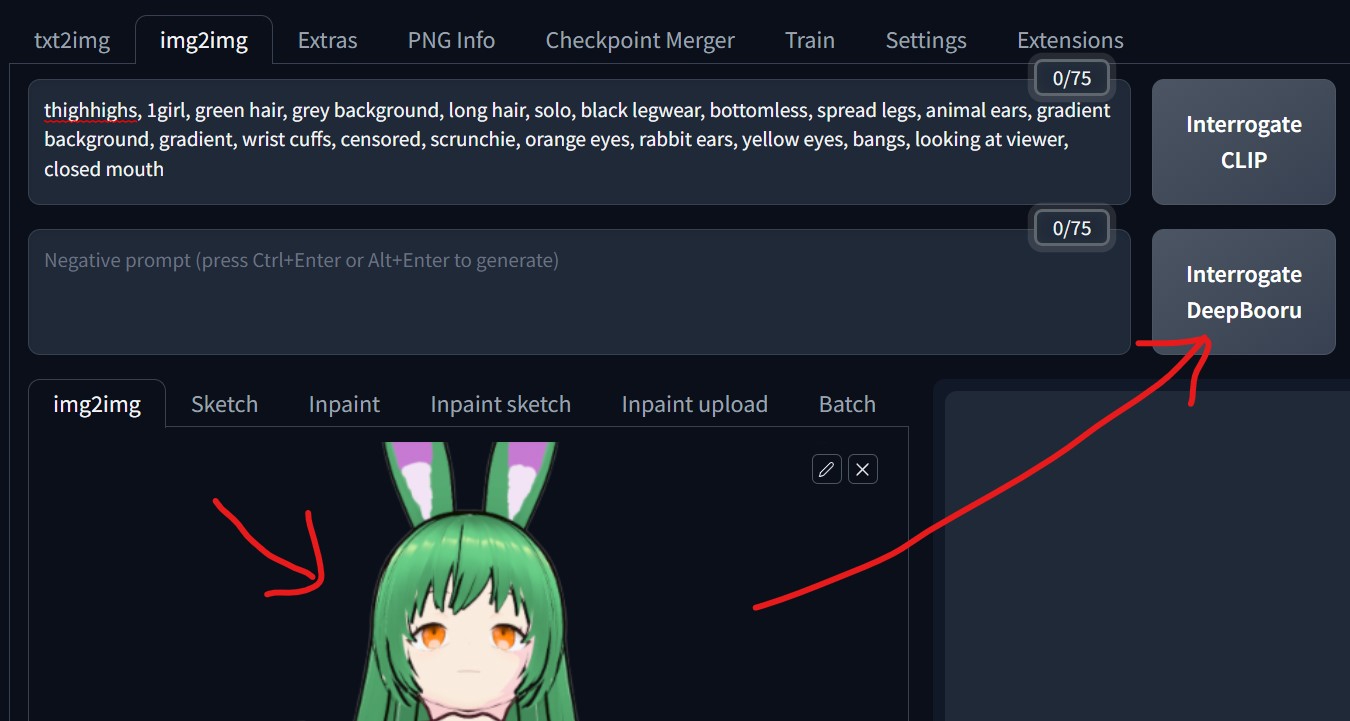
3. img2img画面に"元画像"を置き、Interrogate DeepBooruボタンを押します。
※プロンプトが自動生成され、Prompt欄に表示されます。
{kind=link}
### Prompt ###
thighhighs, 1girl, green hair, grey background, long hair, solo, black legwear, bottomless, spread legs, animal ears, gradient background, gradient, wrist cuffs, censored, scrunchie, orange eyes, rabbit ears, yellow eyes, bangs, looking at viewer, closed mouth
4. このプロンプトで、生成画像に反映させたくない要素は消し、残ったものから「キャラ属性を表すもの」と「動作を表すもの」を抽出します。
※重複がある場合は、より具体的な方を残します。(例:animal ears VS rabbit ears → rabbit ears)
※不足しているものがあれば、補完します。(例:tank top)
### Prompt(キャラ属性) ###
rabbit ears, green hair, long hair, orange eyes, tank top, wrist cuffs, bottomless, black legwear
### Prompt(動作) ###
spread legs, looking at viewer
5. 編集後の画像で同じようにプロンプトを生成します。
### Prompt ###
tree, thighhighs, day, outdoors, black legwear, 1girl, green hair, rabbit ears, palm tree, bush, spread legs, blue sky, solo, sky, long hair, animal ears, bottomless, forest, nature, censored, orange eyes, building, wrist cuffs, house, yellow eyes, scrunchie, park, looking at viewer, grass, photo background, closed mouth, bangs, cloud
6. このプロンプトで、生成画像に反映させたい「環境要素」のみを抽出します。そして、先に抽出したプロンプトと合わせます。また、例の定型句もプロンプトの前後に入れてください。
### Prompt(環境) ###
outdoors, house, bush, sky, day
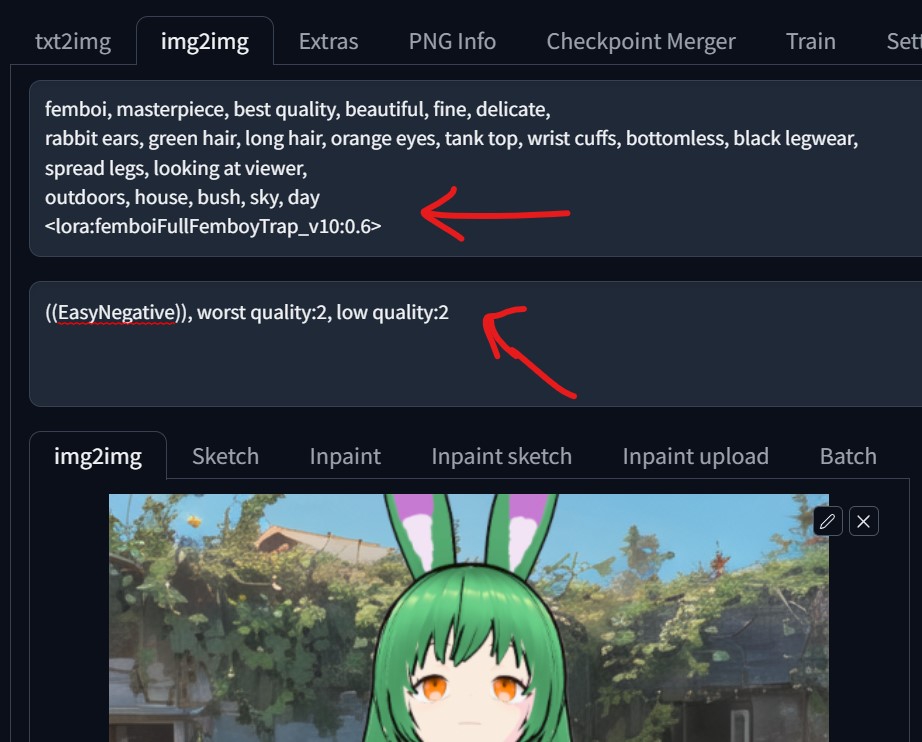
### Prompt(統合) ###
femboi, masterpiece, best quality, beautiful, fine, delicate,
rabbit ears, green hair, long hair, orange eyes, tank top, wrist cuffs, bottomless, black legwear,
spread legs, looking at viewer,
outdoors, house, bush, sky, day
※LoRAモデルの適用加減を下げて0.6にしています。この方法だと1は強すぎるようでした。
7. img2img画面で以降の設定を加えて、Generateボタンを押します。
{kind=link}
### Prompt ###
(上のもの)
### Negative Prompt ###
((EasyNegative)), worst quality:2, low quality:2
{kind=link}
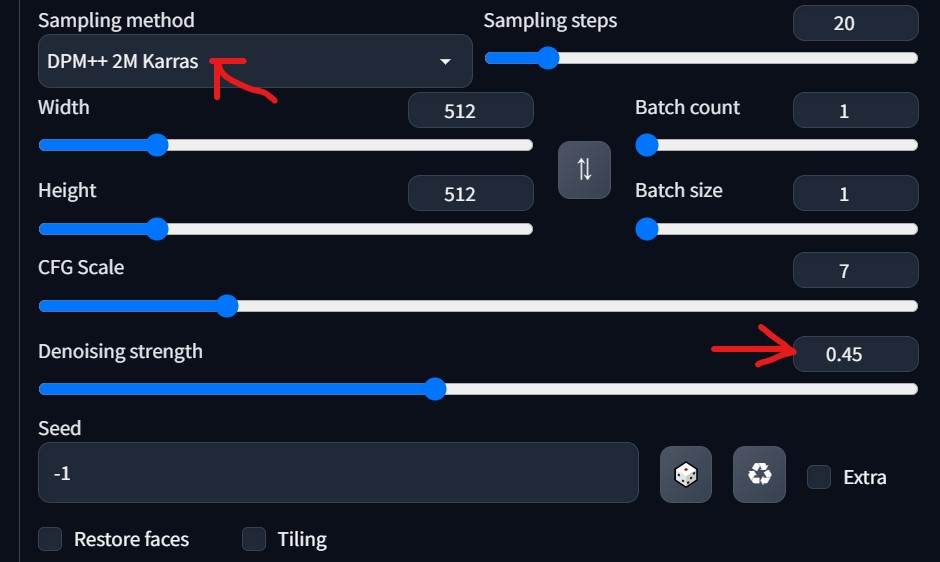
### Sampling method ###
DPM++ 2M Karras
### Denoising strength ###
0.45前後(要調整)
{kind=link}
{kind=link}
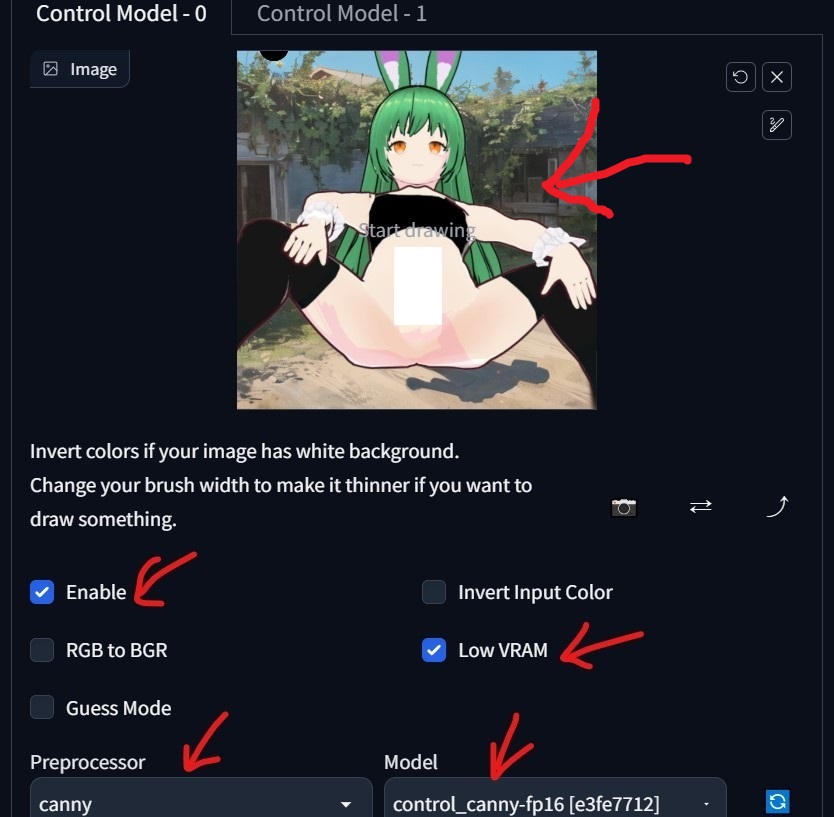
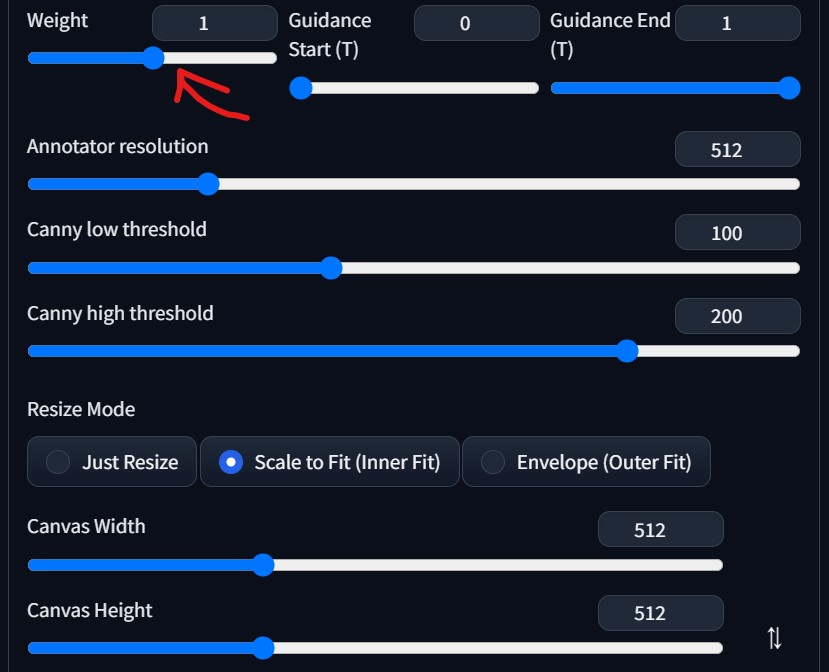
### ControlNet ###
画像:(上のもの)
Enable:ON
Low VRAM:ON
※高スペックな環境の場合はOFF
Preprocessor:canny
Model:control_canny-fp16
Weight:1(要調整)
{kind=link}
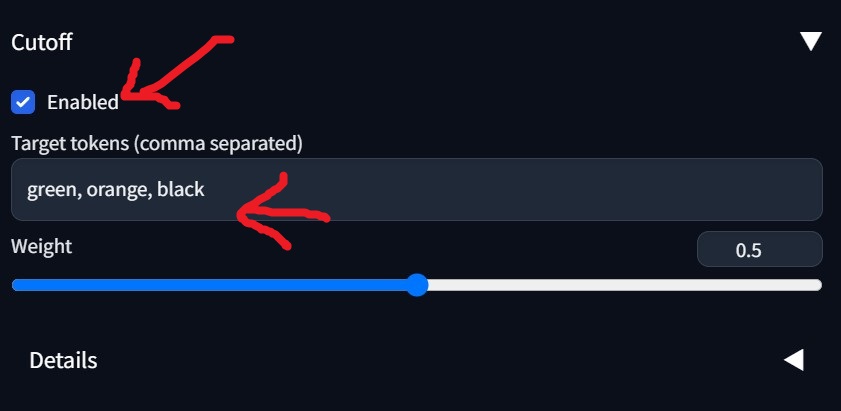
### Cutoff ###
Enabled:ON
Target Tokens:green, orange, black
※プロンプト内の色に関わる単語すべて
■生成結果
{kind=link}
■同じ手順での別の生成結果
{kind=link}
{kind=link}
4. おわりに
お気づきのことと思いますが、冒頭の例示画像と先ほどの生成画像は、同じ元画像からの生成になっています。
では、なぜこれほど画風が違うかと言えば、一番の理由はLoRAモデルを使っていないからです。
LoRAモデルを使った場合は、画風もそのLoRAモデル特有のものに寄ってしまいます。
この画風が良いと感じるなら、それでOKです。
私も良いと感じます。
ただ、更なるハッテンを目指すなら、「LoRAモデルを使わない」又は「LoRAモデルで求めていない影響を軽減する」必要があります。
その意味で、前者ならプロンプトエンジニアリングの知識が、後者ならLoRAモデルの層別適用の知識が、重要となります。
精進していきましょう。
これにて、「AI男の娘イラスト生成術入門」シリーズは、ひとまずの完了といたします。
おまけ記事は、今日中に投稿する予定です。
(おわり)
Files