Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

AnimagineXL3.0でSDXLデビュー!導入法からおすすめ設定、サンプラー選びまで (Pixiv Fanbox)
Content
こんにちは、スタジオ真榊です。今回は革新的な精度で話題を席捲したStableDiffusionXL(SDXL)ベースのアニメ調モデル「AnimagineXL3.0」特集ということで、主にこれまでSD1.5系で生成してきたユーザー向けに、SDXLの入門記事から導入方法、XL用のおすすめ設定、プロンプトの基本、サンプラー比較などをまとめた記事をお届けします。
controlnetや各種拡張機能、プロンプト辞典の大刷新も含めた複数回の連載を想定しており、今回はその第一回「SDXLデビュー編」となります。
2024.02.10 AnimagineXL3.0の流行後、特定のプロンプトを使用したときだけ謎の絵柄崩壊(意味不明な画像が出力される)が報告されていましたが、hakomikanさんの検証とスクリプト公開によって解決しました。これに伴い、該当部分を差し替えています。
目次
前書き:待ち望まれていた決定版
SDXL利用に必要なグラボは?
SDwebUIで「AnimagineXL3.0」を動かしてみよう
SDwebUI上での使い方
SDXLの基本サイズ設定
おすすめスケール・ステップ・サンプラー
AnimagineXL3.0のプロンプト記述
▶【重要】版権キャラクター再現と著作権
▶絵柄崩壊
▶クォリティタグ
▶ネガティブプロンプト
▶画風の年代指定
▶Refinerについて
AnimagineXL3.0生成テスト
サンプラー比較
サンプラー考察
▶【脱線】DPMとかKarrasって結局何なの?
高解像度補助比較
人数変化実験
Adetailer検証
終わりに
前書き:待ち望まれていた決定版
2023年7月にデビューしたSDXL1.0モデルは、デフォルトの画像生成サイズが従来モデルの4倍となる1024x1024pxでトレーニングされており、画質や生成精度が飛躍的に向上しているのが特徴です。これまで「小さく出して大きくアップスケールする」が画像生成の基本だったのに対し、SDXLモデルでは最初から高解像度で生成しても、人体が奇形化したり、背景がおかしくなったりしないのが最大の利点と言えるでしょう。
一方で、必要とするGPUメモリ(VRAM)が増加していることや、SD1.5系に比べるとCheckpointや各種拡張機能、追加学習ファイルなどが発展途上にある(SD1.5用のLoRA、Controlnetなどが互換しない)点がウィークポイント。nsfw生成が苦手だったり、高価なグラボがないと快適に振り回せないことなどもあって、なかなか従来モデルからの「移住」が進まない状況にありました。
そんな中、先行して登場したのがSDXLベースでトレーニングされたNovelAIの「v3」。v2以前に比べて驚異的な精度でアニメ調イラストを生成できることから、改めてSDXLの潜在能力を界隈に知らしめることになりました。ControlnetやLoRAなど各種拡張機能を使えるローカル環境でも、NAIv3と同じような精度で使えるSDXLベースのアニメ調モデルが待ち望まれる中、颯爽とデビューしたのが、今回紹介する「AnimagineXL3.0」というわけです。nsfw画像の生成にもしっかり対応しており、ジェネリックNAI的な立ち位置を期待している方が多いのではないかなと思います。
SDXL利用に必要なグラボは?
SDXLは前述の通り、かなり高性能なグラフィックボードを要求される点に注意が必要ですので、本題に入る前に必要スペックについて触れておきたいと思います。グラフィックボードの比較解析と言えば「ちもろぐ」さん。SDXLの解析もしてくださっており、詳しくはリンク先の該当箇所をお読み頂くのが早いと思います。
スタジオ真榊の環境は最近、3万9000円~のRTX3060(12GB)から18万円~のRTX4080(16GB)に乗り換えましたが(下記記事参照)、いまのところ全くストレスなくSDXLでの生成ができています。
ちなみに、後述するように「--medvram」や「--lowvram」オプションを使えば、VRAM不足のグラボでもSDXLを取り回すことは可能です。コスパ最強のスタンダードモデルRTX3060(12GB)でも、「非常に快適」とは言えないまでも生成は問題なく行えます。StabilityAIはVRAM8GBのコンシューマ向けGPUから生成が可能と説明していますが、「12GBが快適利用できる最低ライン」「できれば16GBほしい」「24GBから万全」というのがリアルなところではなかろうかと思います。12GBの場合、まだ1.5系のほうがメリットが上回るという方が多いのではないでしょうか。
RTX3060から4080に変えたら速度〇倍?stablediffusion環境を再構築した話

こんにちは、スタジオ真榊です。今日はソフトでなくハードのお話で、グラボを23万円のRTX4080に変えたらどれくらい速度が変わるのか?というのを各種比較実験でご報告したいと思います。 今年1月下旬にRTX3060(VRAM12GB)を5万円超(当時の市場価格)で購入し、楽しく画像生成を続けてきたのですが、今回ひょんなこと...
NVIDIAは2024年1月に「GeForce RTX 4080 SUPER」「GeForce RTX 4070 Ti SUPER」「GeForce RTX 4070 SUPER」の3製品を発表したばかり。この中では、VRAM16GBの4070Ti SUPERが15万円前後で販売されており、SDXLデビューと同時にRTX3060などからアップグレードする場合は選択肢になるのではないかと思われます。
SDwebUIで「AnimagineXL3.0」を動かしてみよう
さて、こちらのFANBOXをご覧の皆様はautomatic1111版のSDwebUIをお使いの方が多いと思いますので、まずはa1111SDwebUIで「AnimagineXL3.0」を動かしてみるところから始めてみましょう。
1.「AnimagineXL3.0」とSDXL用VAEをダウンロード
こちらのリンク先から「animagine-xl-3.0.safetensors」をダウンロードし、SDwebUIの「models\Stable-diffusion」フォルダ内に保存します。LFSと書かれた右隣の「↓」ボタンを押せばOK。
SDXLでは1.5系と異なる専用のVAEが必要ですが、AnimagineXL3.0にはVAEが同梱されているようで、「none」「automatic」設定でも問題なく生成することができます。ただ、SDXLデビューするのであれば今後のためにも専用VAEを持っておいて損はないので、こちらもついでにダウンロードしておきましょう。下記リンク先にある「sdxl_vae.safetensors」を↓ボタンからDLし、「models\VAE」フォルダに保存しておきます。
ちなみに、SD1.5用のVAEを使ってSDXLモデルで生成すると、このように画像全体がジャギってしまいます。
{kind=link}
2.SDwebUIをバージョンアップ
a1111版SDwebUIは「ver.1.6.0」からSDXLを完全サポートしていますので、それ以前のバージョンをお使いの方はアップデートの必要があります。今更かもしれませんが、アプデのやり方は以下の通り。
▶Gitを使って自力インストールした方
webUIのインストールフォルダの何もないところを右クリックして「Open Git Bash Here」を選択し、「git pull」と入力するいつもの方法です。
▶sd.webui.zipのパッケージでインストールした方
同梱されているupdate.batを実行しましょう。
▶StabilityMatrixをご使用の方
「Packages」タブから三点リーダ「︙」をクリックし、Check for Updatesを選べばOKです。
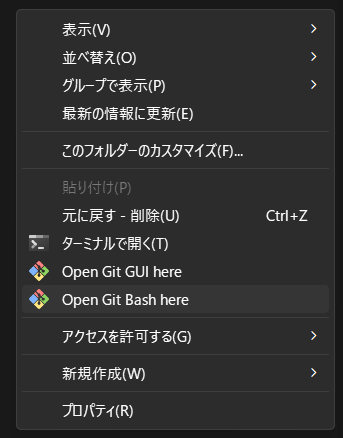
SDwebUIの大規模アップデート後は拡張機能との整合性などで動作が不安定になることがあるため、リリース後すぐにアップデートするのを嫌うユーザーが多いです。気になる方は、アップデート前のコミットハッシュ値を書き留めておくことをお勧めします(webUIを立ち上げ時、コマンドプロンプトにCommit Hash:~と表示される英数字部分です)。最新版で問題が発生した場合は、この文字列を使ってもとのバージョンにダウングレードすることができます。
{kind=link}
▲コレ
ダウングレードの方法は簡単で、「git pull」の代わりに「git checkout(ハッシュ値)」と入力するだけ。例えばコミットハッシュ値が「cf2772fab0af5573da775e7437e6acdca424f26e」なら「git checkout cf2772fab0af5573da775e7437e6acdca424f26e」と入力すればOKです。(ちなみにこれはver1.7.0のコミットハッシュ値です)
3.Diffusersなどを導入
さらに、AnimagineXL3.0の利用に必要な環境を構築する必要があります。次の手順で、SDwebUI環境に最新のDiffusersライブラリとtransformersパッケージをインストールしてください。環境構築にはGit Bashを使うので、StabilityMatrixなどでSDwebUIを導入したWindowsユーザーはこの期にGit for windowsをインストールしておきましょう(下記の記事が参考になります)
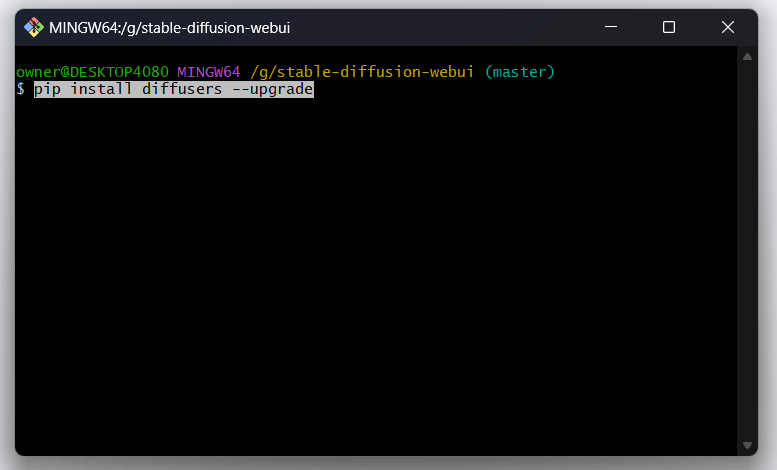
①webUIのインストールフォルダの何もないところを右クリックして「Open Git Bash Here」を選択(Win11の方は"その他のオプションを確認"を押すと表示されます)
{kind=link}
②「pip install diffusers --upgrade」(左右のかぎかっこを含まない)を入力してENTERキーを押下します。「Ctrl+C」や「Ctrl+V」を使うと「^[[200~」という文字列が頭についてしまってうまく貼り付けられませんので、右クリックを使って貼り付けましょう。下記のようになっていればOKです。
{kind=link}
※「Successfully installed diffusers~」と表示され、再び「$」マークが表示されてコマンド入力できるようになればインストール成功
③さきほどと同じように、「$」マークの横に「pip install transformers accelerate safetensors」(同)を入力してENTERキーを押下。これも貼り付け方は先ほどの注意点を踏まえて入力してください。
(4.必要に応じてVRAM削減のコマンドライン引数を指定する)
SDXLを利用するのにVRAMが足りない場合は、webUI起動時に使う「webui-user.bat」で特定のコマンドライン引数を指定することで、VRAM消費量を削減することができます。xformersを導入したときと同様、「set COMMANDLINE_ARGS=」以下に「--medvram-sdxl」を入れることで、SDXLを使用したときのみVRAM消費量を削減する設定になります(GPUからCPUへモジュールを転送することで、生成速度と引き換えにVRAM消費量を抑制する仕組み。--lowvram-sdxlだとさらにCPUへ転送するモジュール量が増えますが、生成速度はさらに遅くなります)
VRAM不足による「CUDA out of memory」エラーが発生しない場合は速度が殺されるだけですので、まずは通常通り生成してみて、SDXLを普段使いする上でVRAM不足となるかどうかを確かめてみることをお勧めします。
これで準備は終了です。SDwebUIを立ち上げてみましょう。
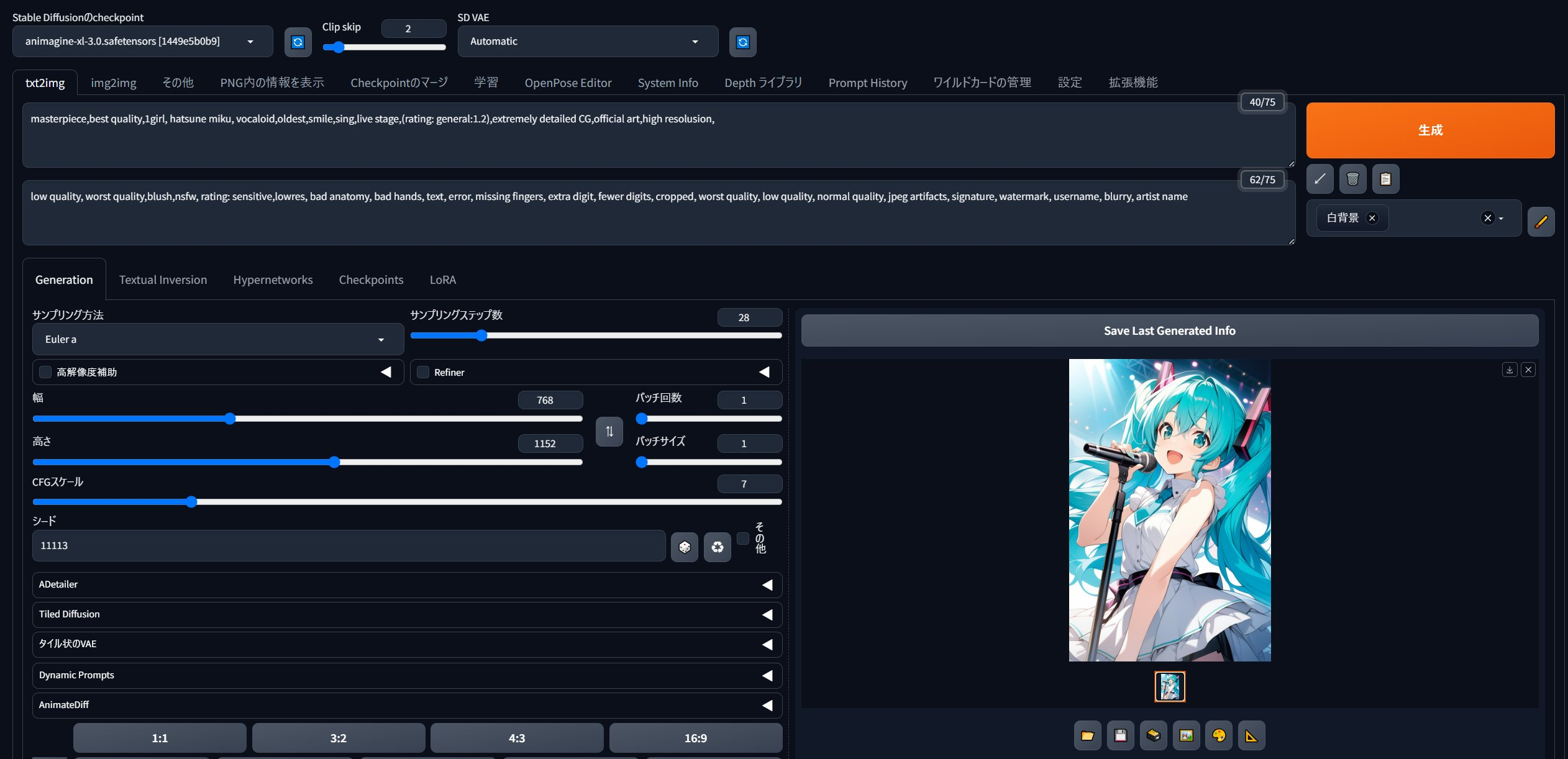
SDwebUI上での使い方
{kind=link}
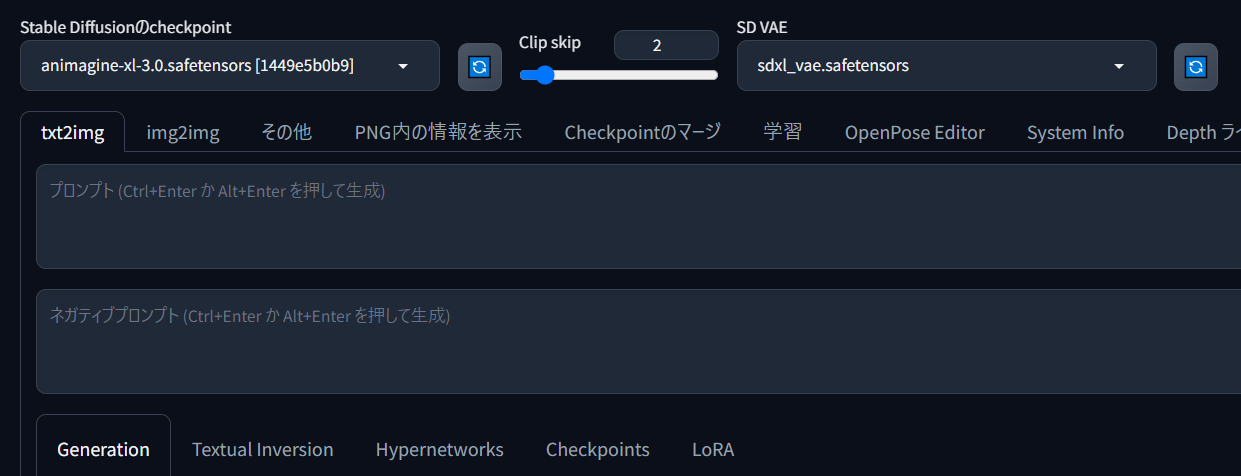
このように、checkpointに「animagine-xl-3.0.safetensors」を、SD VAEに「sdxl_vae.safetensors」を設定します。
SD VAEのウィンドウがこの位置に表示されていない方は、【設定▶インターフェイス▶クイック設定】から、下記のように「sd_vae」を追加しておくと切り替えが便利です。
{kind=link}
SDXLの基本サイズ設定
基本の生成サイズは基本が「1024x1024px」で、これより小さいサイズで生成すると精度が下がる傾向にあります。1024x1024=1048576ピクセルが推奨値となるので、縦横比5:4や7:4の画像だと近似値は以下のようになります。
▶正方形(基本):1024x1024px
▶縦長:1152x896px(5:4)1344x768px(7:4)1216x832px(13:19)
▶縦長:896x1152px(4:5)768x1344px(4:7)832x1216px(13:19)
SD1.5系でおすすめされていた768x512と同じ3:2比率だと1254x836px(近似値)となりますが、SDwebUIの仕様でデフォルトのスライダーでは指定できません。個人的には、3:2の比率が使い勝手がよいので、1152x768pxサイズか、1216x832pxで生成することが多いです。
縦横比は構図を決定する上で非常に重要なので、出したい構図に応じて慎重に検討しましょう。生成サイズをボタンで選べる拡張機能「Aspect Ratio selector」に各サイズを登録しておくと、呼び出すのが楽なのでオススメです。
ダブルで便利!一発出し拡張機能を入れておこう

こんばんは、スタジオ真榊です。今夜は「WebUIの便利機能をマスターしよう!」に引き続き、UI周りの拡張機能について紹介していきたいと思います。ご紹介するのは「Aspect Ratio selector」と「Config-Presets」の2本立て。それぞれ、お気に入りのキャンバスサイズや各種生成設定を記憶しておいて一発出ししてくれる便利...
おすすめスケール・ステップ・サンプラー
次に、スケール・ステップ・サンプラーのおすすめ設定についてです。公式によると、下記の設定でより良い結果が得られたとのこと。
▶CFG Scale:5~7程度
▶ステップ数:30以下(低めが推奨されています)
▶サンプラー:Euler Ancestral(=Euler Aのこと)
SD1.5では生成が早く結果も比較的まとまっていた「DPM++ 2M Karras」が人気でしたが、こちらも問題なく生成できます。EulerAはステップ数を上げるごとに絵が変化していくサンプラーなので、ステップ数は比較的低めが推奨されているのかなと想像します。サンプラーについてはあとで全30種の比較実験をしますので、そちらも参考にしてください。
AnimagineXL3.0のプロンプト記述
このモデルはNovelAIv3をヒントにトレーニングされており、以下のような語順でプロンプト入力することが推奨されています。
【1boy/1girl, (キャラクター名), (作品名), 以降その他のタグ】
つまり、冒頭は1boy/1girlといったメインモチーフの属性で始め、版権キャラクターの場合はすぐ次に「キャラクター名タグ」、その次に「作品名タグ」を入れて、その後に「looking at viewer」や「blond hair」といったその他の要素を続けていくのが良いということ。たとえば「1girl, hatsune miku, vocaloid,smile,sing,live stage...」といった語順になります。
プロンプト順が版権キャラを生成することを前提にされたものとなっていることからもわかる通り、NovelAIv3のように、LoRAなしでも相当多くの版権キャラクターを再現することができるのが「AnimagineXL3.0」の特徴です。
▶【重要】版権キャラクター再現と著作権
AnimagineXL3.0はNovelAIと同様、多くの日本の版権キャラクターの容姿を学習しており、生成物の扱いには著作権法上の注意が必要です。文化庁の「AIと著作権に関する考え方について(素案)」にも書かれていた通り、生成物に既存の著作物との類似性・依拠性があり、その著作物の「表現上の本質的特徴を直接感得」できてしまう場合、その生成物の利用は著作権侵害となります。そうした生成物を私的利用の範囲を超えて利用する場合(SNSで公開など、商用/非商用問わず)は、著作権者から提訴されるリスクがあることを十分に理解した上で行うようにしましょう。
{kind=link}
版権キャラクターの二次創作をウェブなどで公開する行為については、描画手法が手描きかAIかに関係なく、大半が著作権侵害となりえます。SNSでは日常的に版権キャラの二次創作イラストを見かけますが、これは版権者にとってビジネスの障害にならないファンアートの文脈であることや、ファン活動を法的に咎めるとビジネス上のデメリットが大きいという合理的理由があるために黙認されているだけです。
私も「機動戦士ガンダム水星の魔女」が大好きで、Xで二次創作活動を行っていますが、こうした行為は版権側が「提訴したメリットの方が上回る」と判断した場合、多額の損害賠償責任が生じる恐れがあることを十分に理解した上で、自己責任で行う必要があると言えます。また、投稿内容がファンアートの文脈から外れるほどにその可能性は高まる点にも注意が必要です(もちろん、版権側が公表している二次創作ガイドラインを守っている場合は問題ありません)。
AIと著作権の考え方については、こちらの全体公開記事で「素案」の分かりやすい解説を行っていますので、参考になればと思います。
「AIと著作権」文化庁がパブコメ募集開始 何をどう書く?ポイントまとめ

こんにちは、スタジオ真榊です。今回は全体公開記事ですので最初に自己紹介しますと、22年10月からAIイラストの研究記事を100本以上書き続けている変な人です(自己紹介終わり)。 さて、本日からいよいよ「AIと著作権に関する考え方(素案)」に関する文化庁のパブリックコメント募集が開始されました。総務省も「AI事...
▶絵柄崩壊報告とその解決
AnimagineXL3.0では、プロンプト指示によってはこうした独特の崩壊をすることがあります。
スタジオ真榊で生成していた際も、たまにこうした現象に遭遇しました。例えば、
「PP:masterpiece,best quality,1girl, hatsune miku, vocaloid,newest,smile,sing,live stage,(rating: general:1.2),extremely detailed CG,official art,high resolusion」
こちらのプロンプトで黒字部分を変更するX/Y Plotで実験していたところ、下図のような生成結果が出ました。
{kind=link}
興味深いのは、この初音ミクプロンプトだとどういう位置に入れても「newest」以外のタグがあると必ずこのように崩壊してしまうのですが、別の被写体(ただの1girlや別キャラクターなど)を指定していると問題なく生成できる点です。少しプロンプトを変更すると生成できることも多く、しばらく謎の現象としてSNSで話題になっていました。
<解決>
2024年2月9日、SDwebUI用のさまざまな拡張機能を提供してくださっているhakomikanさんが原因を突き止め、見事に解決してくださいました。こちらのnoteの最後に絵柄崩壊を防ぐスクリプトを公開していただいています。
スクリプトを通常の拡張機能のやり方でインストールしたのち、設定欄から該当部分に☑を入れるだけです(詳しいインストール・機能ONの方法はsd-webui-prevent-artifactのgithubに書かれている通り)。さきほどの崩壊した一枚をもう一度同じ設定で生成してみると…
{kind=link}
このように、ちゃんとプロンプト通りの生成ができました。本当にありがたい限りです!
{kind=link}
▶クォリティタグ
AnimagineXL3.0は次のようなタグで教師データとなるイラスト群をレーティングしており、上位をポジティブプロンプトにすることで生成画像の質を向上させることができます。(ネガティブに下位のlow quality、worst qualityを入れることでも効果があります)
傑作: masterpiece
最高品質: best quality
高品質: high quality
普通品質: normal quality
低品質: low quality
最低品質: worst quality
公式は、高品質な画像を求める場合はポジティブプロンプトの冒頭に「masterpiece, best quality」を入れることを推奨していますが、一方で「masterpiece」のタグ付けで学習された教師データには成人向け描写が多く含まれていることから、nsfw的な雰囲気が出てしまう可能性があると注意しています。また、それぞれのタグに顔立ちを固定する効果があるように感じており、いわゆる「マスピ顔」現象が起こる点にも留意が必要です。
全年齢向けの生成を行いたい場合、ネガティブプロンプトに「nsfw, rating: sensitive」を、ポジティブプロンプトには「rating: general」を入れることで回避できるとしています。(これもあとで実験します)
▶ネガティブプロンプト
公式が提示しているネガティブプロンプトの凡例は以下の通り。さきほどのクォリティタグでいう下位のlow quality、worst qualityが入っており、こうしたNPがないと、せっかくの性能が活かせずぼやけた画像になります。
nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
冒頭に「nsfw」が入っていますが、もちろんnsfw画像を生成したい場合は外すのを忘れないようにしましょう。
▶画風の年代指定
次のような独自の年代指定タグを入力することで、その時代ごとの流行に即した画風にすることもできるとしています。これはNovelAIv3でも同様の試みが行われていたのでおなじみですね。
newest:2022〜2023年
late:2019〜2021年
mid:2015〜2018年
early:2011〜2014年
oldest:2005〜2010年
X/YPlotで入れ替えると、以下のように絵柄変化します。いわゆる通常時の「マスピ顔」は釣り目でNewestの印象が強いので、好みで調整するのがよいかと思います。
{kind=link}
▶Refinerについて
SDXLのモデルには通常の「baseモデル」とは別に、高品質化のための「refinerモデル」があり、2段階の処理によってより高画質な画像を生成できる特徴があります。通常の画像生成でも、いったん生成した後にその画像をi2iアップスケールして高精細にすることがよく行われてきましたが、それを一工程で行うようなイメージです。
ただ、Refinerモデルを使った生成はフォトリアルな画像を生成する場合にはうまくいくようですが、アニメ調イラストの場合、個人的にさほどメリットが感じられていません。AnimagineXL3.0を使用する際も、特にRefinerモデルを使用しなくとも高精細な画像を得ることができています。
上記リンク先からRefinerモデル「sd_xl_refiner_1.0.safetensors」を入手できますので、関心がある方は比較してみることをお勧めします。
保存先は通常のCheckpointと同じ「models\Stable-diffusion」フォルダ。高解像度補助の横にある「Refiner」にチェックを入れてタブを開き、「Checkpoint」の欄から読み込めばOKです。全体のステップの何割からRefinerモデルで生成するかを「Switch at…」欄で指定することもできます。0.8なら全ステップ数の80%段階からRefinerモデルに切り替わります。
{kind=link}
AnimagineXL3.0生成テスト
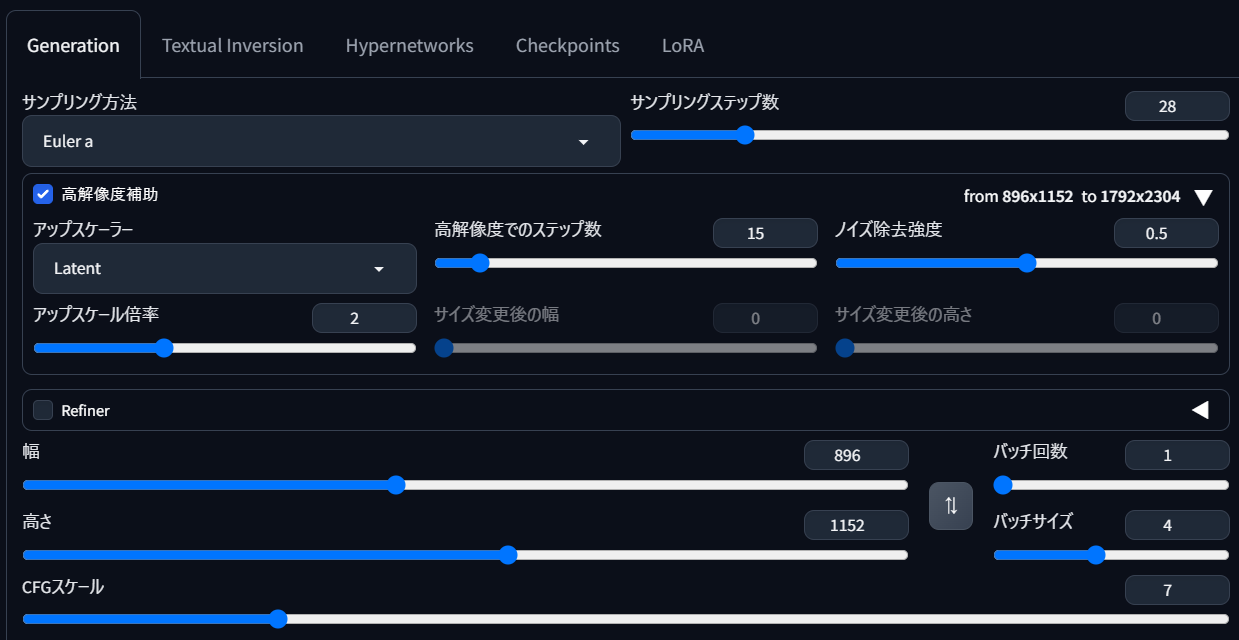
では、実際に生成テストを行ってみましょう。まずはクォリティタグ、ネガティブプロンプトともに指定せず、ただの「1girl」で生成します。細かな設定値は以下の通り。高解像度補助(Hires)なしで、1024x1024pxの規定サイズで生成しています。
{kind=link}
生成された画像はこちらです。クォリティタグもネガティブプロンプトもないため、低劣な画像となっています。
{kind=link}
ちなみに、RTX4080利用環境で4枚生成に要した時間は33.8秒でした。試しにSD1.5系モデルでHiresをONにし、1512×1024pxで生成すると36秒前後で4枚生成できたので、おおむね生成時間の体感は同じくらいに感じます。
次に、前述した公式推奨のネガティブタグ(下記)を追加します。ポジティブプロンプトはそのまま。
NP:nsfw, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
{kind=link}
一気に高画質になりましたね!
今度はさらに、公式推奨のクォリティタグ「masterpiece,best quality」をポジティブプロンプト冒頭に追加し、「masterpiece,best quality,1girl」とします。すると…
{kind=link}
このように、画質がさらに上がった一方で、一気にnsfwなムードが漂ってきました。これが公式の説明していた「masterpiece」の影響です。学習させた教師データ画像のうち、masterpieceタグに分類されたイラストは多くがnsfw画像だったため、「1girl」タグでもこのようなムードになってしまうのですね。また、どのイラストもツリ目がちでやや目と目の間に距離のある特徴的な顔立ちとなっており、こちらがAnimagineXL3.0の「マスピ顔」と言えると思います。
全年齢向けの生成を行いたい場合、ネガティブプロンプトに「nsfw, rating: sensitive」を、ポジティブプロンプトには「rating: general」を入れることが推奨されているので、その通りにしてみましょう。
{kind=link}
生成結果はこちら。多少露出度は低下したものの、依然「masterpiece」タグの影響で頬染めが強く出ており、えっちなムードが消し切れていません。
{kind=link}
AnimagineXL3.0の学習データは次のようなタグ付けで管理されており、この最上位の「masterpiece」の影響でこうしたムードが醸し出されていることがうかがわれます。
傑作: masterpiece
最高品質: best quality
高品質: high quality
普通品質: normal quality
低品質: low quality
最低品質: worst quality
masterpieceタグをあきらめ、「best quality,1girl,(rating: general:1.2)」としたところ、このような生成結果が得られました。
{kind=link}
4枚とも上記イラストとかなり似通ったキャラクター容姿が生成されていますが、えっち度は控えめになっています。さらに「blush(頬染め)」をネガティブ冒頭に追加したところ、このような結果となりました。
{kind=link}
最終的なプロンプトは以下の通り。全年齢イラストを生成したいときの基本タグとして、適宜修正しながら活用すると良いかと思います。
PP:best quality,1girl,(rating: general:1.2)
NP:blush,nsfw, rating: sensitive,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
サンプラー比較
次に、看板娘ミナちゃんのプロンプトを使って、おなじみのサンプラー比較を行います。プロンプトは以下の通り。
PP:best quality,1girl,solo,portrait,(red under-rim_eyewear:1.3),navy school uniform,navy serafuku,ponytail,short sleeves,navy pleated skirt, white line,shiny skin,purple eyes,black hair,white ribbon,(rating: general:1.2)
NP:blush,nsfw, rating: sensitive,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name
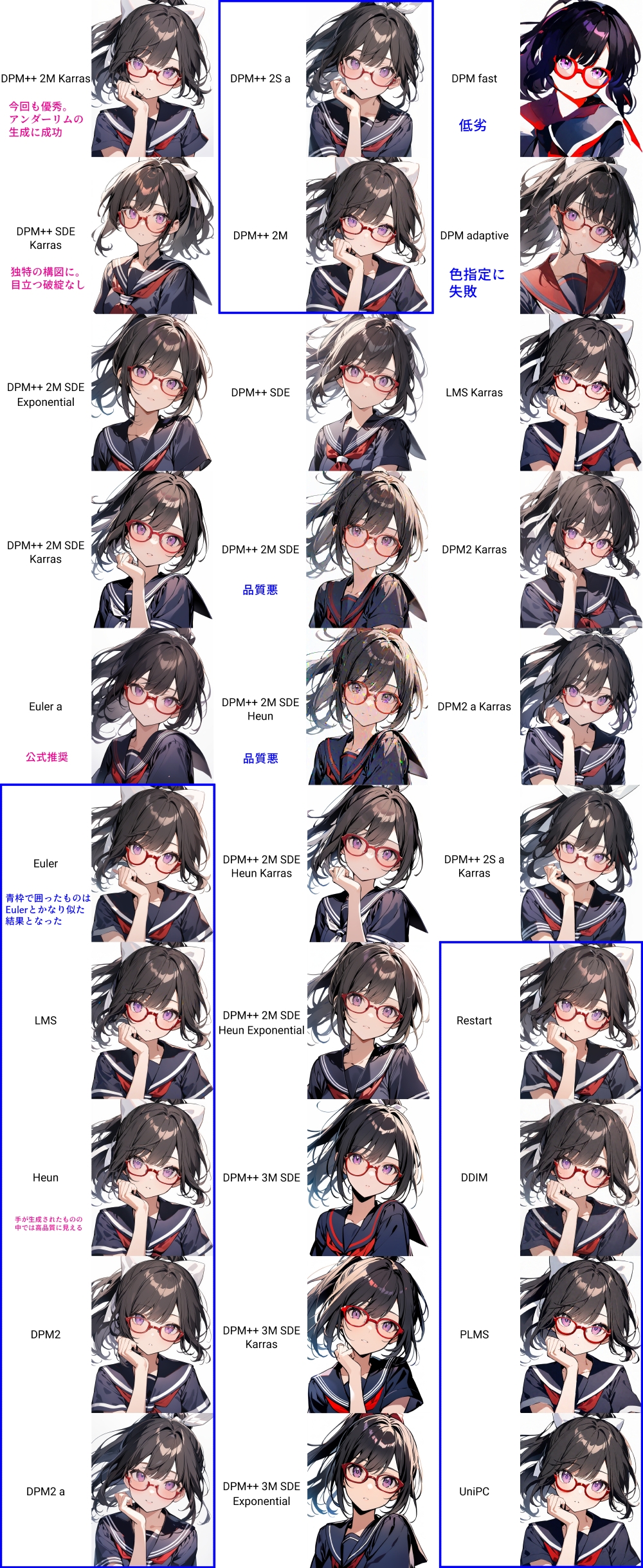
爆速生成が可能なLCM-LoRA用のサンプラーを除く全30種類につき、こちらの設定で総当たりしました。
{kind=link}
こちらがその一覧です。「Euler」とよく似た構図になるものが多かったため、そうしたサンプラーは青枠で囲ってあります。
{kind=link}
サンプラー考察
このように、公式推奨の「Euler A」、1.5系でも人気の「DPM++2M Karras」は問題のない出来となりました。その他で目立ったのは、前述のとおりEulerに似た構図のものが多く出たこと。ミナちゃんプロンプトの難しいポイントとして、under-rim_eyewear(アンダーリム眼鏡)の再現がありますが、euler系の構図のものは比較的成功率が高いように見えます。中でも「Heun」は高品質に見えました。
30種の中で独特の構図が出たのは「DPM++2M SDE Karras」。こちらは「DPM++2M Karras」に比べて多少生成に時間がかかるものの、高品質な結果になるとしてアニメ調イラスト生成時に好まれていたサンプラーですが、AnimagineXL3.0とも相性がよさそうに見えます。
逆に明らかに品質が悪かったのは、DPM++2M SDE Heun、同Karras、DPM Fast。画像にjpegの粗のように見えるムラが出てしまいました。
次に、特によさげだったものを抽出し、先ほどと異なる2種類のSeed値で実験しました。公式推奨の「Euler A」だけが眼鏡の赤がセーラー服に流れず、やはり相性の良さを感じさせる結果となっています。
{kind=link}
【脱線】DPMとかKarrasって結局何なの?
サンプラー名によく使われる用語をざっくり紹介しますと、「DPM」とはDiffusion Probabilistic Modelsの略で、ノイズを加えて除去を繰り返すことで高精細にしていく拡散確率モデルであることを示しており、「DPM++」はDPMの改良版もしくは派生型であることを指しています。よく見かける「Karras」は実は人名から来ていて、NVIDIAの特別研究者であるTero Karras氏によるノイズ除去技術を取り入れたサンプリング手法。「SDE」は確率微分方程式(Stochastic Differential Equation)を使い、より自然な生成結果を目指したものです。
「Heun」はオイラー法の改良版である「ホイン法」という数値解析手法を利用したもので、正確な近似値を導き出すのに有効(つまりより高精度な生成結果につながる)とされています。サンプラー名に「A」とつくのは「Ancestral」のことで、ステップごとにノイズを加えて除去することで品質を上げる試みですが、逆に言えば絵が収束しにくいわけで、ステップを上げていくと絵が変わっていく特徴があります。NovelAIにある「Euler Ancestral」はつまり「Euler A」のことだったわけですね。
正直、こうした理論について門外漢の一般ユーザーとしては、生成結果で見分けるほかありません。これまで通り、こうした総当たり実験や経験値に基づいて、Checkpointごとに好みのものを選んでゆく形でよいかと思います。
高解像度補助比較
次に、高解像度補助についても触れておきます。Refinerは前述したとおりさほど強いメリットがなさそうなので、AnimagineXLでもSD1.5と同様、高解像度補助(Hires)による高精細化が有効かどうか試すことにします。
まずはHiresをOFFにした状態で、こちらの4枚生成を用意しました(先ほどのプロンプトにdouble v,smile,teethを加えたものです)。この時点でSD1.5系に比べて高精細に手を生成できていることが分かりますが、高解像度補助でどのように変化するでしょうか。
{kind=link}
このように15ステップで2倍にアップスケールする設定で、ノイズ除去強度は0.5~0.7で比較してみます。
{kind=link}
<ノイズ除去強度0.5の場合>
{kind=link}
一見全く同じ結果のように見えますが、Latentの「Nearest」「Nearest Exact」ははっきりとしたがたつきが残りました。Latent系はノイズ除去強度が足りないとこのような結果になりがちで、さらに強めれば消える可能性がありますが、その分ノイズを上乗せしているため、元画像からの変更が大きくなります。個人的に普段使いしている「4xanimesharp」や「R-ESRGAN 4x+Anime6B」は期待通りの結果となっていますので、このあたりを使うのが良いかなと思います。
こちらが原寸大の比較図ですので、詳しく見比べたい方はこちらをご利用ください。
{kind=link}
<ノイズ除去強度0.6の場合>
よりノイズを加える強度を強め、「0.6」にしてみます。
{kind=link}
これも拡大しないとわかりにくいですが、指が増えてしまっていたり、眉毛が二重になってしまったりと、はっきりとした不具合が出てしまっています。先ほど出ていたジャギは消えましたが、これでは実用に足りません。
{kind=link}
<ノイズ除去強度0.7の場合>
0.6で既に不具合が出てしまいましたが、念のためよりノイズを加える強度を強めて「0.7」にしてみます。
{kind=link}
ご覧の通り、やはり残念な結果となりました。AnimagineXL3のマスピ顔は目が小さめで、目と目の間が広く、ややリアル調の顔立ちであることが災いし、目の位置はそのままに目の形だけがアップスケール修正されてしまうことで、このような不自然な顔立ちになってしまっているのかなと思います。
{kind=link}
結論として、おおむねノイズ除去強度は0.5を最大として、変化度の少ない「4xanimesharp」や「R-ESRGAN 4x+Anime6B」といったアップスケーラーを用いるのが無難ということになりそうです。そもそもSD1.5系と違い、Hiresなしの一次生成で完成度が高く作れるのがSDXL系の強みと言えますので、一次生成から生成時間を延ばすよりはまず1024pxサイズで絵柄を完成させ、image2imageやTileなどでサイズを調整するのが良いかなと感じます。
人数変化実験
公式のプロンプト例では「1boy/1girl」を最初に置くことが強調されていました。被写体が1人の画像を主体として学習していることが想像されるのですが、モチーフを複数人指定した場合は崩壊してしまうのか、それともきちんと描けるのか検証してみます。
プロンプト「best quality,1girl,(rating: general:1.2)」を基本として、1girl部分を順に「1girl▶1girl and 1boy▶couple▶3girls▶many girls▶crowd」と変更してみました。
{kind=link}
おおむね指示が効いていることがうかがえる結果となりました。3girlsが2人になってしまったり、coupleが3人になってしまったりはしてしまいますが、SD1.5系よりはプロンプトの利きが強いと感じます。ただ、どういう画角でどういう姿勢のどんなイラストかを指定していないので、ややばらけた結果となっていますね。
また、人数が増えると一人当たりの顔の大きさが小さくなるため、クォリティが下がっていることもうかがえます。では、こうしたときに役立つ拡張機能「ADetailer」はAnimagineXL3.0でも効果的なのか確かめてみます。
※手や顔を抽出してピンポイントでアップスケールしてくれるADetailerについては、こちらの記事を参照のこと。
「ADetailer」が理解る!部位別詳細化と5つの「応用」

こんばんは、スタジオ真榊です。今回は「ハンドビューワー」を使った手の修正方法の記事で少し触れた、手や顔といった細部を自動修正してくれる拡張機能「ADetailer」の解説と研究をやっていきたいと思います。 ADetailer(After Detailer)は、通常の画像生成に引き続いてキャンバス内の顔や手といった部位を自動検出し...
Adetailer検証
一人当たりの顔や手のサイズが小さくなるように、このようなプロンプトを用意しました。
best quality,3girls,full body,wave hand,facing viewer,(rating: general:1.2)
{kind=link}
人数がぶれてしまっていますが、それぞれfullbodyにした影響で顔や手はモブ化してしまっています。これをADetailerを使ってどう変化するか試しました。ついでにプロンプト指示も施し、faceはsmileを、handには「open hand」をそれぞれ指定しました。
結果がこちら。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
顔のほうはどれも上手に笑顔にしつつ、つぶれていた部分を補完してくれています。ただ、手の方はもともと奇形になっていたものを綺麗に直すことはできず、最後の1枚などはやらないほうがマシだったような印象もあります。これはいずれもimage2imageの原理で描き直しているからで、もともとの形状に引っ張られてしまうのが原因。少なくとも、人数が増えて顔の細部がつぶれてしまう問題はADetailerで十分対応できそうですし、手についてはガチャか加筆、これまでもやってきた「雑塗りi2i」などの方法で修正したほうが有望かなと思います。
終わりに
初回からかなり長くなりましたが、AnimagineXL3.0の入門記事をまとめました。感想としては、やはり版権キャラクターの再現度の高さとnsfw力を兼ね備えつつSDXLの描写力を味わえる、ジェネリックNAIのようなモデルという印象です。特徴としては、「マスピ顔」が存在すること、年代タグである程度調整できること、プロンプトの利きがよいこと、比較的手の描写が得意であることなどが挙げられ、その一方でおそらくモデル由来のエラーとして、一定のプロンプトにあるタグを組み合わせることで画像全体が崩壊してしまう欠点があります。この点についてはかなり大きなマイナスポイントと言えるので、アップデートを待つほかないかなと思います。
また、下記の公式説明にもある通り、「動的」なポーズがやや苦手なようです。例えば、ウマ娘のキャラクターが走っているポーズを生成させたところ、従来モデルに比べてダイナミックさに欠けるというか、やや不自然なポーズになってしまうことがありました。
{kind=link}
また、このモデルはある独自のアートスタイルを保持するのではなく、さまざまな版権キャラクターやその画風に千変万化できることを優先してトレーニングされていることも大きな特徴かなと思います。
《NAIリーク問題を解決できるか?》
ところで、StableDiffusionモデルはバージョンごとに大きく分けて1.5系、2.1系、最新のSDXL系という3つの系統樹に分かれるわけですが、拡張機能や追加学習が最も充実し、先行して広く普及してきたのは1番古いSD1.5系と言えます。その一方で、入門記事「AIイラストが理解る」でも触れたように、黎明期のNovelAIハッキング事件によって多くの1.5系モデルに違法なリークモデル(NAIv1そのもの)がマージされてしまったことにより、1.5系モデルの繁栄自体が私企業への権利侵害の上にあるものだと指弾される状況にあったこともまた事実でした。
リークモデルと互換性がなく、混入の恐れがないSDXL系やSD2.1系の普及は、アニメ調AIイラストの宿痾と言えるNAIリーク問題を根本から解決する条件だっただけに、AnimagineXL3.0がSDXLへの移住を決定づける傑作モデルとなれるかどうかに注目が集まるところですね。
今回は全体を総覧する記事になりましたが、次回以降は各論ということで、NovelAIv3で強烈だったインペイント能力の高さがAnimagineXL3.0でも同じように活用できるかどうかや、SDXL用Controlnetの現状などについて順次検証していきたいと思います。
それではまた近いうちに。スタジオ真榊でした。
Files