Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

Controlnet1.1爆誕!顔抽出&アニメ主線抽出&線画塗りを試してみた (Pixiv Fanbox)
Content
こんばんは、スタジオ真榊です。AIイラスト術天下一武道会の開催真っ最中ですが、Controlnet1.1がSDwebUIの拡張機能にぃ…
きたー!!!
というわけで、既に午前2時なのでかなり限定的な内容にはなりますが、前置きは全てすっ飛ばして最速でアプデ方法と注意点、使用感をお伝えしていきます。今回は「FaceLandmark」による顔抽出や、アニメ塗りの主線を抜き出せる「lineart anime」といった目玉がもりだくさん。ファーストタッチレビューなので一部のモデルしか触れられないのが残念ですが、さっそく見ていきましょう。
Check it out!
(※あす以降、こちらの記事に加筆する形で全てのモデルの使用感などについてお伝えしていきます)
アップデート方法
{kind=link}
こちらの記事をお読みの方は既にほとんどの方がControlnet拡張を入れていると思うので、インストール方法ではなくアップデート方法からさくっと説明します。webUIの「拡張機能」から「アップデートを確認」をクリック。「sd-webui-controlnet」の欄の右端にある「アップデート」のところに「behind」と出たら、「適用してUIを再起動」しましょう。
するといつも通りwebUIが再読み込みされるのですが、Controlnetのウィンドウ自体がtxt2txtのタブのいつもの場所から消えてしまっているかもしれません。そんなときは慌てずに、いったんブラウザのwebUIタブを閉じましょう。黒いコマンドプロンプト画面を終了させて、いちからwebUIを立ち上げ直せば、再びいつもの場所にウィンドウが出現しているはずです。
次に、controlnet1.1用の各抽出モデルをダウンロードしましょう。まずはこちらのURLにアクセス。
こちらに並んでいる「.pth」で終わるモデルファイルをダウンロードし、「stable-diffusion-webui\extensions\sd-webui-controlnet\models」に入れていきましょう。それぞれのpthファイルの「1.45GB LFS↓」をクリックすればダウンロードできます。
{kind=link}
かなり大きいサイズなので、最初から全てDLせず、試したいものだけでもいいかもしれません。ちなみに、今夜試すのは「openpose」と「lineart anime」だけです。公式pthファイルを使う場合、「yaml」ファイルはダウンロードする必要はありません。
【中上級者向け】
容量が半分の723MBに抑えられたfp16版も既に出ているので、わかる方は始めからこちらを試してもOKです。ただ、1.45GBの公式版と違い、対応するyamlファイル名とモデルのファイル名を手動変更で一致させる必要がありますので、その点だけご注意ください。
Openpose fullの威力
さて、最初に試すのは新「openpose」から。公式が「画像生成AIで使用OK」とおっしゃってくださっているポーズマニアックス様から、次のポーズをお借りしました。
{kind=link}
ドン。
こちらをControlnet画面で読み込み、プリプロセッサ(前処理)「openpose full」、モデル「control_v11p_sd15_openpose」を選んで生成します。ちなみに、一回目の生成時に読み込みが必要なので、いきなり「アノテーション結果をプレビュー」を押しても反応しません。焦らなくて大丈夫です。
{kind=link}
このポーズをしている女の子を描いてほしいだけなので、プロンプトは適当に「1girl,smile,(high resolution,masterpiece,best quality,extremely detailed CG,official art,:1.3)」とし、いざ生成ボタンをクリック。初回のみしばらく読み込みが生じるので、すぐ生成されなくても焦る必要はありません。
気長に待っていると…。
{kind=link}
はいこのように、ポーズだけでなく、手や顔の向きまで同時抽出に成功しました。ちなみに今夜の記事に使用した画像は一切チェリーピックなし、全て一発生成です。何しろ社畜にはあと4時間しか睡眠時間が残されていない!
ちなみにこちらの顔抽出(face landmark)ですが、さきほどのようなリアル調の画像はうまく抜き出すことができたものの、次のようないかにもイラスト調のものについては上手に抜き出せませんでした。自分でプロットすることもできると思うので、おいおい拡張機能の登場に期待しましょう。
{kind=link}
▲イラスト調だと表情抽出がうまくいかない?
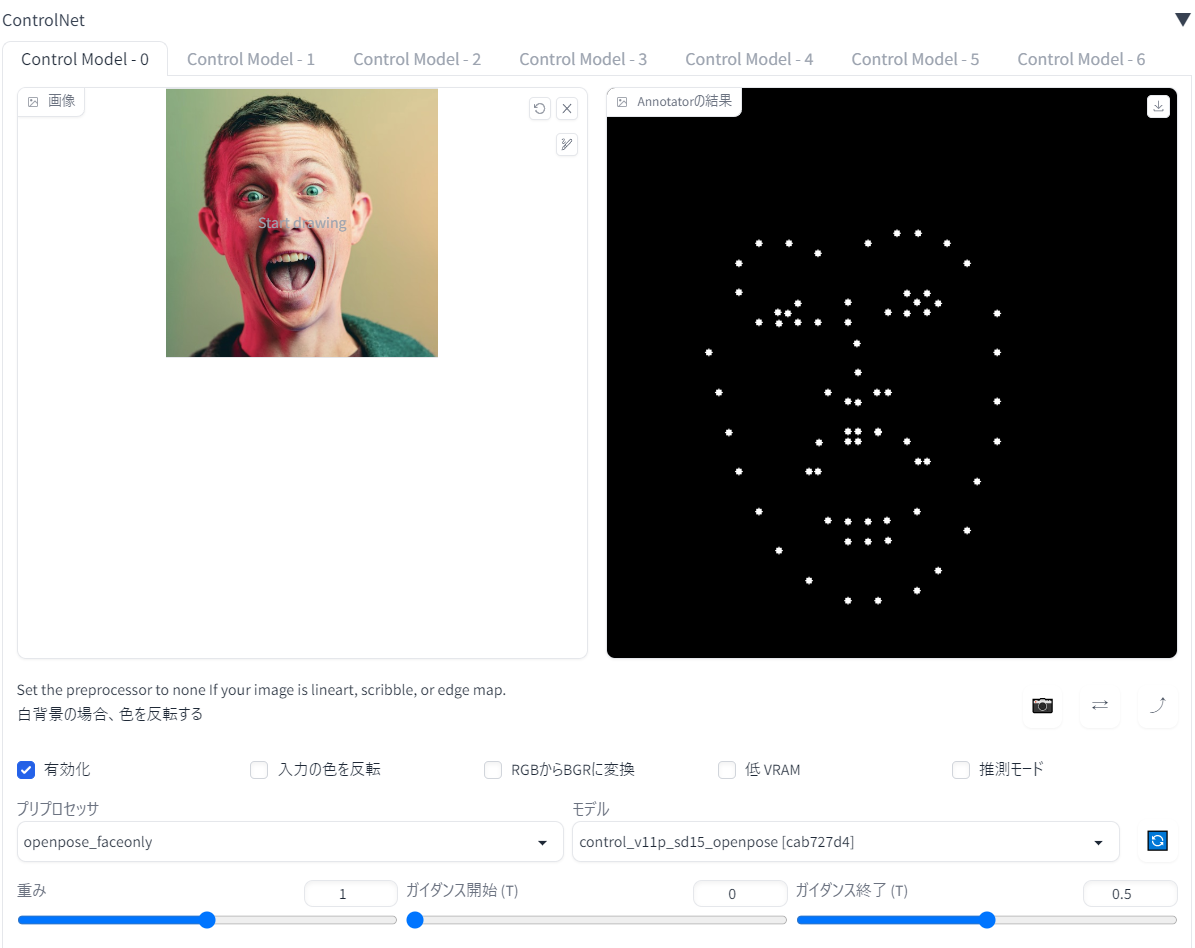
「Face landmark」で表情抽出にトライ
先程はいきなり顔・ポーズ・手の揃ったopenpose fullを試しましたが、今度はせっかくの「新顔」であるFace landmark機能をもっと試してみます。これはその名の通り、顔を構成する「地点」をプロットすることで抽出する機能。眉、目、鼻、口、輪郭をそれぞれ抜き出し、元画像の表情を写し取ることができます。
こちら(▲)はControlnetで一足先にFaceLandmarkを試すことができたスペース。せっかくなのでこちらのサンプル画像を借りて、表情抽出をテストしてみましょう。(ちなみに、顔面のアップでもイラスト調のキャラクターの顔をLandmarkすることはできませんでした。残念)
{kind=link}
プリプロセッサは「openpose full」のままでもOKですが、「openpose face」や「openpose face only」を選べば、顔のみの抽出をすることが可能です。上のスクショは「face」なので目や耳の位置を示すラインが出ていますが、「face only」の方を選ぶと…
{kind=link}
このように、FaceLandmarkのみの機能を試すことができます。
こちらも「1girl,open mouth, smile」で生成すると…
{kind=link}
怖いわ~~~!
でも、上手に表情を抽出することができました。イラスト調だと心臓に悪い。
変な話ですが、自分の表情をその場で撮影して元画像として送っちゃえばいろんな表情ランドマークが試せそうですね。
ガイダンス終了は「1」でもいいのですが、おおむね表情=構図ができればステップの最後まで効かせる必要はないので、崩壊するようなら0.5前後に弱めるのも手です。または、controlnetの「重み」を弱めるとよい結果になることがあります。
次は横向きの表情で試してみましょう。
{kind=link}
せっかくなので、今度はLoRAを効かせます。
かぐや様LoRAを0.5の重みで掛けて、「ガイダンス終了:0.5」で生成してみましょう。ちなみにプロンプトは「kaguya shinomiya,solo,1girl,white background,delicate eyes, red_ribbon,black_hair,folded_ponytail, hair_ribbon,deep red eyess,bangs, sidelocks,bare forehead,(high resolution,masterpiece,best quality,extremely detailed CG,official art,:1.3) 」です。
{kind=link}
はい素晴らしい!顔立ちのかぐや様っぽさは少々薄いですが、顔の向きはしっかり保存することができました。
新モデル「Lineart Anime」で線画を抜き出そう!
次に試すのは新モデル「Lineart anime」。「Line art」というモデルもあり、いずれも画像を線画として抽出するモデルなのですが、「anime」の方は特にアニメ調の画像でトレーニングされたモデルとのこと。Lineartモデルと比べ、長いプロンプトとClipskip:2を使ってトレーニングされているため、LoRAを使わない限りプロンプトが長くなるほど良い結果になるとのこと。
元画像から線画を抜き出して、それを塗ってくれる(正確にはその線画を強く意識して新たなカラーイラストを生み出す)わけですから、線画を抽出しないで手描きの線画を渡しても同じことができるわけです。つまり旧Cannyと同様、手描き線画からカラーイラストを生み出してくれるモデルということで、実用度高そうなムードにぐっと期待度が高まります。
まずは線画から塗ってもらう前に、既存イラストからの主線抽出がうまくできるかを試してみましょう。
こちらのメイドさん二人組のイラストを主線抽出します。
{kind=link}
プリプロセッサはlineart anime、モデルも同様。ガイダンス終了は0.6で試してみました。プレビューでは旧Cannyと同様、しっかり主線が抜き出せているように見えます。その結果がこちら。
{kind=link}
おお~、主線がしっかり抜けていますね!
ちょっと絵柄が暗くなりましたが、とくに線がない部分をよく補ってくれているのがよくわかる出来です。色合いがseed値由来のものなのかまだよくわかっていないのですが、Controlnetの重みを「1」から「0.7」に弱めたところ…
{kind=link}
このように、鈍重な色合いはやや軽減することができました。単なるSeed値の巡り合わせで暗い色になっただけかもしれませんが、このあたり、いろいろ試していきたいですね。
とか言っている間にはい、いま午前3時!迫る出社時間!まいていきますよ!
「Lineart anime」で線画は塗れるか?
以前こちらの記事では、cannyを使って線画に色塗りをする実験を行いました。今回は新モデル「Lineart anime」を使って、線画着色ができるかどうかを試してみます。
AIを使って「線画に色塗り」をしてもらおう!

こんばんは、スタジオ真榊です。今夜はこちらのツリーでも紹介した、線画を使ったAIイラスト生成についての記事です!線画にAIで着色するために必要ないろいろなTIPSや、controlnetの各種設定の方法、線画をできるだけそのままにしながらリッチにスケールアップする方法など、実用的な技術について解説できればと思いま...
使用するのは今回もこちらのイラスト。こちらはNovelAI由来(もちろんリークモデルではなく課金して生成したもの)のイラストを線画LoRAでわざわざ線画化したものなので、線画を書いたのと全く同じモデル・プロンプト・Seed値を使った「あたかも線画から塗っているかのように見せて、実はLORAで線画化する前のイラストをseed指定で生成しているだけ」というインチキができないからです。
{kind=link}
とりあえずこちらの設定で、下記のプロンプトを使って生成しましょう。LoRAありです。
school,classroom,selious,kaguya shinomiya,solo,1girl,white background,delicate eyes, red_ribbon,black_hair,folded_ponytail, hair_ribbon,deep red eyess,bangs, sidelocks,bare forehead,(high resolution,masterpiece,best quality,extremely detailed CG,official art,:1.3)
{kind=link}
こんな感じに着色されました。ロングヘアと誤認識してしまった1枚もありますが、上々な出来ではないでしょうか。ちなみに、プリプロセッサを「なし」にして線画そのままで認識させた場合、次のようなものが生成されました。
いろいろとこのあたり試しがいがありそうですが、いよいよAIも線画着色に慣れてきた感じがしますね!
{kind=link}
「イラスト→線画化→再び色塗り」を一工程で試す
今度は、さきほど生成したかぐや様イラストのうち一枚を元画像にして、線画化と再色塗りを一工程でできるか試してみます。また、Lineart animeの線画化がプリプロセッサの解像度でどう変わるかも違いが分かるように、使用checkpointを別のものに変えた上でXYZプロットで実験してみましょう。
{kind=link}
元画像はこちら。preprocessor resolusionを200~2000に変化させて違いを比べたところ…
{kind=link}
このような結果となりました。拡大していただくと、200、400くらいまではどちらかというと学習モデル(checkpoint)の絵柄が優先されているように見えますが、600以降は線画を強く意識して、それに沿った形で塗っている印象があります。(さほど違いが見られなくなる)
ところで、抽出された線画は元画像にしっかり重なっているのでしょうか?「1000」で出来たイラストと、前処理で抜き出した線をクリスタで重ねようとしたところ、不可解なことが分かりました。入力した元画像は768✕1152pixなのですが、プリプロセッサで抜き出された上の黒い線画が、なぜかアスペクト比の異なる1024✕1472pixelで出力されているのです。当然、重ねようとしても線が重なりませんね。
これは、解像度が64の倍数に直されるのが理由の模様。「解像度1000」と指定すると、短径1000が64の倍数でないため、勝手に1024に直され、対応する長径との関係もおかしくなるようです。素直にプリプロセッサ解像度を「768pixel」に指定すると、出力される線画も入力元と同じ768✕1152pixになりました。
線画を生成したイラストに重ねると…
{kind=link}
ビタっと重なりました。右画像はわかりやすいよう、線画部分を虹色に光らせていますが、勝手に学習モデルが主線を動かすことはなく、あくまでその線を守って塗っていることが分かると思います。
線画を抜き出すことができているということは、色トレスができるということ。
{kind=link}
(左)生成したままの元画像
(中央)Lineart animeに抜いてもらった線画を白黒反転した上で、元画像を使って色トレスした線画
(右)元画像の上に色トレス線画を載せたもの
これは機械的に処理しただけのやっつけですが、細部をきちんと調整すればもっと上手になると思います。
* * *
そんなわけで、さすがにもう時間切れなので、本日はここまで。5分でサムネを作ってUPして8分で寝ます!
それでは皆様、よきコントロールライフを!都内某所午前3時18分のスタジオ真榊からお届けしました。
Files