Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

新しく作った英語リスト「Ag」の制作過程 (Pixiv Fanbox)
Downloads
Content
ある日みなとは、
「ちょーーー簡単に英語音源が録りてぇな。」
こう思いました。
でもそういう録音リストがなかったので、
「じゃあなんか、簡単に、作るか。」
こう思いました。
// 前置き
ARPASingのリストは英語よわよわ勢には難しく、造語を3モーラも組み合わせて読まなければならなくて大変です。しかもARPASingの基本リスト(0.2.0のことです)は頻出している発音を重点にリストを構築しているので、完成した音源はCV(単独音)音素すら無い音が場合があります…!それを補完したリストもありますが、難読さはグレードアップ。かといって、発音ベースに重きをおいたX-SAMPA表記で音源を作ったことはありますが、こちらは過不足なく音源を構築でき、発音を正確に記述できる!…ところまでは良いものの、録音難易度・使用難易度、これらのどちらも全くもってユーザーに寄り添っていません。
じゃあその辺をどうにかした、日本人でも読めそうな英単語だけできたリストが欲しいよね?ってことでリストの構想を考えました。
御託はいいからリストが欲しい人
バージョン
2023/05/24 ver 0.4.5 リストを最適化 (530)
2023/05/16 ver 0.4.4 録音数を削減 (570)
2023/05/15 ver 0.4.3 録音数を削減 (617)
2023/05/12 ver 0.4.2 VV, CC音をある程度追加 (699)
2023/05/08 ver 0.4.1 初版 (595)
===== 以下このリストの経緯 =====
さて。
このリストはなんなの?
1.はじめに
4/26に、私はこういうことを考えていました
さすがに、英語がよわよわとは言えども、
例えば、「get」とか「go」とかくらいなら見れば読めます。
(とくに「go」はもうそのまま単独音っぽいですよね。)
そういった、「簡単な英語」というものが集まったものがないかな、と探していたら、ありました。
「ふむふむなるほど、この850個があればそもそもとりあえず「英語」っぽい音素の集まりが作れそうだぞ」と私は思いました。
そこで、英単語からARPASing用のindex.csv、oremo用のリスト、コメントファイルに変換できるウェブページを、ChatGPTにjavascriptコードをほとんど書いてもらいながら作りました。
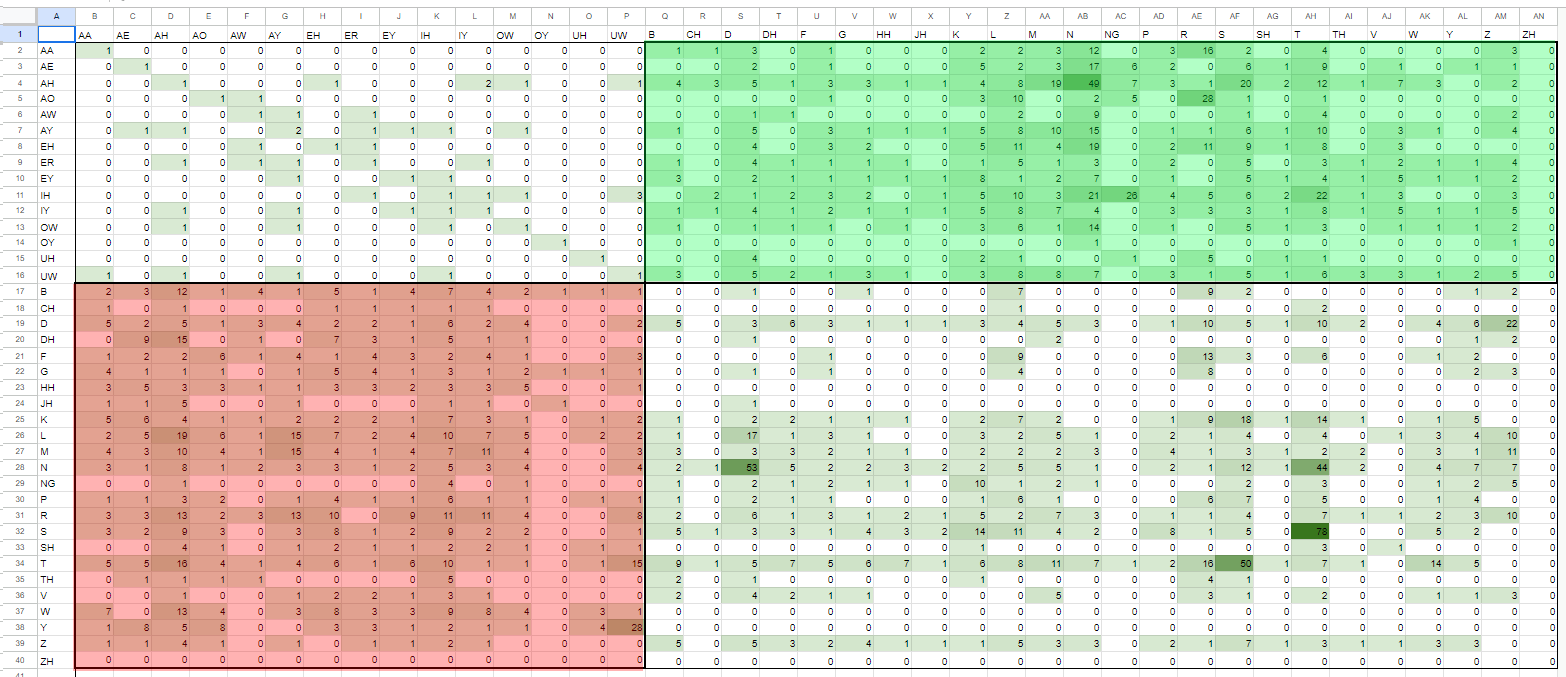
これで作成されたのがver0.1.0のリストになります。
上のベーシック英語をそのままリスト化しただけのリストです。
(2回繰り返していたり、母音だけの音素はさすがにあった方がいいかもとか勝手に思い追加で入れてますが、理由はなんとなく、です。)
2.次に
これでとりあえず録ってみてもよかったんですが、私はふと気になりました。
「…これってそもそもどれくらい発音が網羅されているんだろう…?」
そこで、index.csvから各音素の網羅度を表にしてくれるウェブページを、ChatGPTにjavascriptコードをほとんど書いてもらいながら作りました。
これをコピーしてスプレッドシートにコピペして…
・ver0.1.0のリスト
{kind=link}
こうじゃ!
そして気づいてしまったのであった―――
じつは、単独音としてすらも成り立っていない音源が出来上がるということに―――
でも同時にARPASingの方のリストの網羅度もチェックしてみて、
~~~参考:ARPASing(0.2.0)~~~
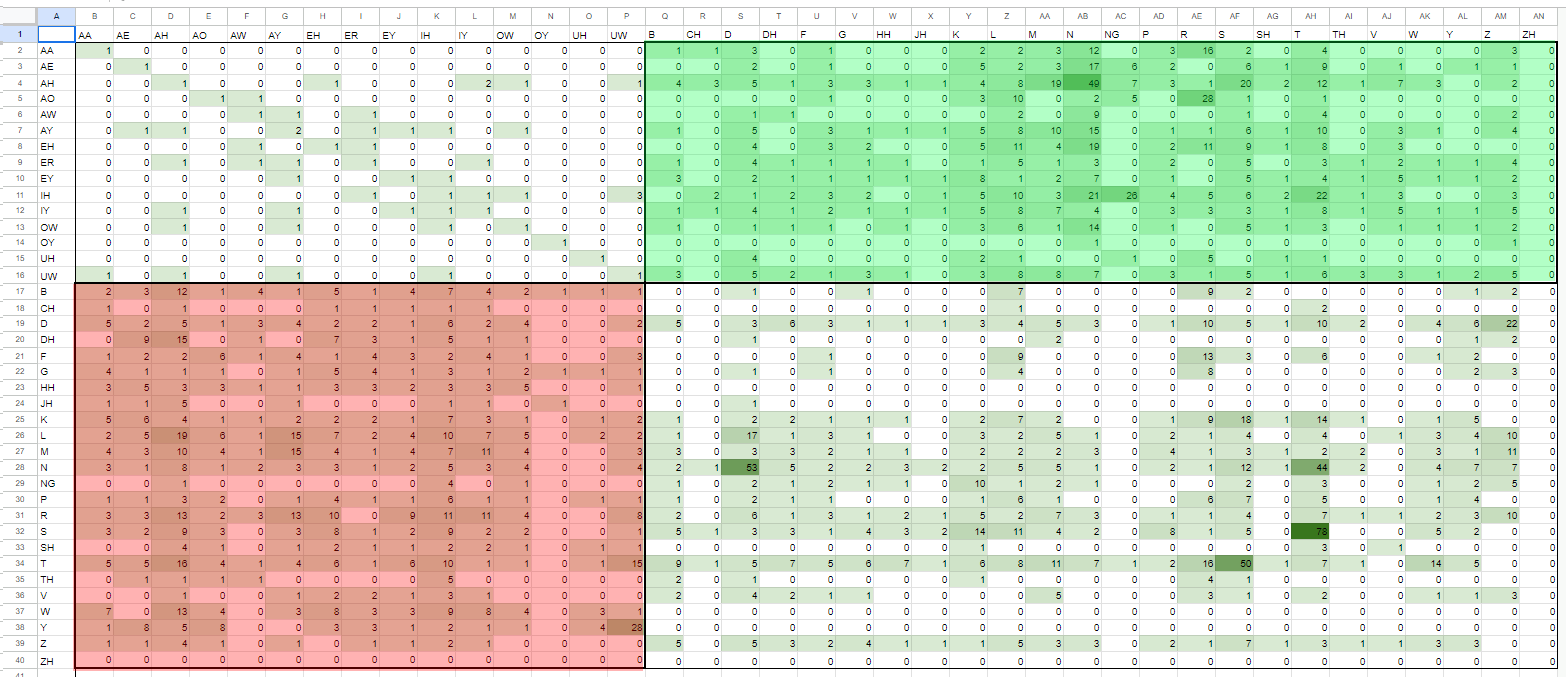{kind=link}
ぱっと見た感じのあんまり網羅度が変わらないことに、
まぁだいたい英語音源っていうのはこんな感じなのか。なるほどと思いました。
でも個人的に、単独音としてすら成り立ってないのは「UTAU音源」とはちょっと使いづらいなと思いました。
そもそも「例えば…CVの中だと一番左上の、「CH_AO」とかの発音が含まれる英単語って無いのかな?」と思いました。
なので、発音から英単語を一覧にしてくれるウェブページを、ChatGPTにjavascriptコードをほとんど書いてもらいながら作りました。
{kind=link}
ふっつーーーにありました。「chocolate」です。
これは普通に使いそうです。
表を見る限りARPASing0.2.0さんも発音できません。やばいね。
なのでそういった、CH_AO⇒chocolateや、CH_AW⇒chao
といった、単独音部分で不足している英単語を全部埋める感じで、一つずつ手動で独断と偏見の元に探しては、簡単そうな英単語をメモして80個集めました。
一つ目に因んでチョコレート単語リストです。
これをさっきまでのリストに加えたのがver0.2.0のリストになります。
(手動で集めてる関係で、実はちゃんと穴が埋められてないです。)
3.多くない?
でも私は思いました。
簡単な英単語が集まっているとはいえ、1音階の収録で900超えているのは、多くてめげます。やりたくNASA開発です。
そこで私は気づきました。「AH_N」の項目多すぎない??
204回(210回)も同じ音素を録っているようです。これでは差分と言えないほどさすがに録りすぎです。
そこで、網羅度から重複要素をチェックして最適化してくれそうなウェブページを、ChatGPTにjavascriptコードをほとんど書いてもらいながら作りました。
(最適化といっても重複をカウントしてオーダーしてるだけですが)
発音の観点からいうと、391単語も重複してるっぽいということがわかりました。
これで552個まで減らせそうです。
ただ、どの単語が余分かわかっただけなので、リストから要らない単語を抜いてくれるウェブページも、ChatGPTにjavascriptコードをほとんど書いてもらいながら作りました。
そうしてできたのがver0.3.0のリストです。
4.欠陥に気づく
ここまで出来て、私は喜んでいましたが、index.csvを確認してあることに気づきました。
埋めたはずの、CVの部分に 穴 が結構あります。
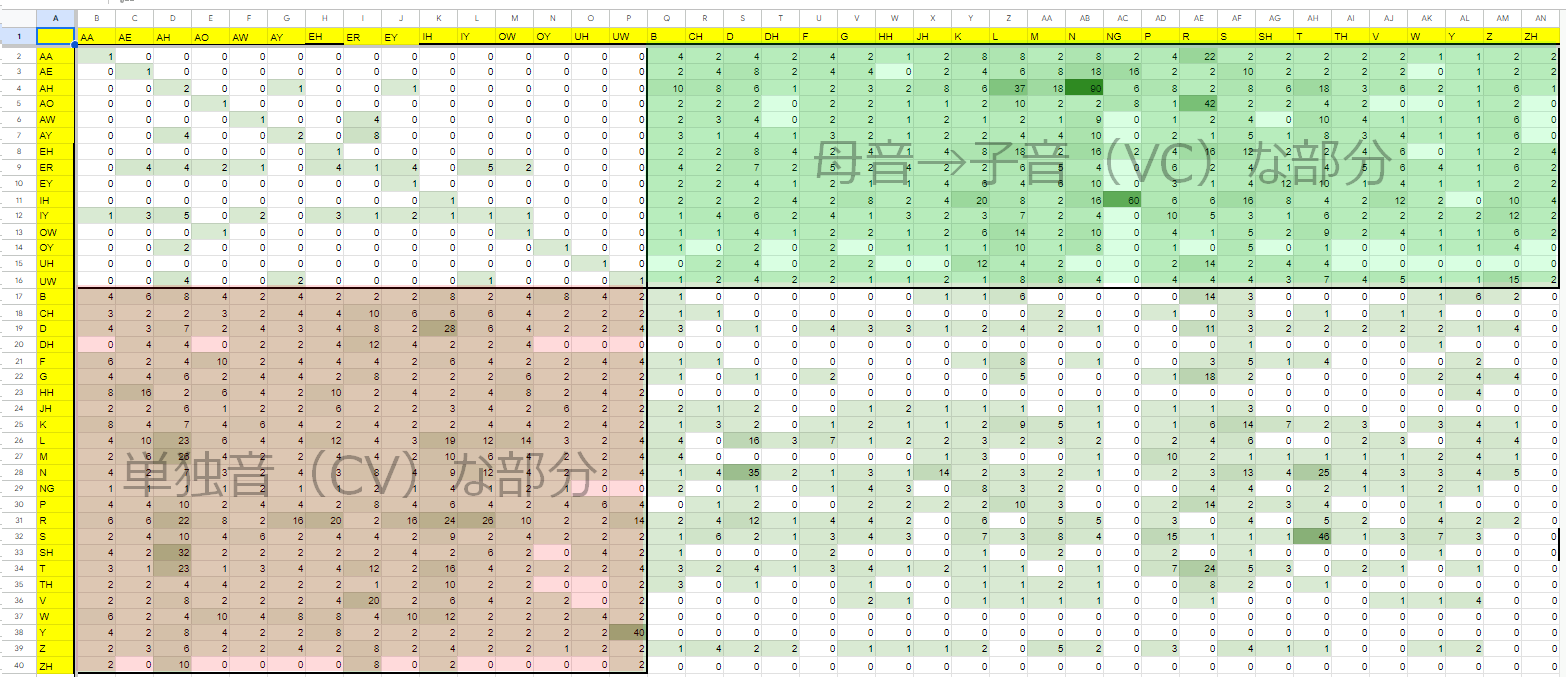
・ver0.3.0のリスト
{kind=link}
(自分が入れ忘れたミスもありましたが)
よくよく考えてみると、単純に上のページで削除対象を決めて削除すると、「6回以上登場した音素なので多いですね!削除しましょう!」というクソコードなので、
つまり、8回くらいのまぁまぁの低頻度登場していた音素がバッサリ全部削除されてしまう「最適化(笑)」コードということで、ひどく落ち込みました。
「その中から最低でも1個だけは残す」などの処理を思いつくのは簡単ですが、「じゃあどの英単語を優先して残すべきなのか?」「あるいは別な英単語を新たに追加した方がいいのではないか?」と疑問が浮かびますが、プログラミングもよわよわなので、さらに落ち込んでしまいました。
そこで、まぁ上でもやりましたが、
古代魔法《シュドウデヤッタホウガハヤインジャ》を使用することとして、空いてる穴を一つずつ手動で埋める作業でリストを形成していくということをまたやることにしました。
・埋めたやつ
{kind=link}
めちゃくちゃ時間がかかりましたが、ともかくリストに抜けている要素が埋まりました。
(これでもまだ空いてるCVやVC部分は固有名詞や、そもそも辞書に存在しない組み合わせになります。別々な英単語を組み合わせたら出現するかもしれませんが、今回の場合は考えていません。(無限にリストが難読化するので)
簡単な英単語の組み合わせでその穴が必要になった・埋められる場合は、是非教えてください。リストに追加します。今回の0.4.1が完全なリストとは思ってません。)
これらを一覧に追加したら……なるほど。645単語になりました。
この録音数は、ARPASingの倍くらいになってしまう感じですが、
ARPASingに比べて
・「簡単な英単語を読むだけで」
・「CVVCも揃っていて」
・「ARPASing形式をとっているので自動原音設定ができる」
そうです。私がなんでここまでARPASing形式にこだわっていたかというと、moresamplerで自動で原音設定ができるからです。
苦労して645個録って、そこから原音設定が待っている……というわけではありません。おおむね完成します。技術ってすばらしい。(主にSHIROが)
どちらかと言うと、ARPASing AssistantやOpenUTAUで楽に歌わせられるというところです。
(まぁ他の録音形式でも変換を噛ませればできなくはないですが、EL=5とかが再現できません。まぁそもそも上でも触れていましたが、発音ベースの録音が「簡単」じゃないところから発端になってますので)
そうしてできたのがver0.4.0のリストです。
4.1.最後?のひと押し
でも、英単語をリストに追加している関係上、やはり重複要素が増えてしまいます。
removerに通してみましたが、49単語最適化できそうです。
なので今度はver0.4.0の網羅度と見比べながら、無くなってしまっていない箇所がないか確認してから決定稿としましょう。
・ver0.4.0のリスト
・ver0.4.1のリスト
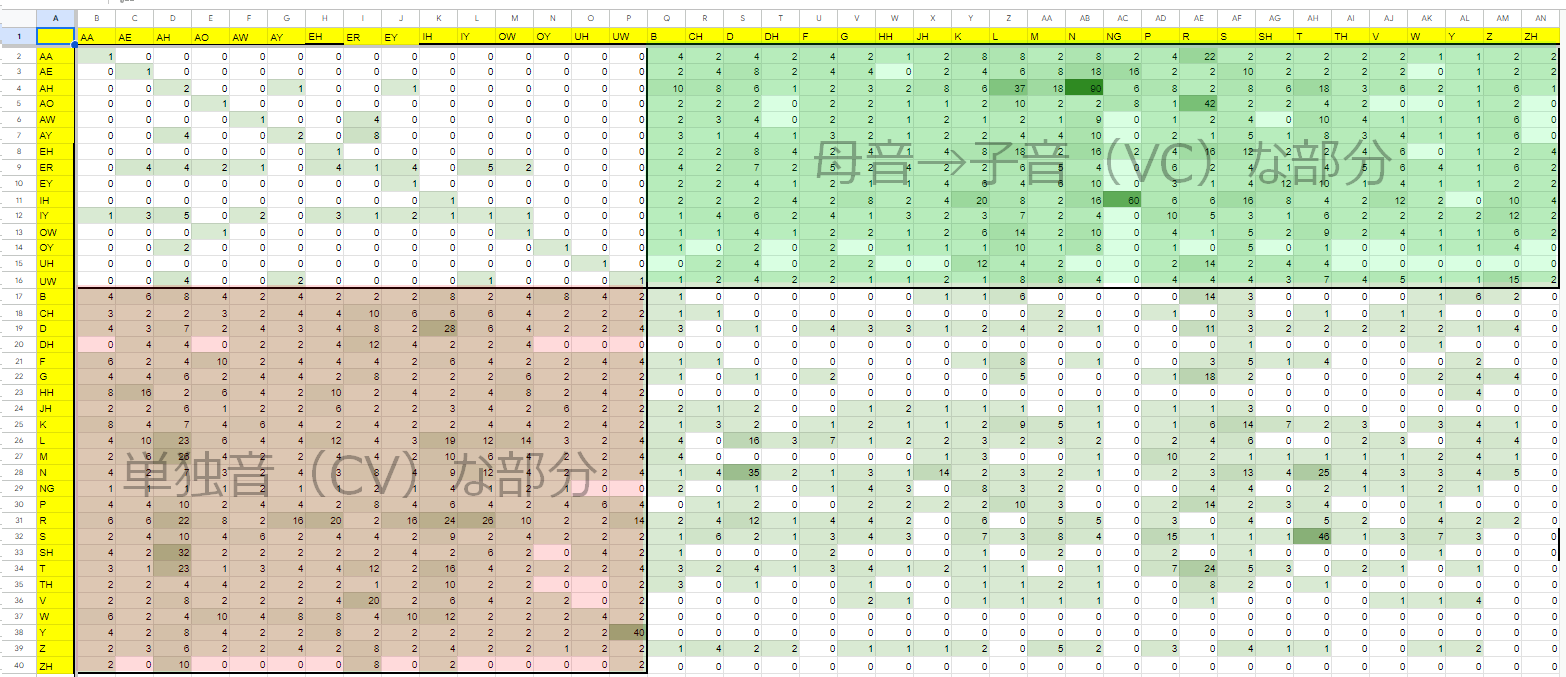{kind=link}
(CVの部分で入れ忘れていた単語も入れているのでちょっと埋まってます)
これにて決定!
最終的に、595語の英単語を録れば音源を作れる、という感じになりました。
いや~大変でした。
ここまで読んでくれてありがとうございました🙇♂
4.1.1.終わらなかった
「moresamplerで原音設定できるって言ったじゃろ?あれは嘘じゃ…」
いや嘘ではなかったんですが、moresamplerでできる自動原音設定機能だけが、別途ほんの少しだけ洗練されていたようで。それをWindows上で動かそうとすると、ちょっとめんどいらしくて。
動かし方自体はいくらかネットに載ってるんですが、そのままその話題がフェードアウトしてて、結局ポンって実行できるものがなかったので、Google Colaboratory上で動くようにコードを書きました。
まぁ、作ってはみましたが…実のところ、moresampler内蔵の自動原音設定機能と比較して違いは…あんまわかんないです。
(一応このノートでは右ブランクをマイナスで表記するようにしたりとか、機能を若干工夫したりとかしてますが、別にmoresampler製のものを変換できない訳ではないので…)
んま…、やっぱり自動原音設定だけではあんまりクオリティ出ないよねという実態でありました。テスト用としてバッと設定してくれるのはめちゃくちゃ楽です。
4.2.実録・使用に伴うフィードバック
さて、0.4.1で録音してみて。歌わせてみたところ、さっそく自分でも使いづらいと感じたところを感じたので、もう記事内でさっそくながら自分でアップデートです。
問題点1.意外と母音→母音が登場する
適当に「how are you doing」とか歌わせてみたところ、[hh aw][- aw]となってしまってしまいました。これは考えていなかった挙動です。
(とりわけ、自分が書いたcolabの自動設定では[aw]といった-VでもV-でもない、V単体の単独音の母音音素を作らないので余計にです)
でも、じゃあ結局英語って母音で始まったり終わったり単語ってそんなにあるのか?ということで
・まず、特定の母音で終わる音素があるのか調べてからスタートします
// 母音で終わる適当な単語の例
AA, africa AE1 F R AH0 K AA0
AE, yeah Y AE1
AH, eureka Y UH0 R IY1 K AH0
AO, caw K AO1
AW, allow AH0 L AW1
I, i AY1
EH, ke K EH1
ER, letter L EH1 T ER0
EY, anyway EH1 N IY0 W EY2
(IH, typology T AY2 P OW1 L AH0 G IH2)
DY, d D IY1
OW, ago AH0 G OW1
OY, boy B OY1
(UH, milieu M IH0 L Y UH1)
UW, bamboo B AE0 M B UW1
探してみたところ、一応全部ある感じですが、IHとUHはごく少数だったので追加オプションのリストとして録るくらいで良さそうでしょう。
・次に、特定の母音で始める音素
// 母音で始まる単語の例
AA, arch AA1 R CH
AE, avalon AE1 V AH0 L AA2 N
AH, abandon AH0 B AE1 N D AH0 N
AO, appeal AH0 P IY1 L
AW, ouch AW1 CH
AY, i AY1
EH, s EH1 S
ER, original ER0 IH1 JH AH0 N AH0 L
EY, abc EY1 B IY2 S IY2
IH, earphone IH1 R F OW2 N
IY, aegis IY1 JH AH0 S
OW, o OW1
OY, oiler OY1 L ER0
(UH, url(2) UH1 R L)
UW, oops UW1 P S
こちらでもUHはごく少数でした。基本的にUHはアクセントの無い間の音素に充てがわれることが多いので、基本的にUWになりがちで登場が少ない感じでしょうか。
これを収録できる一覧を適当に作成。
3モーラも正確に発音するのは大変…という場合の為に2モーラも用意。
問題点2.「tw」とか意外と使いそうなCCが無い。
簡単な英語の歌としてパッと挙げられそうな、きらきら星の「twinkle」が歌えません。なんてこったい。
とはいえ、CCを全て網羅するのは現実的ではありません。
(いえまぁ、不可能か可能かで言えば全然可能ですが、どちらかというと、録音しても使わない確率が高い音…例えば日本語の「ふゅ」とかを録っても、録音が少し大変になる一方で使用側に大きく左右されることはありません。それにまぁせっかくUTAU上でCCで"合成"ができるのですからね)
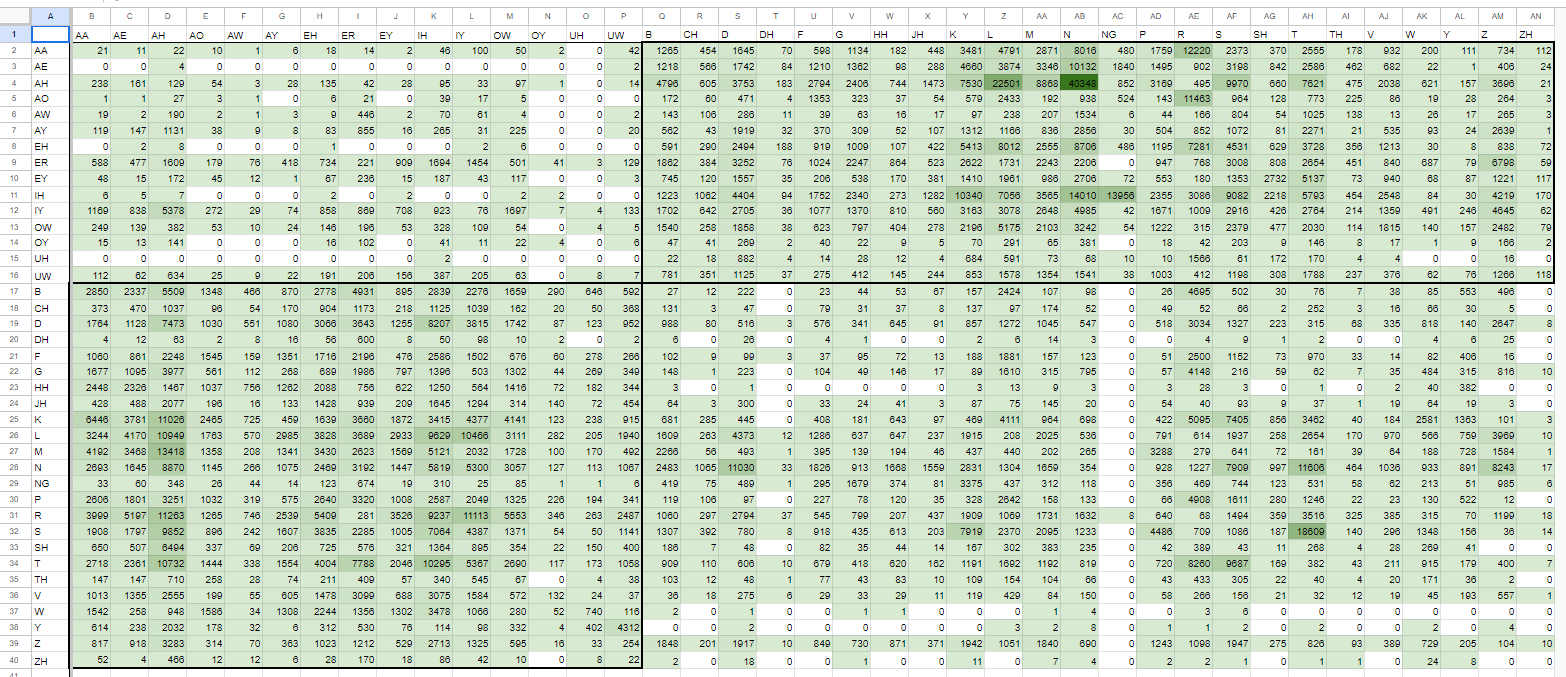
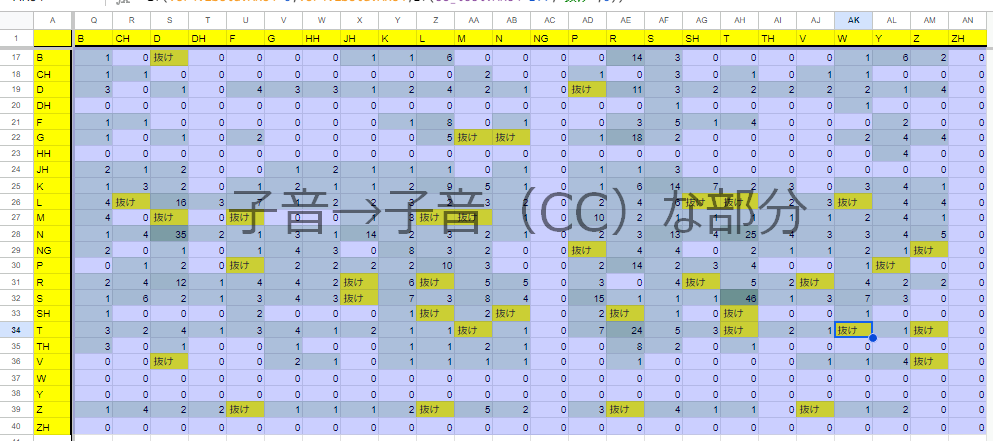
ひとまず、確率ベースで考えてみましょう。cmdict全体で網羅したとき高確率で登場しているが、今までで録音されていない音素を補完しようと試みます。
・これはcmdict全体での網羅度の図
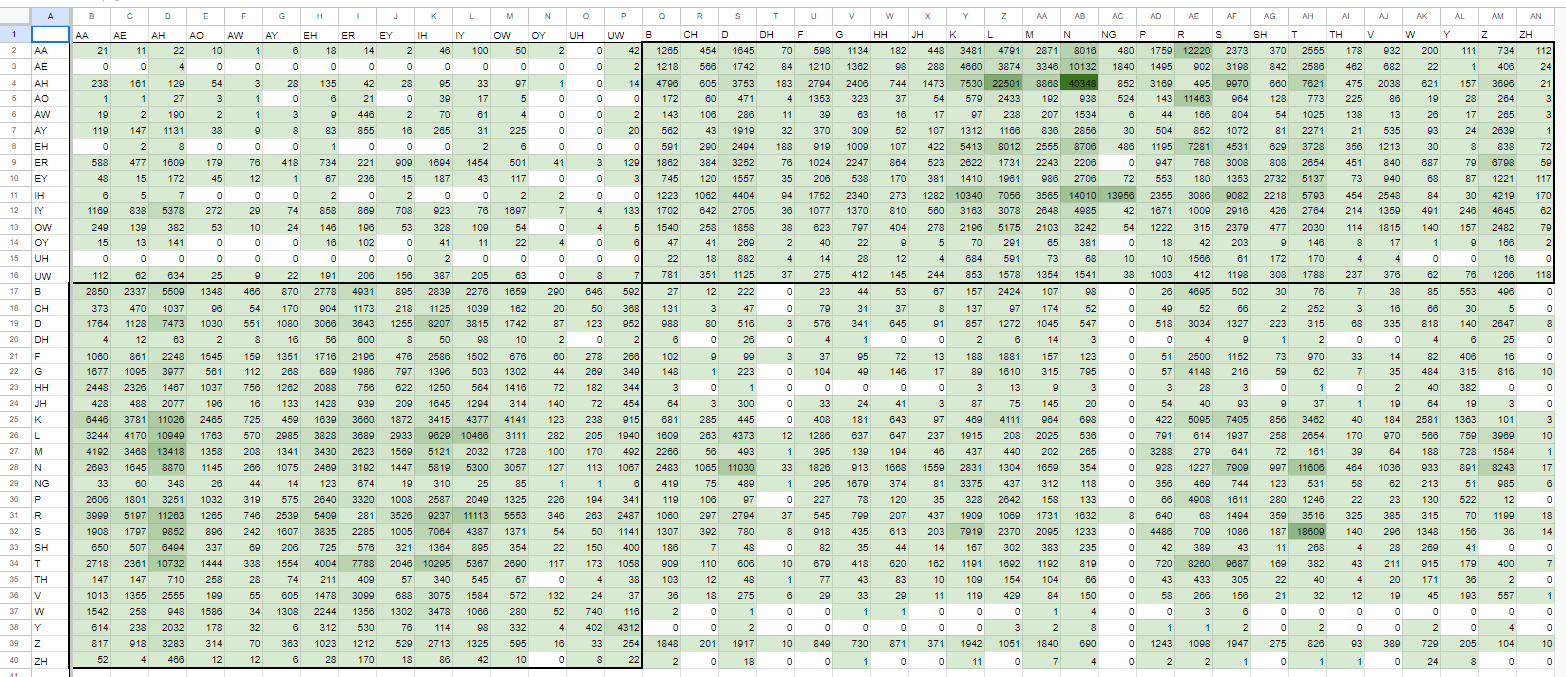{kind=link}
・これのCCをパーセンタイル75で絞ります
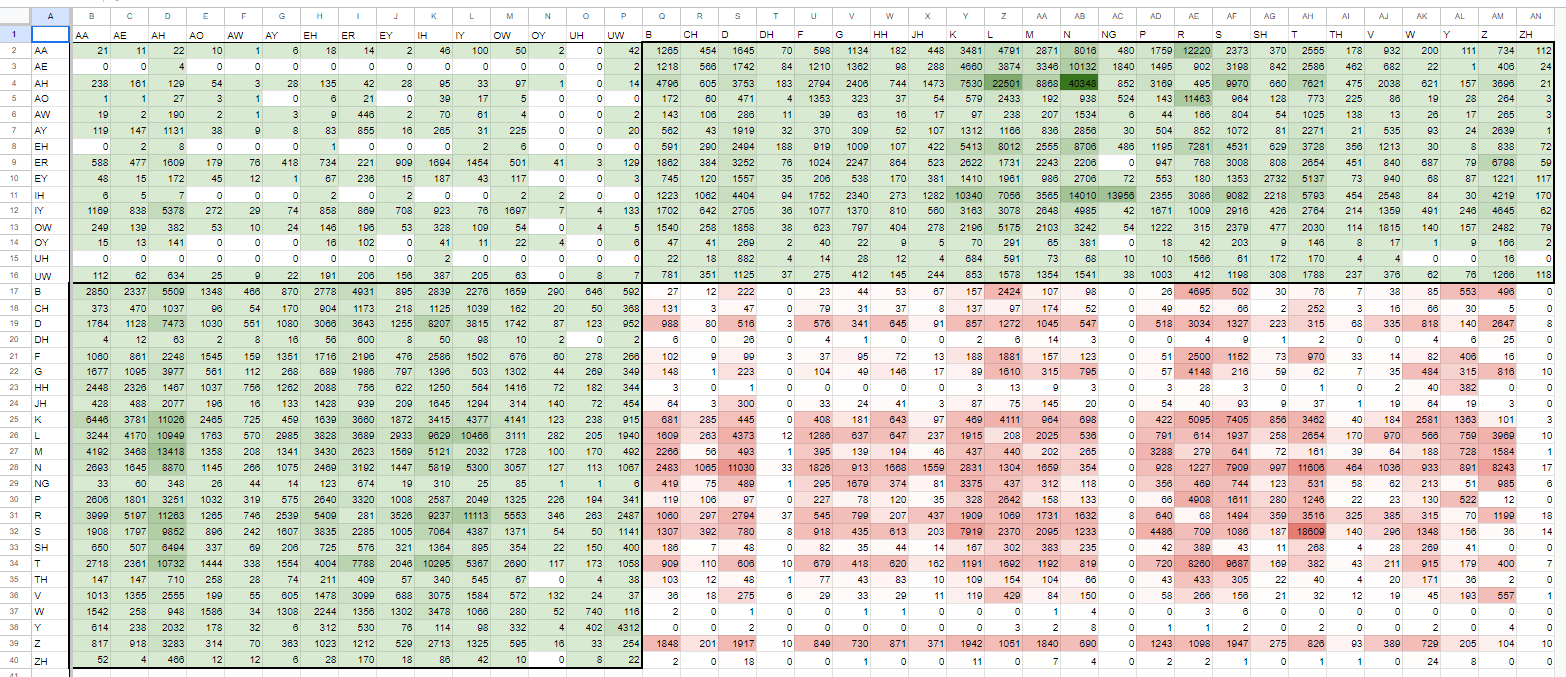{kind=link}
概ね100あたりで頻度に差が出ているように思えます。
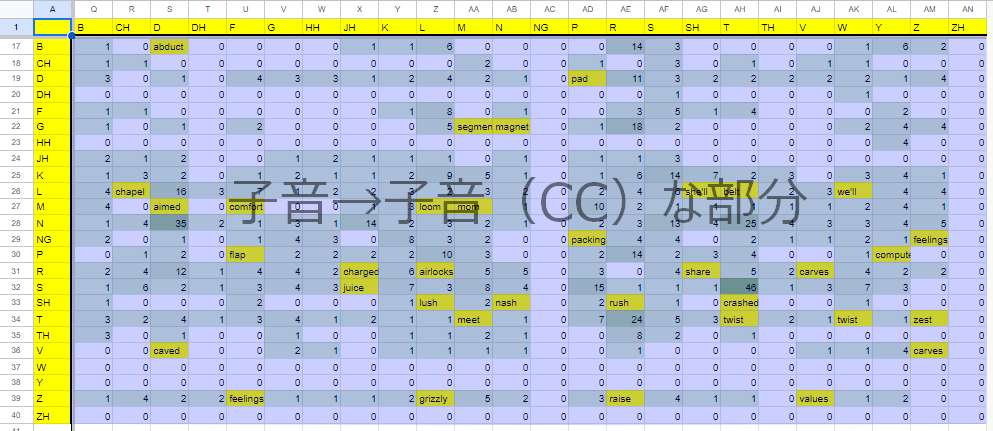
なので雑に200回以上のものを取り出して録ることとして、既に録っている箇所はそのままになるように、抜けている部分を明示化しました
・合体したシート
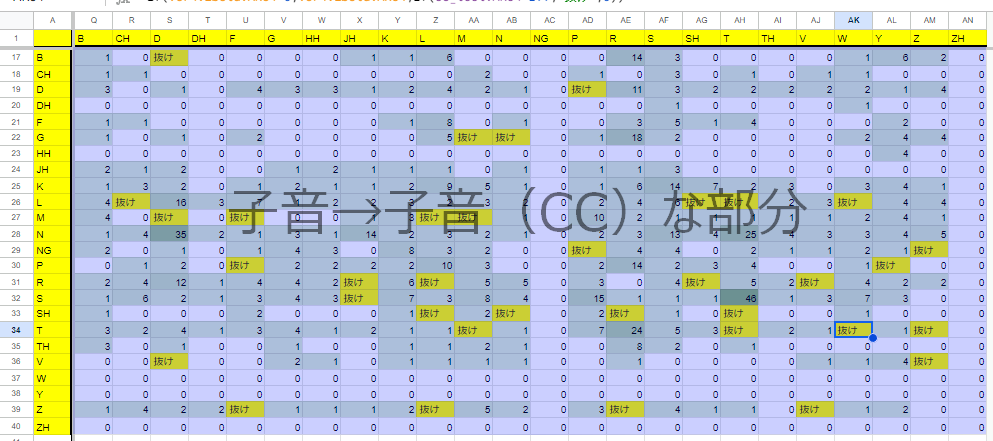{kind=link}
・埋めました
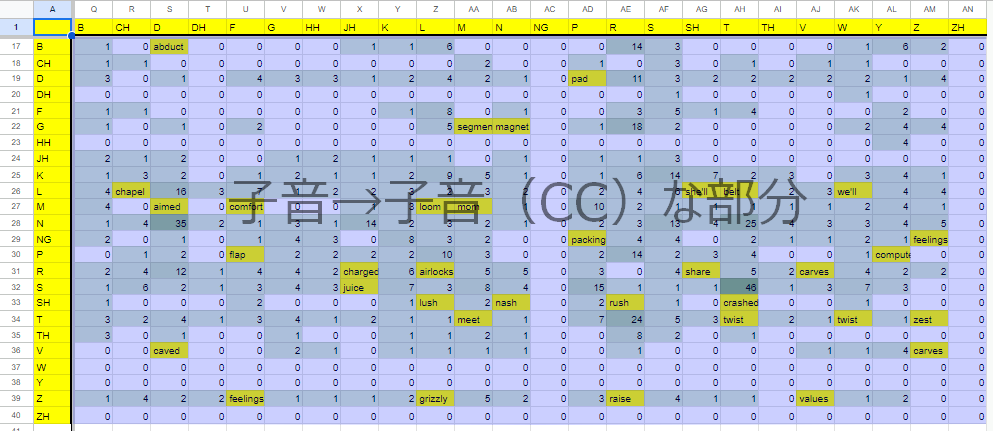{kind=link}
35個箇所あったところを32語の単語で埋めました。
これを足した上で、また無駄が発生するはずなので、checkerに通します。
[direction, past,ever, leg, self]が余計になったのでremoverで削除。
・ver0.4.2のリスト
これにて再決定…!
最終的に、699個の英単語を録れば音源を作れる、という感じになりました。
(VVを2モーラにした場合は増えます)
4.3.でもさ、音階数増やしたいよね
ここまでのリストで録った音源を、重複全部有りで出力するとだと5,000↑になって、3音階が限界かなぁ。という、なかなか厳しい音源だと思っていたんですが、
ふと、
重複なしでoto.iniを生成した場合に1音階分のエイリアス数がいくつになるのか出力(何音階までデフォルトでロードできるかに影響がある)してみたところ、1,212行、となって、なかなかなるほど。
重複を消せば、実は10音階くらい録っても問題なさそうです。
……ん?
あれ……?
そもそも、このoto.iniに含まれていない単語…あるよね…??
ということでそのoto.iniを処理して確認してみたところ、
なんか、617単語まで減ってます。
そしてチェックしてみても
・もちろん単語削減による穴抜け発生もない……
最適化()とはなんだったのか……()
そうかー()こうやって最小化すればよかったんやなー()
そういうわけで617個録ればいいことになりました。わー()
(まぁ実際のところとしては、アクセントの有り無しで発音傾向が変わる場合あるので、単に発音ベースに音素数を減らせばいいというものではありませんが、同じものを多く録りすぎるという必要もないですよね。)
4.4.貪欲に
さっきした、リストの「最適化」ですが、
これは、純粋に必要なエイリアスを、「前からの要素を拾っていって最大効率になる手法」といえます。⇒つまり貪欲法です。
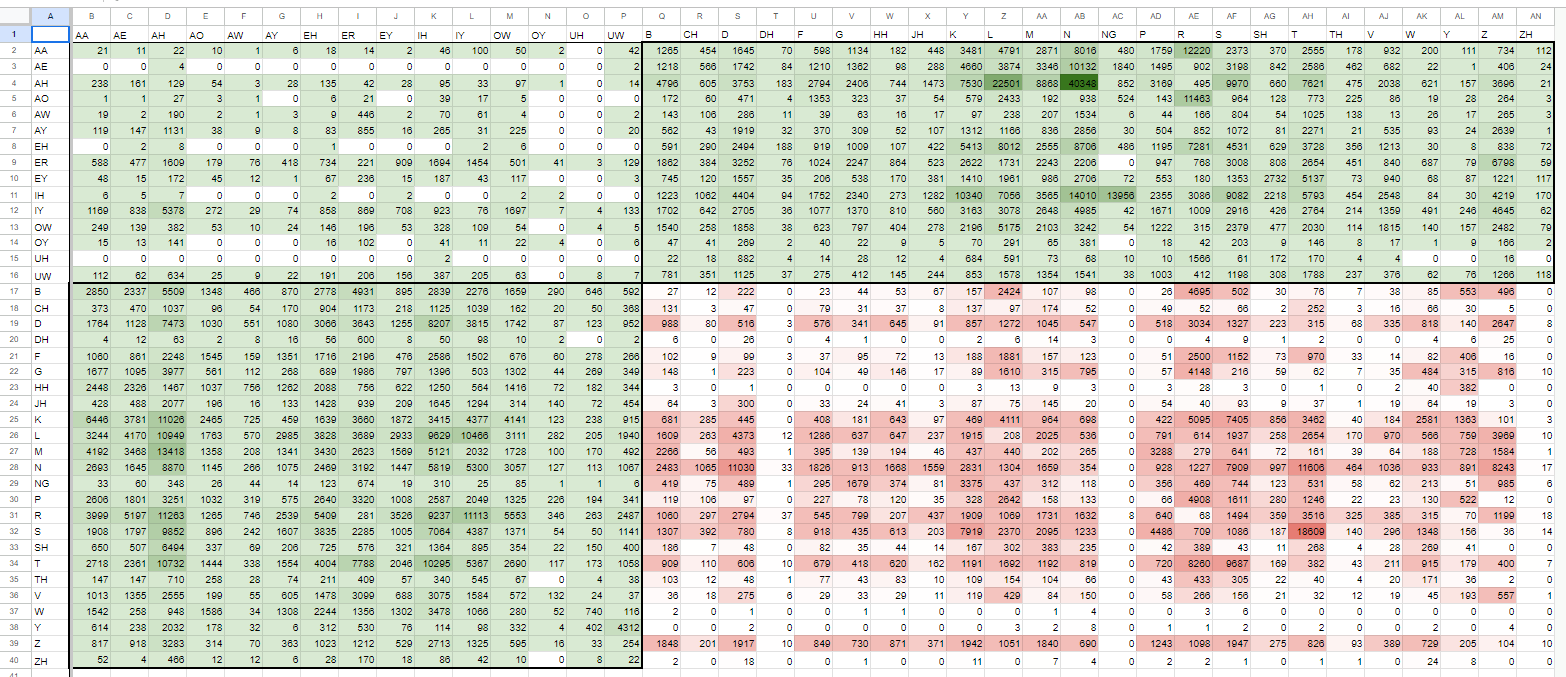
ここで、先に別の仮説の話をします。「辞書データとして使用している、cmdict全体を「もし録ったら」というダミーデータを仮に作って(*1)、oto.iniを生成させ、それを上記の貪欲法の手法で単語を抜き出せば、cmudict全体からミニマライズした英単語リストが作れるのではないか?」という疑問です。
結果、それらしいリストにはなります。ただ以下の図を見てもらえれば分かりますが、正確にはあまりよくないリストになります。
ソートされた単語リストを使えば、当然、前から単語が選ばれがちになります。
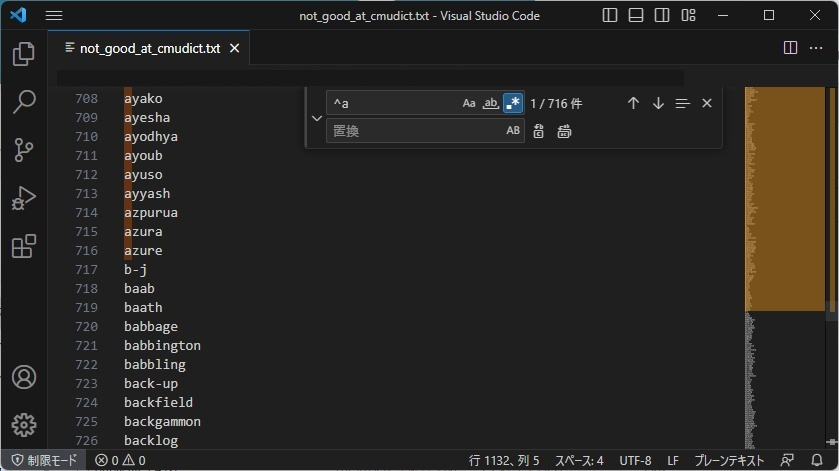{kind=link}
1132単語で収録できるようですが、そのうち716個が「a」から始まるものとなってしまいます。これはよくありません。
つまり0.4.2でした最適化ではこの問題と同じ問題を抱えていることになります。
貪欲法以外にも、同様に他にも局所探索法の手法があります。今回のプログラムの中にプログラミングよわよわでも実装できそうな、多点出発局所探索法を使用して、改めて最適化を行いました。
辞書全体で50回試行させた方は、最終的に200個くらい減って、904単語を録ればcmudict全体の音素を録れるリストができました。
逆にこの結果から、リストの英単語数が900ぐらいを超えているのであれば、読みやすさを重視するあまり、冗長部分が過分になっていることがわかります。
同様に自分のここまで作っていたリストにも同じ処理を掛けました。
10,000回試行させたところ、570単語のリストが出来ました。
一個前のバージョンの貪欲法での最適化では617単語だったところから、更に47語も減らすことができて素晴らしいです。
(穴が発生したりしていないので、もう図は割愛します)
これでとりあえずとしてはひとつ。形になったでしょうか。
4.5.読みづらい && 使いづらい
「読める」英単語を選んだとはいえ、録っていってみると、(目で)読めるけど実は発音はしにくかったなという点や、伸縮区間のことを考えると冗長だとしても単語を2つに分けた方が音源としての取り回しはよくなる、長い英単語がありました。
例を出すと、「representative」「distribution」…などです。
(検討しやすいようにまたページを作りました)
{kind=link}
(上のcheckerと似たような挙動のページですが、このページは発音しにくい長い英単語を別な単語に交換することを目的としています。)
青色の英単語を全て一気に削除すると、それはそれで青色の単語同士で2回程度しか登場していないものが消滅してしまうので、青背景だから悪い単語というわけではないです。
このページによって得られた効果がいくつかあるので、なるべく分けて書きます。
①リスト数が削減できた
まず、愚直にこの青背景になっている単語を上から一つずつ消していくだけで、網羅度を変えずに、収録語が524語に、46個減らせました。
(やはりちゃんとしたロジックベースでやるべきだなと思いました…)
(削除する場合、それを削除した場合にその上でまたその1つしかない音素が発生する場合が多いので、一個ずつ確認しながら下る必要があります。今回の場合「argument」を削除すると、[R_G]が「organization」だけになってしまうので、「organization」を削除しないか、別途追加する必要があったりするということです。)
②読みやすいけど使いにくい
また、これを下っていくと、「beautiful」で[AH_F]があるよと言われるのですが、これは普通に読んでしまうと「ビューテフォー」と言ってしまって、母音がほとんど取れないか無声化してしまっていて、実際に困りました。(しかも[AH_F]はこれ1個しかないわけで…)
「読みやすいか」というのと、「音源として使いやすいか」は別問題なので、例え収録単語が増えてしまったとしても、モーラ数が多い英単語は避けた方が良いですね。
*削除した単語 → 追加した単語(変更した単語)
representative {everyday, step}
responsible {part}
development {very, map}
advertisement {advise}
organization {stargates, zeta, guns}
distribute {lib}
punishment {mash}
expansion {shin}
observation {crabs, vein}
substance // S_Sは削除
beautiful {beauty, buff, fun}
hospital {cost, hale}
unusual {canyon, ZH_UW}
strawberry strawberry // 伸ばして発音しやすいので続投
miniature {arm, CH_UH}
digestion {digest, catchup}
industry {freeing}
durations {D_UH}
一部、発音そのままのものに変化していますが、
英単語であることにこだわるあまり、伸縮幅が取れない使えない音素になってもしょうがなく、「最低でも単独音としてはなりたつようにする」という方針の為にこのようにしました。
最終的にこれらの単独音はオプションの方にまとめてしまっても良いかもしれません。
(他にも更に頻度の低い[DH_AA]とかのCV音素は、一番下に貼ってあります)
③実は必要な母音がもうちょっとある
industry(IY_IH)を変更するときに気付いたのですが、
「IH→(母音)」になることはほぼありませんが、
「(母音)→IH」となる要素はそれなりにあるようです。
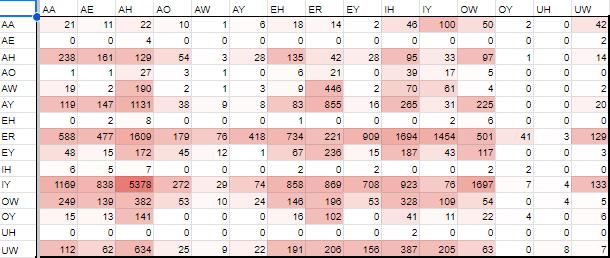
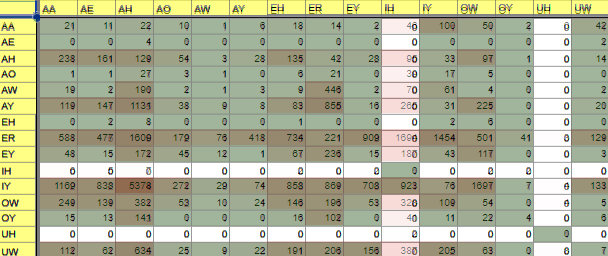
・VVのパーセンタイル
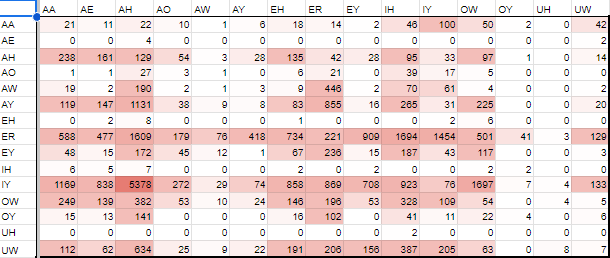{kind=link}
・ver0.4.4に重ねたもの
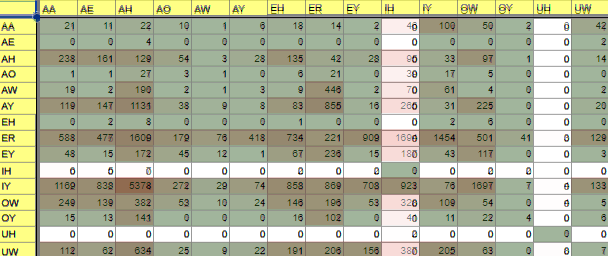{kind=link}
上で、「200回以上のものを取り出して録ること」としているので、
{AY_IH, ER_IH, OW_IH, UW_IH} になります。
この4つは(単語レベルでも登場するので)録った方がよいものとしてリストに追加を考えます。
{eyeing, flourish, yellowest, into}
今回はこの4つとしておきましょう。
ver0.4.5の完成です。
最終的に530語になりました。
4.X.まだ改善できる要素
実際にこの音源を使っていくと、概ね音素をカバーできていましたが、あくまで単語ベースであるため文章で連続したときに出現しやすい音素は対応していません。
自分が確認できているものとしては「I'm gonna」という文章があった場合で必要になる[m g]がこのリストにはありません。
さすがにこの文法は簡単に登場しやすそうなもので且つ、簡単な英単語で構成されているのでリストに加えた方が良さそう…ですが、他にも実際に使っていくとあった方がよさそうな音素が実はまだまだあるかもしれません。
@頻出しそうでかつ任意の単語が後ろに接続できる英単語
・述語動詞
{
[r]you are, [z]It is, [m]I am
}
・前置詞
// during の登場頻度は低いと考えられるが、...ing ~~~ という形式は多いだろう
{
[v]of, [n]on, [dh]with, [ng]during, [f]off, [p]up
}
・接続詞
// dやtは明確に発音せず接続する場合が多いため、不要か?
{
[d]and, [t]but, [z]as, [f]if
}
d→dh : and thisなど
dh→ : with youなど、英単語だけでは不足する音素が沢山ある
m→dh : from this
(n)網羅済み
ng→ : ngで始まる英単語がない
(t)網羅済み
v→ : I've been
z th
*ただ…動詞をすべて考慮すると結局CCをすべて補完することになる
下の蛇足でも書かれていますが、簡単な英単語の組み合わせ、もしくは短文で簡単に登場できて不足する音素があれば私に教えてくれると助かります。
もう…終わりだよね……?
=====ここからは開発者の方向け?=====
・cmudictって?
この辺からダウンロードできます。
・実際に含まれて"いない"、CVとVCのリスト
図に書いてありますし、indexから生成できますが、一応。
// 優先度が低そうだったので含まれていない音素
(地名や人名、英語から見て外国語の表現は省いた)
// 同じ単語を繰り返す前提でしか考えていないので、普通に別な単語を連続させれば普通に登場する可能性は十分にある
(それならば録音難易度が元のARPASingと同じになってしまうのでできればやりたくない)
・[IMPORTANT] 足りなかったらバージョンアップでガンガン追加を検討してよい。
// CV
DH_AA, DH_AO, DH_OY, DH_UH, DH_UW,
NG_UH, NG_UW
SH_OY,
TH_OY, TH_UH,
V_UH,
ZH_AE, ZH_AO, ZH_AW, ZH_AY, ZH_EH, ZH_EY, ZH_IY, ZH_OW, ZH_UH
// VC
UH_B,
OY_CH,
AO_DH, AW_DH, OY_DH, UH_DH
OY_G,
AE_HH, UH_HH
UH_JH
UH_N
AW_NG, AY_NG, ER_NG, EY_NG, IY_NG, OW_NG, OY_NG, UH_NG, UW_NG
OY_R
AW_SH, OY_SH
OY_TH, UH_TH
AO_V, OY_V, UH_V
AE_W, AO_W, EH_W, UH_W,
IH_Y, UH_Y
UH_Z
AO_ZH, AW_ZH, AY_ZH, OY_ZH, UH_ZH
・無駄?
AH_N, IH_NGは英単語の性質上登場回数が増えるのは仕方ないとしても、
Y_UWが40回も登場してしまっているのもぱっと見では少し無駄を感じます…が、実際の登場単語の中身を調べてみると…
{K_Y_UW, T_Y_UW, N_Y_UW, HH_Y_UW, B_Y_UW, P_Y_UW, M_Y_UW, R_Y_UW,L_Y_UW}
これらが網羅されてます。はからずも口蓋化された音が網羅されていました。(CCを使う前提ですが)
Files