Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

The Very Best Workflow For SDXL DreamBooth / Full Fine Tuning - Results Of 100+ Full Trainings (Patreon)
Downloads
Content
Patreon exclusive posts index to find our scripts easily, Patreon scripts updates history to see which updates arrived to which scripts and amazing Patreon special generative scripts list that you can use in any of your task.
Join discord to get help, chat, discuss and also tell me your discord username to get your special rank : SECourses Discord
Please also Star, Watch and Fork our Stable Diffusion & Generative AI GitHub repository and join our Reddit subreddit and follow me on LinkedIn (my real profile)
17 August 2024 Update
I have done new 30 trainings (i had done 150+ before) after the latest changes of the Kohya
With v2 new configs (at the attachments) we have added noise_offset and ip_noise_gamma (perturbation noise)
These new settings improves quality of colors after training and make them lesser saturated and more natural
23 May 2024 Update
Example RunPod SDXL Config Newest GUI : Example_SDXL_RunPod_Config.png
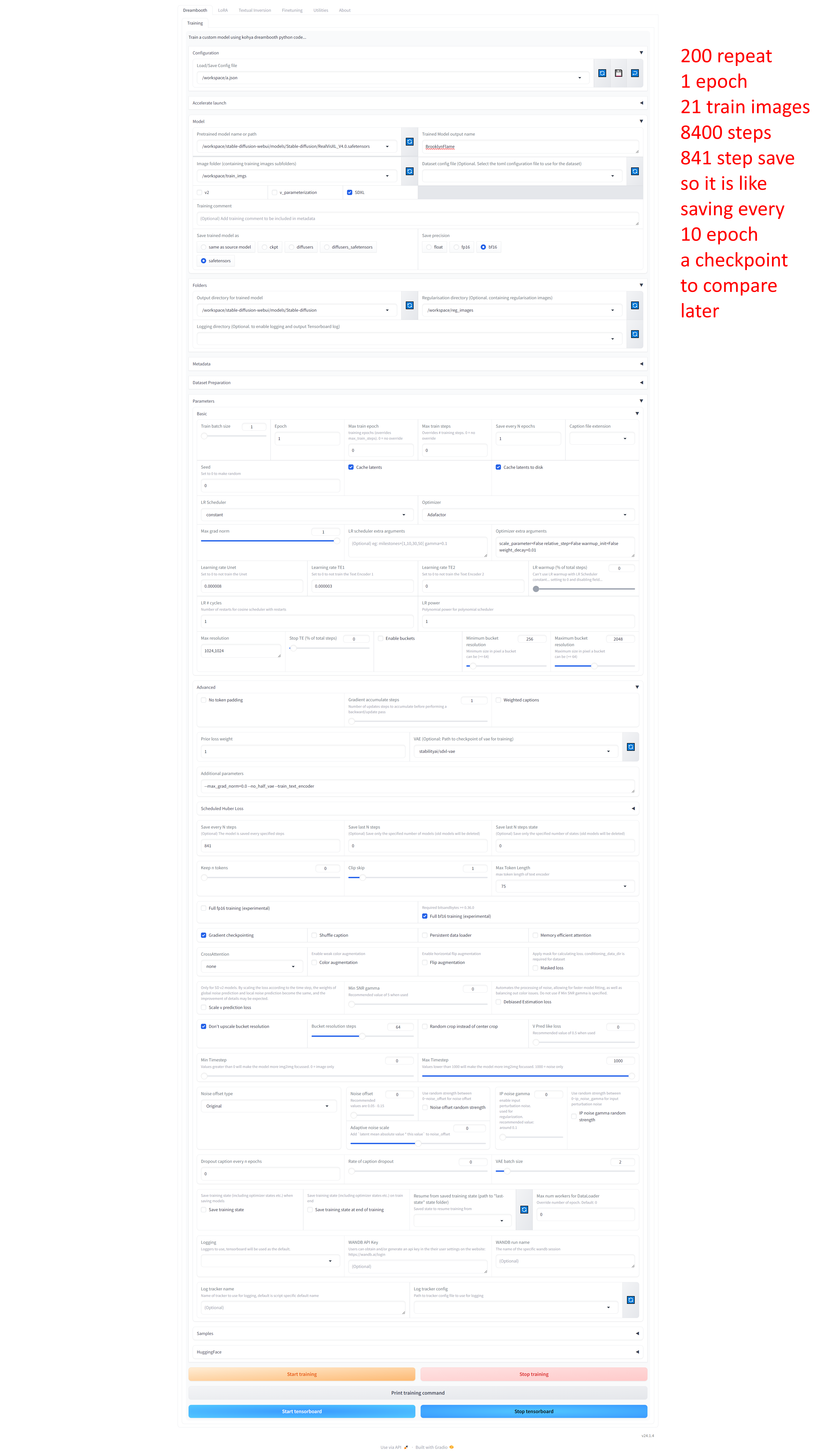
For 8400 (200 repeat) steps training on RunPod, full configuration image : runpod_8400_Steps.png
For Windows only folder paths would change
21 May 2024 Update
20 Example images shared here please consider to upvote : https://www.reddit.com/r/StableDiffusion/comments/1cwuxeb/newest_kohya_sdxl_dreambooth_hyper_parameter/
Extensively compared different LR rates for both Text Encoder and U-Net
This was mandatory since recent Kohya updates changed how LR is applied
The new config files are tested on Version 24.1.4 and commit id 5ed56238b2c5c93e1510876c20524d391793161d
My newest strategy is setting 200 repeat and 1 epoch and saving every n-steps checkpoints to compare
This way it is able to use maximum number of regularization images
If you don't use reg images, you can directly set number of epochs
I also have prepared 20 amazing prompts to compare checkpoints
I am using x/y/z checkpoint comparison and Prompt S/R
Check How-I-Do-Test.png to see how I am testing
Check test_prompts.txt to see prompts
You can use their Prompt S/R version from prompt_SR_test_prompts.txt
I am also sharing 2 comparison files (comparison 1 , comparison 2) with you so you can see different Learning rate values difference
Comparison files are huge 24346 x 22772 pixels
The naming of comparisons meanings are as follows : 8e_6_TE_2e_6 : 8e-06 (0.000008) is the U-Net learning rate and 2e-06 (0.000002) is the Text Encoder 1 learning rate. Text Encoder 2 never trained.
I have used RealVis XL version 4 for trainings : https://huggingface.co/SG161222/RealVisXL_V4.0/resolve/main/RealVisXL_V4.0.safetensors
You can also use SDXL Base but for realism I prefer RealVis XL 4
Tier1_24_GB_Slower_v2.json config file uses 16.3 GB VRAM currently - same quality config on OneTrainer is only 10.3 GB since it has Fused Back pass : https://www.patreon.com/posts/96028218
Tier1_48_GB_Faster_v2.json config is same quality as 24 GB but faster since doesn't use Gradient Checkpointing. Gradient checkpoint reduces VRAM usage but also makes it slower with same quality
Sadly there isn't anymore lower VRAM since both xFormers and SPDA attention didn't reduce VRAM usage
However you can still try on 12 GB card config : Tier2_LowVRAM_v2.json
I strongly suggest you to use OneTrainer if you don't have 24 GB GPU
I personally find that 8e-06 for U-Net and 3e-06 for Text Encoder 1 as best for flexibility and resemblance
If you need more like anime 3d style, you can reduce learning rate to 6e-06 (0.000006) for both Text Encoder 1 and for U-Net and lose some resemblance but obtain more styling : click to download comparison
Currently save every n-steps is set to 451
You need to set it according to your total number of steps
So after setting your Pretrained model name or path,
Trained Model output name, Image folder (containing training images subfolders), Output directory for trained model, Regularisation directory (Optional. containing regularisation images) click Print training command button and look for max_train_stepsThen you can divide it to the number of checkpoints you want to obtain
In my case I had 15 training images, 150 repeat and use our very best ground truth regularization images with batch size 1 : https://www.patreon.com/posts/massive-4k-woman-87700469
So my max_train_steps was = 15 x 150 x 2 = 4500 steps
Therefore I made save every n epoch = 1, train epoch = 1 and save every n-steps = 451 - we add +1 so at last step we don't save twice, and thus I got 10 checkpoints
The experiments are made on below training dataset with 15 training images and 150 repeat and 1 epoch

I didn't use any captioning. Only ohwx man for training images from folder names and man for reg images from folder names
Hopefully will record a new tutorial for Kohya later for Windows, RunPod, Massed Compute and Kaggle
You can see image captioning effect comparison here : https://www.patreon.com/posts/compared-effect-101206188
You can also see different Text encoder Learning rates comparison by downloading this zip file : https://huggingface.co/MonsterMMORPG/SECourses/resolve/main/text_encoder_comparison.zip
I think best strategy would be training 2 models
1st 8e-06 U-Net and 3e-06 Text Encoder 1 and second one is 6e-06 U-Net and 6e-06 Text Encoder 1 and then generate images on both of them and use the best ones. Since each model will perform best on individual prompts.
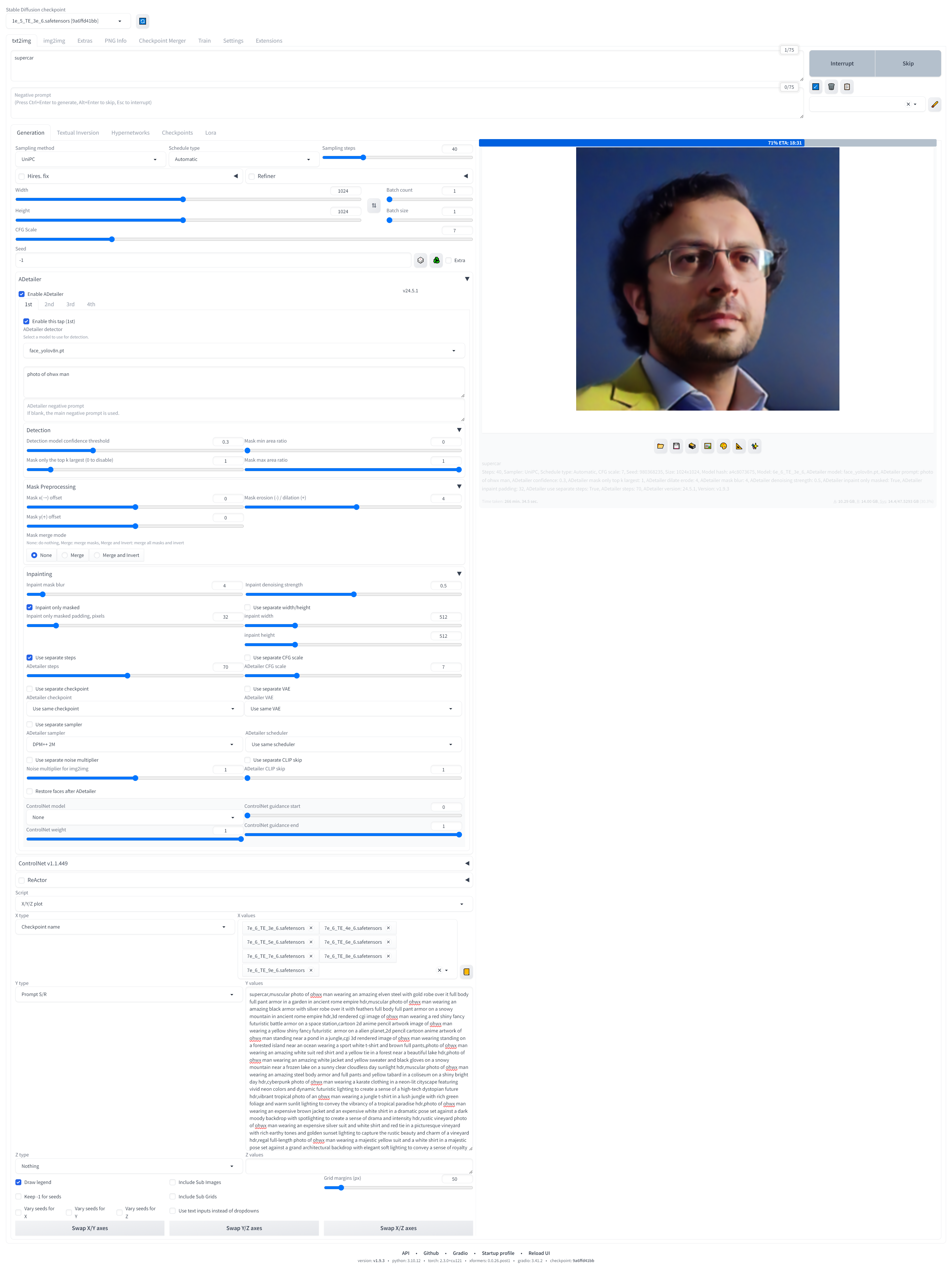
As a sampler I find that UniPC is best, Schedule type doesnt matter, 40 steps for generation and 70 steps for ADetailer with 0.5 denoise
How to do DreamBooth training quick Patreon special tutorial video >
How to setup and install Kohya on Windows : https://youtu.be/sBFGitIvD2A
How to setup and install Kohya on RunPod : https://youtu.be/-xEwaQ54DI4
All models saved in https://huggingface.co/MonsterMMORPG/kohya_new_test (private repo a reminder for me)
TIPs
--enable_wildcard
to enable multi line caption in Kohya SS
20 Example Images Please Also Upvote : https://www.reddit.com/r/StableDiffusion/comments/1cwuxeb/newest_kohya_sdxl_dreambooth_hyper_parameter/




{kind=link}
{kind=link}
{kind=link}
Files