Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

「Mixture of Diffusers」でストーリー性のあるイラストを生成しよう (Pixiv Fanbox)
Content
「AIイラスト術 天下一武道会」エントリー作品
寄稿者:Shingo.playさん
一人の女の子を可愛く描けるようになった、一つのオブジェクトをカッコよく描けるようになった。
では次は、複数の人物を登場させてみよう、と思ったことが皆さんあると思います。
しかし、人物やオブジェクトを複数登場させようとして直ぐに発生するのが属性の混在。
髪の色の指定が混じってしまったり、男性と女性、先生と生徒、母親と娘といった、性別、年代、衣装といった異なった属性で描き分けたいのに、それらが混じりあってしまう。
これは誰しも経験があると思います。
或いは、それ以前に誰・何を、どこに登場させるか?これ自体、プロンプトで表現することがなかなか困難です。
この現象を回避し、コントロールするために「Latent Couple」「cutoff」など、色々なExtensionが開発されてきました。
今回、ご紹介するのは、これらとは異なるアプローチである「Mixture of Diffusers」及び、それを分かりやすいUIでコントロールできる「multidiffusion-upscaler-for-automatic1111」を利用する方法になります。
「Mixture of Diffusers」によるサンプル
論より証拠ということで、ここで異なった属性を混在させて生成させたイラストの例を見てみましょう。
{kind=link}
サンプル1:こちらを向くタキシード姿の男性の全身像と、こちらを振り返り見る制服姿の女生徒の上半身
{kind=link}
サンプル2:少し引いた位置に立つ女性教師と、抱き合う女生徒たち
{kind=link}
サンプル3: カジュアルウェアを着た母親の上半身と、走り回る子供たち
{kind=link}
サンプル4: 中央に女性、何か不可思議な力が働いた印象の背景、上部に女性と同じ色の禍々しい瞳
「Mixture of Diffusers」が、「Latent Couple」や「cutoff」といった方法と大きく異なるのは、(名前の通りですが)複数の生成処理(Diffuser)を別々に動かし、それをミックス(Mixture)させる点にあります。
そもそも「属性の混在」が何故起きるのか?それは一つの生成処理の中で、複数の属性を取り扱おうとするためです。
そこで 「Mixture of Diffusers」では、それらを別々の生成処理で独立してプロンプトを取り扱おうという発想に至ったそうです。
Photoshopなどの「レイヤー管理」が出来る画像編集ソフトをお使いの方は、各レイヤーで個別にプロンプトを実行させることができ、それらを適切に重ね合わせて一枚のイラストを作る、と考えるとイメージしやすいと思います。
しかし「mixture-of-diffusers」の元々の実装は、指定が複雑で簡単に扱えるものではありません。
そこで登場するのが「multidiffusion-upscaler-for-automatic1111」」に追加された分かりやすいUI。
元々は(名前の通り)アップスケーラー、若しくは巨大なイラストを生成するExtensionとして認知されていますが、比較的最近のアップデートで「mixture-of-diffusers」の実装を取り込み、同時にコントロールしやすいUIが導入されました。
上記の画像も、キャンバスをリージョンに分けて配置し、各リージョンごとに衣装やアングル、アクションを指定して生成したものになります。
Extensionsの準備
導入するのは「multidiffusion-upscaler-for-automatic1111」のみです。
「mixture-of-diffusers」自体は multidiffusion-upscalerに組み込まれているため個別に導入する必要はありません。
以下のURLを、SD-webuiの「Extensions」タブから「Install from URL」で導入し、SD-webuiを読み込みなおします。
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
{kind=link}
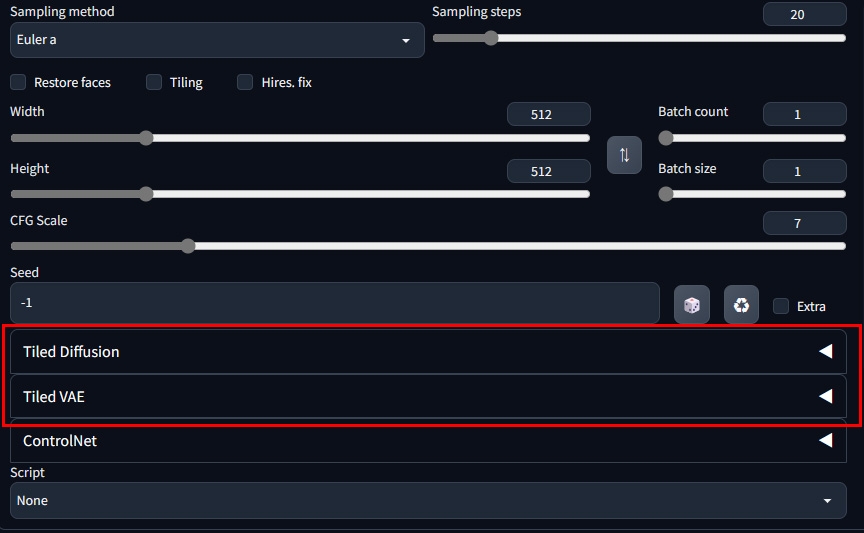
導入出来た場合は、txt2imgの基本設定項目の下に「Tiled Diffusion」「Tiled VAE」という項目が追加されます
使い方
チェックポイント、VAEなどは、お好みのものを設定してください。
プロンプト:「masterpiece, best quality, highres, extremely clear 8k wallpaper」といった、クォリティ設定のみ記載します
ネガティブプロンプト:「ng_deepnegative_v1_75t, EasyNegative,」といった、クォリティ設定のみを記載します。
multidiffusion-upscalerのGitHubのサンプルでは、プロンプトに背景に関して記述していますが、私の環境では生成が収束せず、他のリージョンに悪影響が出ました。
今後のアップデートにより解消するかもしれませんが、いずれもクォリティ設定のみとして、具体的なオブジェクトの記述は避けた方が無難です。
(背景に何を描くかについては、後述の「Background」リージョンでプロンプトを記述します)
サンプリングメソッド、サンプリングステップ数も任意ですが、通常のキャンバスサイズの場合より生成が収束しにくい印象があります。
私はステップ数は少し多め(普段 20step程度で収束するサンプラーなら、26~30step程度)としています。
解像度に関しても任意ですが、大きすぎるとVRAM容量が足りなくなる場合があるので、ご使用の環境に合わせて768×512といった普段お使いの解像度を設定してください。
Hires. fixも任意ですが、一点、注意点があります。
同一Seed値、メインのプロンプト、各リージョンのプロンプトを全て同じにした場合でも、リージョンの位置やサイズを変えてしまうと、異なる生成結果になってしまいます。
ですので、Hires.fix無しでお試し生成し、気に入ったものを同一Seed値でHires.fixありで仕上げ、というプロセスで作成をされている方は、リージョンの情報(位置、サイズ)も変えずにHires.fixをかけてください。
基本設定は以上で、続いて「multidiffusion-upscaler」内の設定を行います。
「Extensionの準備」で追加された項目「Tiled Diffusion」を、右端の三角形をクリックして展開すると以下の項目が現れます。
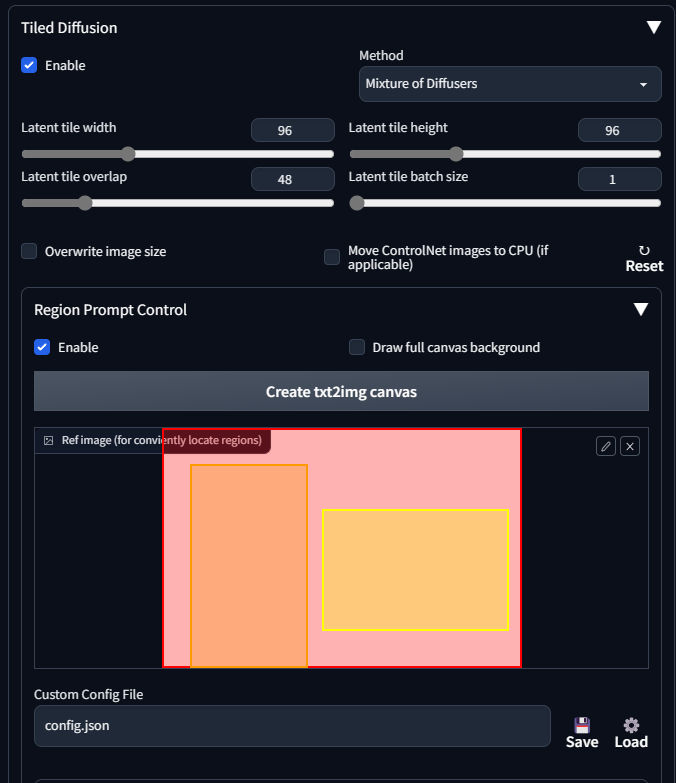{kind=link}
「Tiled Diffusion」「Region Prompt Control」を展開した様子
まず「Tiled Diffusion」の「Enable」をチェックし有効化します。
続いて「Method」を「MultiDiffusion」から「Mixture of Diffusers」に変更します。
「MultiDiffusion」のままでも印象の違う結果になるのですが、今回の本題から外れるので割愛します。
タイルサイズなどのパラメータは、GitHubのREADME.meを読むと、下記の「Region Prompt Control」を有効にした場合は無視されるそうなので、そのままとします。
続いて、リージョンごとの設定です。
まず「Region Prompt Contro」の「Enable」をチェックし、「Create txt2img canvas」ボタンを押下すると、基本設定の解像度と同じサイズの白地のキャンバスが描画されます。
{kind=link}
なお白地のキャンバスの代わりに参考画像を下書きとして挿入することもできます。
続いて、その下の「Region 1」~「Region 8」を展開していくと、それぞれに「Enable」のチェックボックスがあるので、必要なリージョンの分だけチェックを入れます。
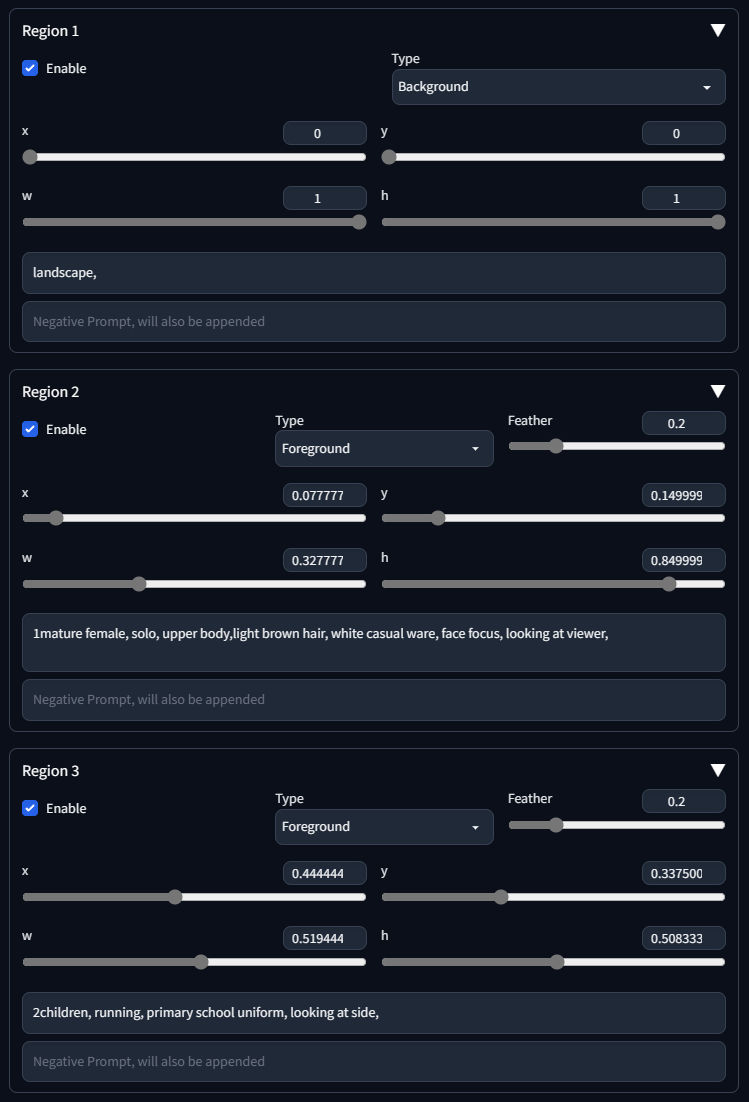{kind=link}
チェックを入れると、キャンバスにリージョンを示す四角形が追加されていきます
ここからは、自分のイメージに従ってリージョンを配置していきます。
個人的にお勧めの設定の仕方としては、
リージョン1に、「Type」が「Background」のリージョンを1つ作成し、ドラッグして調整してキャンバス全域を覆います(x:0,y:0,w:1,h:1)
そして「Prompt」には、文字通り背景(Background)を描画するプロンプトを記述します。
例:landscape、modern livingroom、school hallwayなどなど
リージョン2以降は、「Type」を「Foreground」に設定し、人物などを配置したい位置に、同様にドラッグしてリージョン位置を調整します。
そして「Prompt」には、そこに登場させたい人物やオブジェクトのプロンプトを記述します
例:1mature female, solo, upper body, light brown hair, white casual ware, face focus, looking at viewer,
例:2children, running, primary school uniform, looking at side,
ここまで準備が出来たら、後は通常通り「Generate」ボタンで生成処理を開始します。
通常の生成処理と比べて、複数の生成処理が動くため、通常のキャンバスサイズ分+各リージョンの面積分の処理量となります。
応用編 その1 リージョンごとに別々のLoraを適用する
繰り返しになりますが、各リージョンは個別に生成処理が行われるため、リージョンごとに別々のLora、Textual Inversionが利用できます。
適用の仕方は、通常のプロンプトに記述する場合と一緒で、の呼び出し記述と、TriggerWordsを各リージョンのプロンプトに記載します。
{kind=link}
極端な例ですが、背景に光のパーティクルを追加するLoraを、子供たちをモノクロで描画するLoraを適用してみたサンプルです
{kind=link}
背景のリージョンにのみ強い光のエフェクトを加えるLoraを適用しており、手前の女性はLoraの影響を受けていません
{kind=link}
参考として、リージョンを分けず、全体に強い光のエフェクトを加えるLoraを適用した例です。
メインのプロンプトに、個別のリージョンに記載した内容をまとめて生成した場合で、これはこれで素敵なのですが、明らかに手前の女性の印象が変わってしまっています。
応用編 その2 リージョンの境界をぼかさず、コマ割り風にする
リージョンがType:Foregroundの場合、「Feather」という設定項目が登場します。
これは他のリージョンとのミックスする際の「ぼかし具合」を意味しており、通常はデフォルトの0.2程度で良いと思います。
ですが、例えばクッキリとコマ割りする構成としたい場合は、0.0としても面白い効果が得られます。
{kind=link}
これまでの例と比べて、左側の女性のリージョンの輪郭がクッキリ描画されています
まとめ
いかがだったでしょうか。
「Mixture of Diffusers」についておさらいすると、一番の特徴はリージョンごとに別々の生成処理を動かせることです。
それにより、これまで常に付いて回ってきたプロンプト間の干渉が無くなり、自由に人物やオブジェクトを配置でき、一枚のイラストでは表現しづらい、コマ割り的配置による動きや連続性、ストーリー性といったものを表現できるようになります。
また、これは個人的な感覚になるのですが、プロンプトは可能な限りシンプルに記述した方が、生成されるイラストのクオリティは高まる印象があります。
しかし、複雑なシチュエーションを表現しようとすると、自然とプロンプトの記述も複雑になってしまいます。
そこで「mixture-of-diffusers」の場合、リージョンを分けることで、同じイラストを生成しようとしたとしても「背景のプロンプト」「人物のプロンプト」「オブジェクトのプロンプト」といった形で、一つ一つの生成処理のプロンプトをシンプルに記述することができます。
(プロンプトが複雑になると、記述している自分自身が混乱することがあるので、そこもスッキリさせられますね)
最後にメリット・デメリット、注意点は以下の通りとなります。
メリット:
グラフィカルなリージョン配置により、キャンバス上の好きな位置に好きなオブジェクトを生成できる
複数の生成処理が独立して動くため、各プロンプト間で影響(色移り、属性の混在)を及ぼしあわない
複数の生成処理が独立して動くため、各リージョンに異なったLora、Textual Inversionが適用できる
デメリット:
キャンバス1つ分の生成処理に加えて、各リージョンの面積分を合計した生成処理量になる
注意点:
執筆時点のバージョンでは、各リージョンに記載したプロンプトがPNGファイルに保存されません
リージョンの位置、サイズを変更すると生成結果が変わります。
各リージョンは同一のSeed値を参照しているようなので、「同一の生成結果を作りたい」「Hires.fixを後からかけたい」といった場合は、Seed値、プロンプト、リージョンの位置・サイズが、初回生成時と同一になるように設定してください。
最後に
色々なシチュエーションを生成したい、そのためには色々な属性をプロンプトで表現したい、しかし、そうすると属性が混じりあってしまう。
そのためAI生成のイラストは、非常に描きこまれた少人数(多くは一人)と、同じく非常に描きこまれた背景の組み合わせという構図が多いように感じます。
そこで登場した「Mixture of Diffusers」
個人的には「ControlNet」と同レベルの衝撃を受けました。
ControlNetは、一つの作品を作り込むには、強力な武器になるものの、一部、概念の理解や仕込みが大変だったりするので、導入に手をこまねいている方もいらっしゃると思います。
しかし、「Mixture of Diffusers」と「multidiffusion-upscaler」は、いったんプロンプトでイラスト生成が出来るようになりさえすれば、後は大雑把なレイアウトはグラフィカルに指定できるため、比較的、導入・実践に際しての敷居は低いのではないかなと思っています。
これにより、もっと様々なアイデアに溢れたAI生成イラストが生まれることを期待します。
参考情報
・checkpoint情報
今回の作例は、Meina様による「MeinaMix V8」を使用して作成しています。
癖の少ない、非常に使いやすいチェックポイントとして、お気に入りです。
・「Mixture of Diffusers」を使用した筆者の関連Tweet
「Mixture of Diffusers」による「挟まれシチュ」の再現実験
「Mixture of Diffusers」+「ControlNet - canny」による、タッチの馴染ませ
(実装初期のころは、Hires.fixを行うとエラーが発生したため、このようなアプローチを考えてみました。現在は、あえてこの方法を使う必要はないと思います)
リージョン別Lora適用実験
作例と考察
リージョン指定と、その結果
リアル系チェックポイントに適用した例(髪の隙間から見える背景や、山あいに沿って見える鎖骨のラインが見所です)
「from below」視点で見上げた女生と「from above」視点で見下ろした男性を同一イラスト内に混在させた例
{kind=link}
▽該当ツイート
・「Mixture of Diffusers」を使用した筆者のPixiv作品投稿(R-18注意)
「先生なら。。。(Mixture of Diffusers)」
「授業風景 性技実習(Mixture of Diffusers)」
・執筆時点の筆者の実行環境
python: 3.10.6 • torch: 2.0.0+cu118 • xformers: N/A • gradio: 3.23.0 • commit: 22bcc7be • checkpoint: 30953ab0de
・執筆時点のmultidiffusion-upscaler-for-automatic1111のバージョン
0d74030d (Thu Mar 30 11:45:45 2023)
・【GitHub:mixture-of-diffusers】
(おわり)
天下一武道会の応募作品
キャラ・ポーズだけじゃない! 表現力を加速するおすすめLoRA

「AIイラスト術 天下一武道会」エントリー作品 寄稿者:カガミカミ水鏡さん LoRAという追加学習データが広まって以来、特定のキャラを再現したり、色んなポーズや構図をさせたりするのによく使われていますね。 その中でも取り分け便利な使い方としては、「絵柄の変化」。 ここでは絵柄をより良いものに変化させる12個の...
【ワンボタンでプロンプト出力】オリジナルのプロンプトジェネレーターを作ろう

「AIイラスト術 天下一武道会」エントリー作品 寄稿者:nicさん こんにちは nicです。 プロンプトを逐一入力するのが手間に思う事は無いですか? 特に漫画を描きたい時など、沢山のキャラを出さなくてはならない時はプロンプト入力が手間に感じるかと思います。 WEBUIにもプロンプトを保存する機能はありますが少々不便...
Files