Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

「LayerDiffusion」で透過生成!「背景にキャラ」「キャラに背景」そして… (Pixiv Fanbox)
Content
こんにちは、スタジオ真榊です。今日は、先日公開されたばかりのレイヤー別画像生成技術「LayerDiffusion」についてのインプレッション記事をお届けします。順次対応するwebUIが増えていくようですが、この記事では「Forge」版について、インストールまでの流れと各種機能の使い方、使用感や使い道について検証していきたいと思います。ちなみに、現時点ではAnimagineXL3などSDXL系のCheckpointでの使用が想定されており、SD1.5系などへの対応は「今後需要があれば」とされています。
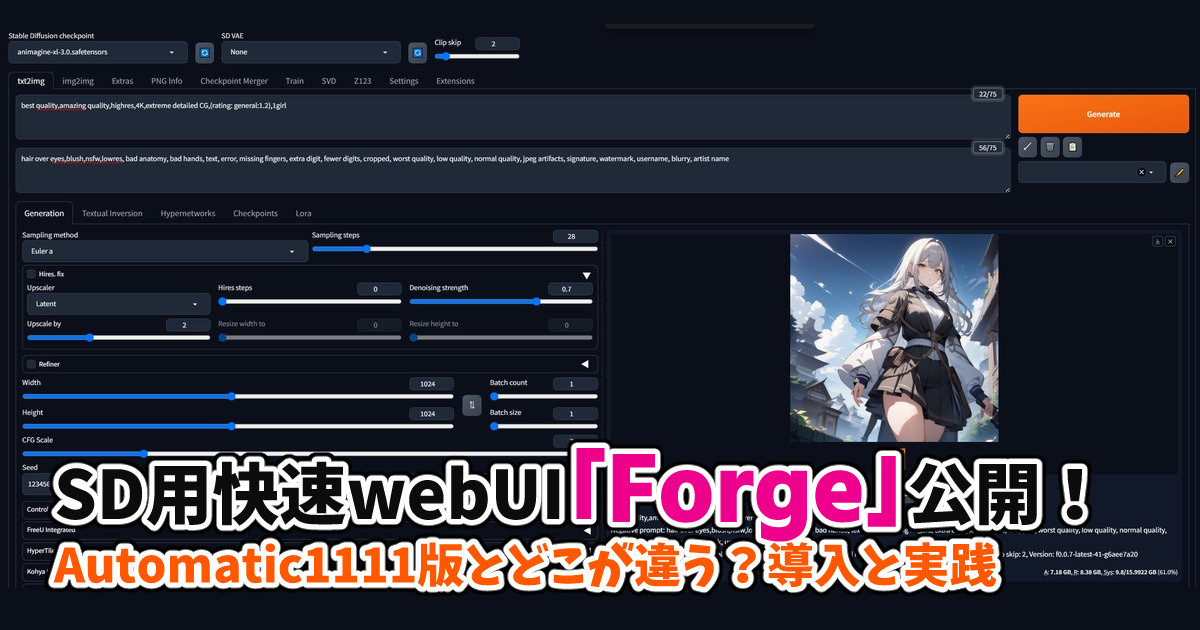
A1111版SDwebUIを上回る速度で人気を集めている快速webUI「Forge」のインストールや使い方については、こちらを参照のこと。
SD用快速webUI「Forge」公開!A1111版とどこが違う?導入と実践
こんにちは、スタジオ真榊です。支援者の皆様には連日、プロンプト超辞典の枝記事が生成されるたびに更新通知が行ってしまっているのではないかと思います。ご迷惑をおかけしておりますが、あと3分の1ほどで終わりますのでどうかご容赦ください。 さて、今日はControlnetの開発者lllyasviel(イリヤスフィール)氏が公開...
目次
1.LayerDiffusionで何ができるのか
2.Forge版をインストールしよう
3.インストールでつまづいたときは
4.「Method」について
- From Background to Blending(背景にブレンド)
- From Background and Blending to Foreground(前景を分離)
- From Foreground to Blending(前景にブレンド)
- From Background and Blending to Foreground(背景を分離)
5.発展的な使い方を探ってみる
6.終わりに
1.LayerDiffusionで何ができるのか
LayerDiffusionはその名の通り、画像編集ソフトのレイヤーのように、キャラクターや物品などを背景と分離した透過画像として一発生成できる技術です。
これまでの画像生成は、前景・背景・エフェクトといった階層が「統合」された状態で生成することしかできなかったため、一部だけを思い通りに変更することが非常に難しいのがネックでした。思い通りの絵作りをするためには、これまでもこのFANBOXで解説してきたように、白背景でいったんキャラだけ生成して背景を切り抜き、別に生成した背景になじませる…といった工夫をしなければならなかったのですが、「LayerDiffusion」はキャラクターや物体、背景などをそれぞれ別レイヤーの透過pngとして一発生成できるのが特徴です。
{kind=link}
たとえばこのように、単に縁取りをきれいに切り抜いただけでなく、半透明のガラスやエフェクトまで美しく透過させた状態で一発生成することができます。これまでの背景透過処理に比べてフリンジや削り残しなどもなく、非常に高精細なことが分かります。
さらに、LayerDiffusionがすごいのはここから。背景だけの状態から生成を始め、猫や花瓶、本といったオブジェクトを各レイヤー別に生成して、矛盾なく重ねていくことまで可能なのです。例えば猫の種類が気に入らなければ、背景やインテリアはそのままに、猫だけを何度もガチャするようなこともできるわけですね。
{kind=link}
こうした「背景に前景(キャラなど)を描き足す」手法はこれまでもNAIv3インペイントなどで苦心して実現してきたわけですが、どうしても書き足した前景の周辺は元画像から変容してしまったり、背景に矛盾なく溶け込ませるのにはそれなりに熟練が必要でした。
「キャラを好きな場所に呼び出す魔法」V3インペイント活用検証

こんにちは、スタジオ真榊です。前回の記事(▼)ではNovelAIv3のインペイント機能の応用について掘り下げましたが、今回はその発展として、「背景の好きな位置にキャラクターを違和感なく呼び出し、演技を付ける」手法について検証したいと思います。 前回のおさらいとして、V3インペイントを使うと「一部しか描かれてい...
レイヤー別の透過画像を高品質に生成できるとなれば、挿絵やポスター、資料作りなどさまざまな素材として使ったり、ノベルゲームの立ち絵のような「差分」づくりにも役立てられそうですね!
2.Forge版をインストールしよう
能書きはこれくらいにして、さっそくForge版をインストールしていきましょう。拡張機能のGithubはこちら。
まずはForgeを最新版にアップデートしてからインストールするのを忘れないようにしましょう(重要)。インストールは通常の拡張機能と同様で、githubのURLを「URLからインストール」に放り込んでインストールボタンでOKです。
{kind=link}
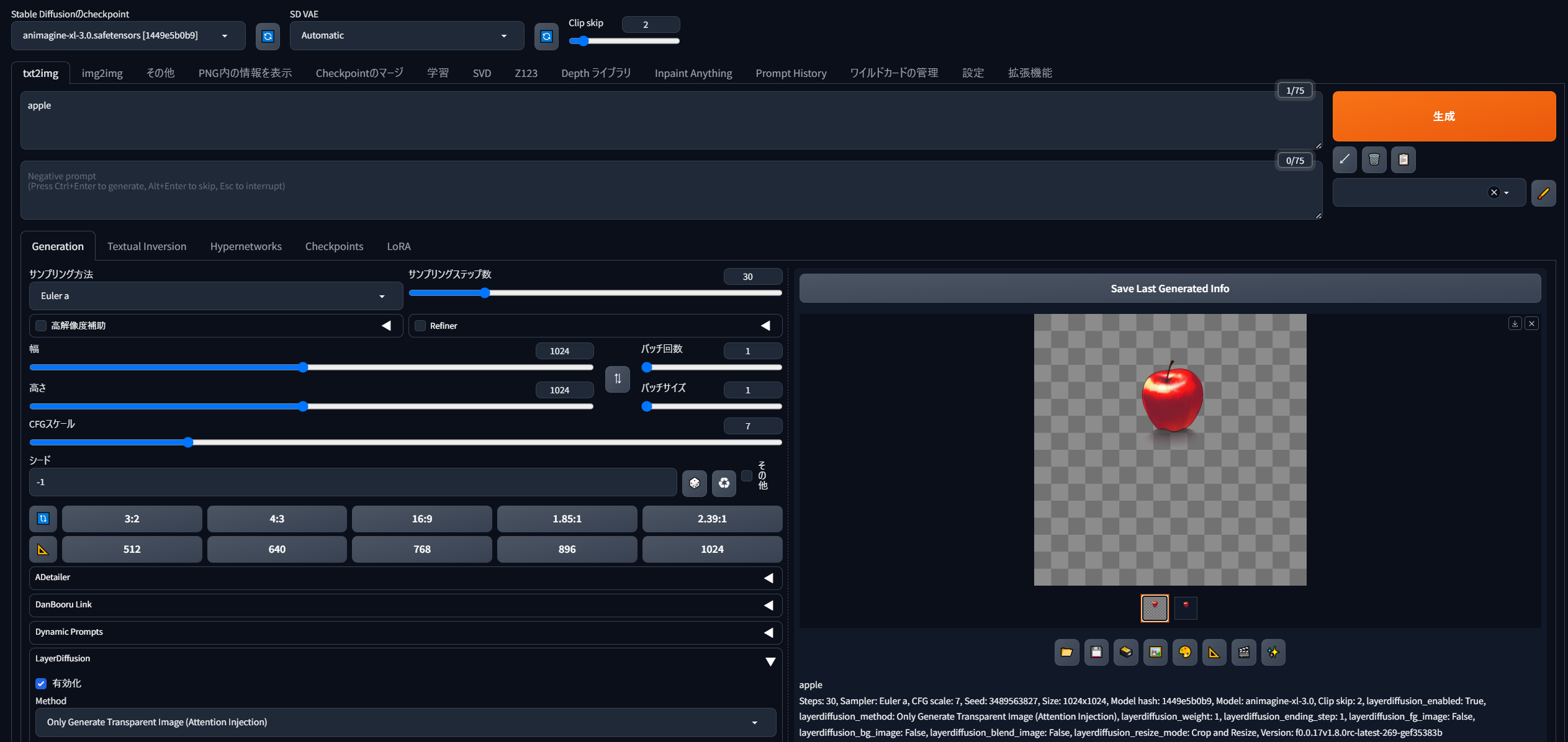
あとは「適用してUIを再起動」し、このようにtext2image画面などに「LayerDiffusion」のメニューが追加されていればインストール成功です。
{kind=link}
あとは「有効化(enabled)」にチェックして、「Method(生成方法)」はいじらずSDXLモデルで通常通り生成すれば…
{kind=link}
このように透過画像が生成できました!
画像が二つ生成されていますが、市松柄の方は透過された場所を疑似的に示しているだけのもので、もう一枚(向かって右)の方が透過pngですので注意してください。また、なぜか透過画像の方は通常の「outputs」フォルダに保存されず、ユーザーの「AppData\Local\Temp\gradio」フォルダに出力されるようなので、今後の対応を待ちたいところです。(※エクスプローラのアドレスバーに「%LOCALAPPDATA%\Temp\gradio」と打ち込むと飛べるはずです)
画面上ではちゃんと透過しているか分かりにくいと思うので、透過画像をクリスタで呼び出して背景を適当なブラシで塗りつぶしたのがこちら。リンゴの影も含めて自然になじんでいることが分かると思います。
{kind=link}
3.インストールでつまづいたときは
「有効化」をONにしているのに、普段と特に生成結果が変わらない場合は、まずForgeのアップデート(git pull)がうまくできていないことが疑われます。前述したとおり、LayerDiffusionを利用するには、Forgeのバージョンを最新版にアップデートしておく必要があるのですが、Checkpointなど各モデルをA1111版と共有するなどの目的で「webui-user.bat」を書き換えていた場合、それが原因でgit pullがうまく動作しないことがあるようです(私の環境でも確認しました)。
{kind=link}
▲Forge導入記事でも解説したモデル参照手法
webui-user.batを上記のようにしている場合、「set COMMANDLINE ARGS=」以降を空欄にして上書き保存し、もう一度git pullしてみてください。記事執筆時点の最新版は「f0.0.17v1.8.0rc-latest-269-gef35383b」です。画面最下部のバージョン表記がそのようになっているかチェックしておきましょう。
{kind=link}
◇キャンバスサイズや生成枚数に注意
手元の環境ではキャンバスサイズを1024×1024pxや1536×1024pxで生成すると成功しましたが、アスペクト比を細かく刻んで変更すると「TypeError: 'NoneType' object is not iterable」エラーが出ました(下図参照)。複数枚同時生成をしようとしたり、あとで説明する「Method」欄の入力画像が大きすぎたりするときもこのエラーが出たので、もしこうした現象が起きた場合はいったんキャンバスサイズや生成枚数を見直してみてください。
{kind=link}
◇公式の生成テストをチェック
公式Githubのこの項目で、正しくインストールされているかのテスト方法が紹介されています。それぞれ「Juggernaut XL V6」や「animaPencilXL v100」といったSDXL系モデルで同じ画像が生成できるかチェックする内容となっています。
4.「Method」について
さて、このように基本状態で生成すると、背景が市松模様になった画像と、透過状態になった画像の2枚が生成されます。これは、LayerDiffusionメニューの「Method」欄が「Only Generate Transparent Image (Attention Injection)」=「透過画像を生成するモード」になっているためです。
{kind=link}
※ちなみに、LayerDiffusionをオフの状態にし、Seed値などを同設定で生成するとこのような画像になります。オフの状態と全く同じ背景透過画像が生成できるわけではない点に注意が必要です。
{kind=link}
「Method」の種類は、他にこのようなものがあります。
{kind=link}
「Only Generate Transparent Image」は(生成手法を二種類から選べますが)、いずれも背景が透過された画像を生成するものです。そのほかの4つが、冒頭で解説した背景に前景を追加していく(または前景に背景を追加していく)ためのメソッドです。一つずつ見ていきましょう。
From Background to Blending(背景にブレンド)
「From Background to Blending」は、事前に読み込ませた背景画像に、前景を書き加える(ブレンドする)機能です。このように、ディズニーランドの背景画像にミナちゃんを書き加えることができます。(御覧のとおりアスペクト比を変更することもできます)
{kind=link}
やり方は簡単。Method欄で「From Background to Blending」を選び、「Background」欄に読み込ませたい背景画像を指定して、書き加えたいものをプロンプト指示して生成するだけです。
【パラメータについて】
・プロンプトは前景(この場合はキャラクター)部分についてのみの記述でOK。
・LayerDiffusionの「重み」は基本1でOK。「StopAt」は「1」でステップ全体に効果が及ぶのでこちらも基本1でよいが、入力画像と多少変化しても構わない場合は落とした方が良い結果が得られることもある(後述)
{kind=link}
・リサイズモード
生成するキャンバスサイズと背景画像のアスペクト比が異なる場合、「リサイズモード」の指定によって余白が切り取られるか、縦横比が合うように変形するかを選択することもできます。ここでは、このような縦長の背景に対し1024x1024pxの正方形で生成するので、上下の部分がクロップ(切り取り)されて生成されます。
※ちなみに、どのメソッドも初回生成時はこのように必要モデルが「layer_model」フォルダに自動インストールされるので、少々時間がかかります。
{kind=link}
さきほどのミナちゃんイラストで使用したプロンプトは以下の通り。太字部分のようにうまく生成されるものを指示しないと、追記部分が空中に浮かんでしまったりするので注意が必要です。
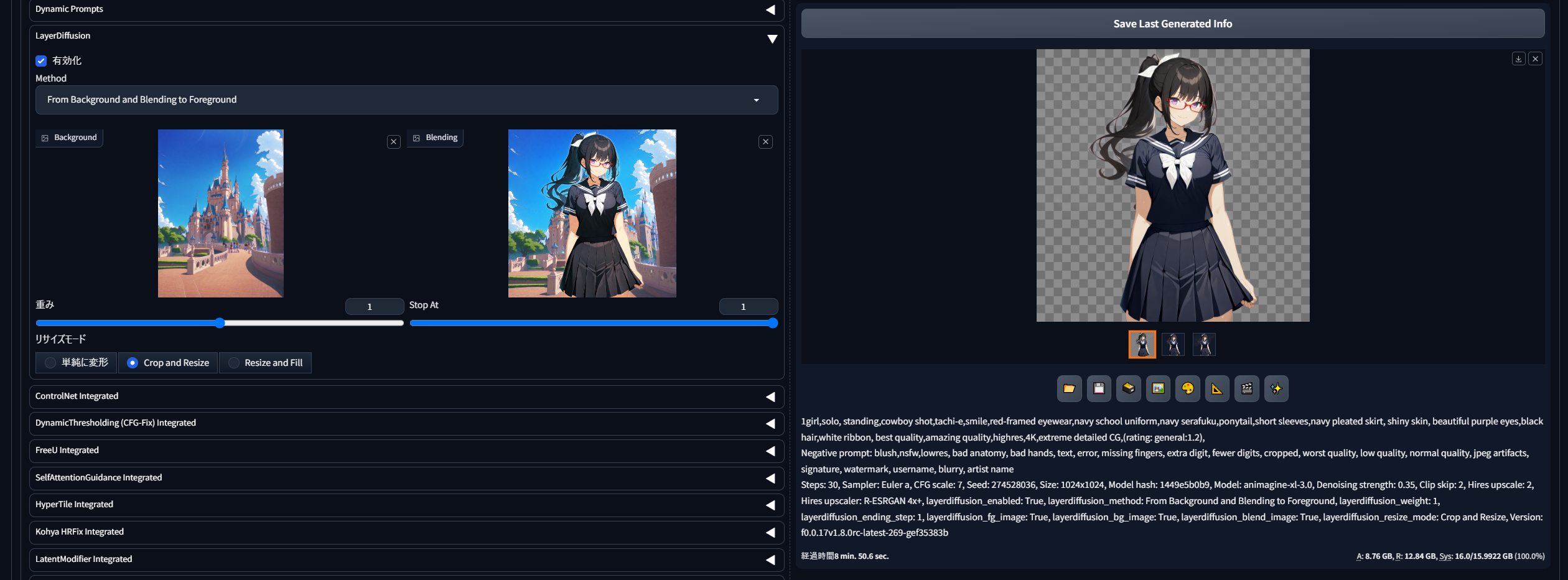
PP:1girl,solo, standing,cowboy shot,tachi-e,smile,red-framed eyewear,navy school uniform,navy serafuku,ponytail,short sleeves,navy pleated skirt, shiny skin, beautiful purple eyes,black hair,white ribbon, best quality,amazing quality,highres,4K,extreme detailed CG,(rating: general:1.2)
{kind=link}
このように、椅子に座らせるようなこともできなくはありません。ただ、大きさや角度が安定しませんし、影も正確には描かれないようです。「sitting on chair」とプロンプト指定したら、赤いソファの上に別の椅子を置いて座ってしまうケースも確認されました。
{kind=link}
一方、実写調モデル(juggernautXL6)では、このようにかなり正確に「座らせる」ことができています。このあたりはイラスト調モデルの方が苦手とするところなのかもしれません。
{kind=link}
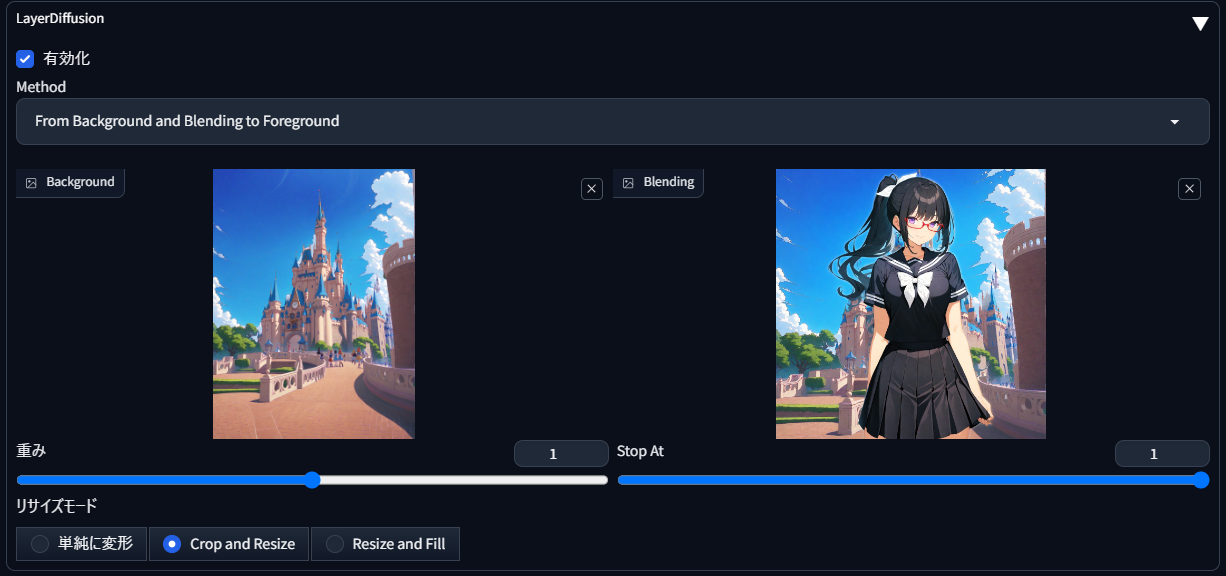
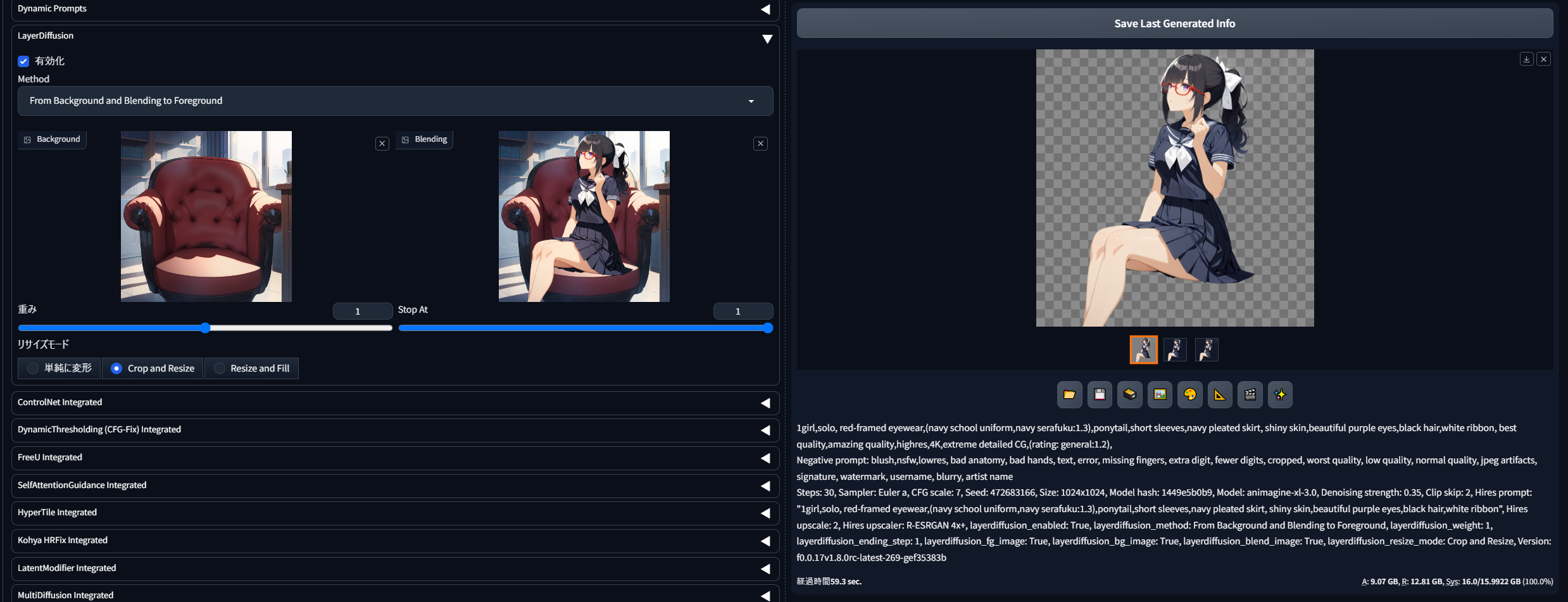
From Background and Blending to Foreground(前景を分離)
こちらは、「From Background to Blending」で背景に追記した前景部分だけを抽出するのに使える機能です。いまディズニーランド背景にミナちゃんをブレンドしたわけですが、ここからミナちゃん部分だけを透過pngとして抜き出せたらより捗るよね、ということですね。
{kind=link}
このように、「Background」欄にはさきほどと同様に背景画像を、「Blending」欄には新たに得られたブレンド画像を放りこみます。画面右側の生成結果からここにドラッグしてくればOKです。
(※分離機能を使う場合、サンプラーは「Euler A」「Unipc」が推奨されており、DPM系は非推奨とのことです)
あとはプロンプトもそのままで生成しますと、うまくいけばこのように「ミナちゃん部分だけ」が透過pngとして得られました。プロンプトには、背景部分について追記しないことが重要です。(この場合、disneylandやblue skyは不要ということ)
{kind=link}
こちらは同様に、いすに座らせたミナちゃんだけを透過pngにしたもの。ちなみに「sitting」や「chair」がプロンプトに残っていると、いすごと切り抜いてしまう現象が起きました。単純に「背景画像ーブレンド画像=前景画像」となるわけではなく、プロンプト指示でどう切り抜くかを左右できるようです。
{kind=link}
なぜ別々の機能になっているの?
わざわざ二つの機能に分離しないで、「From Background to Blending」をしたときに透過画像も同時に生成してくれれば良いのでは?と思うところですが、公式の記述を見る限りでは技術的に難易度が高いようです。一括で「背景+前景」「前景のみ透過」の両方が出せるモデルも開発中とされています。
{kind=link}
(▲公式Githubよりスクショ引用)
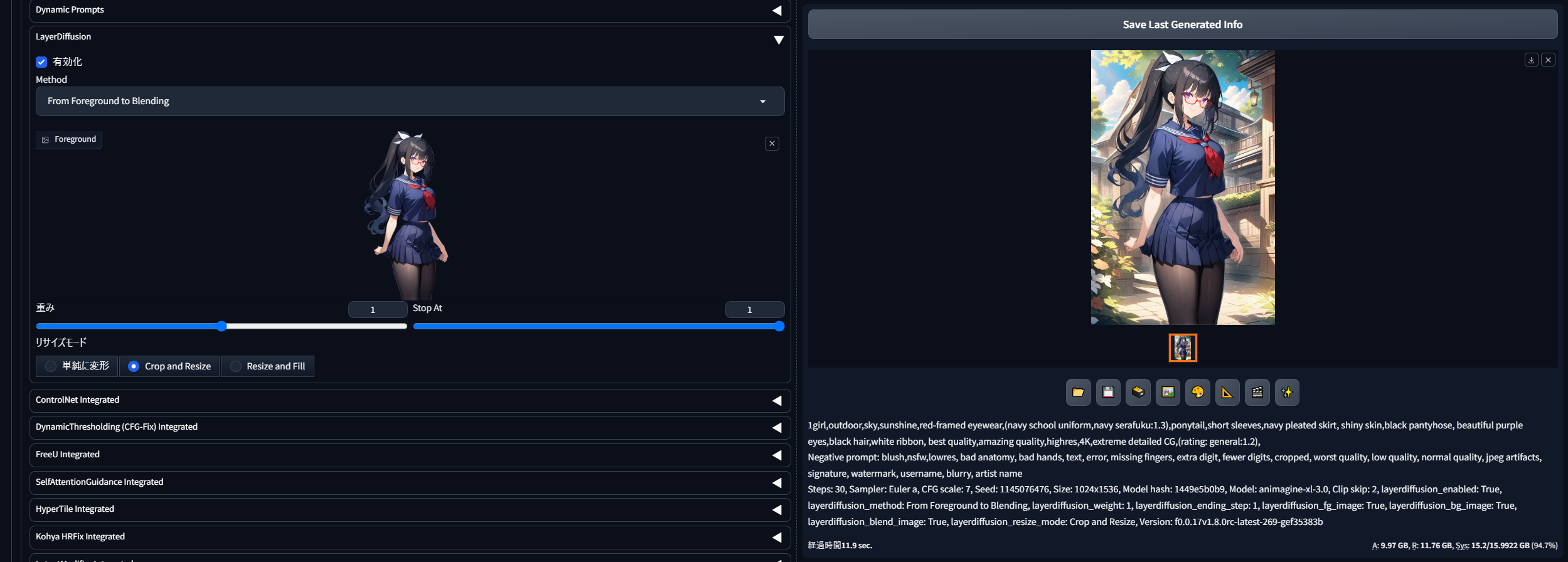
From Foreground to Blending(前景にブレンド)
「From Foreground to Blending」(前景にブレンド)は、これまでと逆に、前景(人物など)に背景を書き加えることができるメソッド。「Foreground(前景)」画面に背景を書き加えてほしい画像を放り込み、背景についてのプロンプトを入れて生成するだけです。
{kind=link}
このように、前景だけの画像に背景部分を追加することができます。(outdoor,sky,sunshineを追記)
{kind=link}
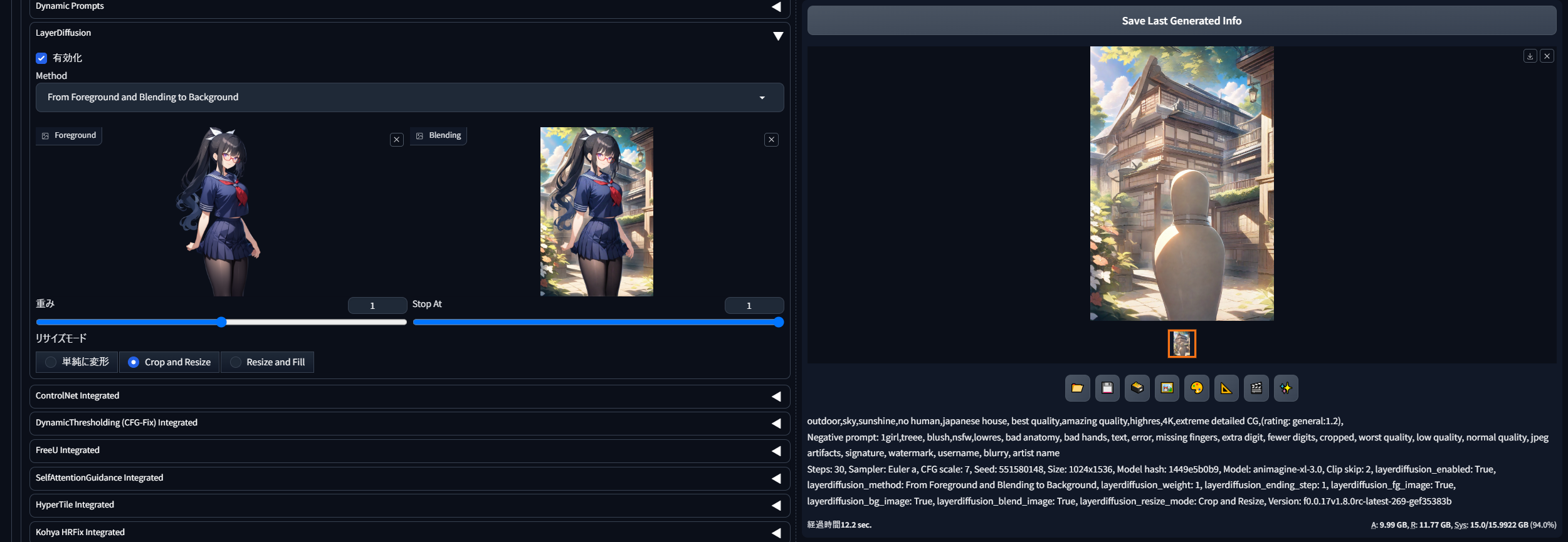
From Background and Blending to Foreground(背景を分離)
最後はもう想像ができると思いますが、さきほどの透過ミナちゃんに追記した背景部分のみを抽出するためのメソッドです。Foregroundに前景画像、Blendingにさきほど生成したブレンド済み画像を入れて、背景に関するプロンプトのみで生成するとこのように背景のみが抽出されます。
{kind=link}
ただし、From Background and Blending to Foreground(ブレンドされた前景を分離)とは異なり、キャラクターで多くの部分が隠されている存在しない背景を補完しなくてはならない関係で、このように結構アレな結果となりました。
{kind=link}
そもそも実験に使用したAnimagineXL3が背景にさほど強くないモデルということも関係していると思います。juggernautのような実写系だと結構補完してくれそうですが、それならNovelAIv3のインペイントやPhotoshopの「生成塗りつぶし」でも同様の補完はしてくれるので、使いどころが難しい機能になってしまうかもしれません。
公式githubでは、このようなとき「Stop at」のパラメータを0.5(=全ステップのうち半分に差し掛かったらLayerDiffusionを停止する)にするとよいことを示唆しています。上図のように元画像に忠実にしようとして変なオブジェクトが中央に生成されてしまうのを防ぐため、「元画像の背景と多少変化してしまってもよいのでより良い成果を得る」ための操作ですので、覚えておきましょう。
5.発展的な使い方を探ってみる
さて、LayerDiffusionに人物のみ、オブジェクトのみ、背景のみを生成したいときに一発出しできる強みがあるのはこれまでの実験で分かった通り。他にどういった使い道があるのかも気になるところです。いわゆる「エフェクト」や「コラージュ用素材」といったものが作れるのか、いろいろと生成実験を行ってみました。
1.エフェクト系は難しい
とりあえず行ってみた魔法やテレビ画面風の走査線といった「エフェクト系」はうまくいきませんでした。原因は、「そもそも透過していない場合もそうした画像を生成することは難しい」ということです。学習した教師データに大量に含まれているものなら描くことができますが、エフェクトのみが描かれた(つまり素材画像のような)教師データはあまりないと思われ、そのため思ったような画像を得ることはできませんでした。
「エフェクト風透過背景」を作るのも試してみましたが、このようにほぼ全体が敷き詰められてしまったりして、透過部分の位置をコントロールすることが難しいと感じました。
{kind=link}
2.イラスト前景に実写背景
前景と背景を別々に生成できるわけですから、前景・背景がそれぞれ得意なモデルに別々に描いてもらうという手法を思いつきました。これはできなくはありませんでしたが、芳しい結果にはなりませんでした。
このように、AnimagineXL3前景にJuggernaut背景を組み合わせてみたのですが、コンフリクトを起こして髪の毛のはざまなどがやはりおかしくなりますし、アニメタッチの前景に合わせようとして背景のタッチもどっちつかずになり、低劣化したように感じます。
{kind=link}
どうも切り抜きに使用しているモデルとCheckpointとの相性があるようで、思ったような結果になるとき、ならないときの差が激しいです。
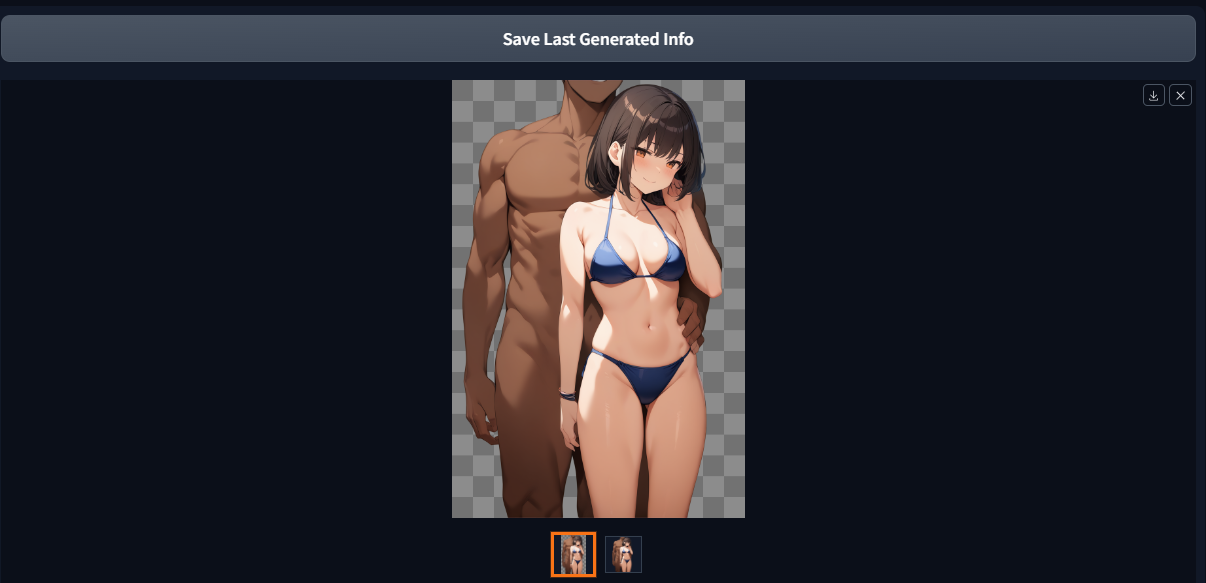
3.「コラ素材」を作る(NSFW)
少し言いにくいのですが、NSFW目的での「コラ素材」的な使い方は非常に発展性を感じました。例えば、背景透過した竿役(全裸男性)を一人横向きに立たせるとか、スマホを持った手の透過素材を作るとか、見切れている男性器をたくさん作るとか…
背景を透過した「立ち絵」が一番出しやすいので、いろいろと応用が思いつく方は多いのではないかと思います。この辺はまさに画像生成AIを何かを作るための「ツール」として使いたい方向けの用途でしょう。
{kind=link}
▲こういうやつもできるよ
6.終わりに
非常に大きな発展性を秘めたLayerDiffusion。いろいろと実験して感じたのは、「何のモデルを使うか」が非常に重要ということでした。例えば、「スマホを持った手」の透過素材を入手したいときにAnimagineXL3を使うと、キャラクターの正面絵ばかりが出てしまうといったように、指示通りの絵が出るモデルをちゃんと選んでいるか?というのがとても大切です。
また、上手にプロンプト指示ができないと、どこをどのように切り出せばいいのかAI側も迷ってしまって、このように中途半端な透過結果になってしまうことも多くみられました。
{kind=link}
特に人物ではないものの透過素材を得たいのであれば、中央にそのオブジェクトのみがぽんと置かれるようなプロンプトとモデル選びをきちんとしないといけない印象です。背景が描かれてしまわないよう、simple backgroundなどを使うのも効果的なように感じました。
また、前述したとおり、LayerDiffusionをオンにすると、オフのときとは異なる画像が生成されます。通常生成に比べてクォリティが落ちていると感じる場面もあったので、生成物の品質が落ちていないかもきちんとチェックする必要がありそうです。高解像度補助を使うことは可能でしたし、今後image2imageにも対応するとのことでしたので、このあたりは発展に期待したいところです。
・Controlnetとも併用できる
これはまだ研究しきれていませんが、Controlnetとの併用もけっこうできるようでした。scribbleなどでざっくり物体の位置を指示することで、描きたいものの安定性を上げられる可能性があります。SDXL用のControlnetは1.5系ほど使いこなせていないのですが、用途によっては効果的に組み合わせられそうに感じました。
前景と背景を分離して生成することで、より意図通りの物語性(最近SNSではナラティブという言葉がよく使われますが)を表現することは、従来から検討されてきたAI絵の大きなテーマの一つです。前景や各オブジェクトが背景と分離されたレイヤーとして得られることで、加筆修正やエフェクトを掛けるのも楽になりますし、これまでにない表現ができるようになりそうですね。引き続き開発が進むようですので、より発展した使い方を検証していきたいと思っています。
・今後の更新について
さて、今月は先月に引き続いて更新頻度を高めていきたいと思っています。「AIイラストが理解る!」の入門記事を2024年3月版にアップデートするのがまず大きなやりたいことですが、そのほか
・NovelAIv3を使った線画生成(or白黒マンガ絵生成)のやり方について
・線画を「AI着色」する現時点で最適の方法検証
・AIユーザーが理解すると捗る「光と影と反射光」の知識
・NovelAIの新機能「バイブストランスファー」の使い道
・背景だけをAIに描かせる方法(LayerDiffusionとその他の手法の比較検討)
・AI絵と手描き絵を馴染ませる手法
・SDXL向けControlnetの総覧
・AI絵だけやってたら副産物的に絵が描けるように()なった話
…といったものを順次書いていきたいと思っています。2月は「超辞典」の編纂に捧げてしまったので、今月は通常記事の更新頻度をさらに高めて、FANBOX全体の有用性を大いに上げる月にしたいので、どうぞよろしくお願いいたします。
それではまた近いうちに。スタジオ真榊でした。
Files