Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

アップスケールが理解る!i2i/Tile/LoRA/Hires/Extraぜんぶ解説【15000字】 (Pixiv Fanbox)
Content
【2023/08/30更新】「AnimeSharp」「UltraSharp」の制作者さんより、商用利用不可のライセンスについてご回答を頂きましたので、該当部分に追記しました。
こんばんは、スタジオ真榊です。今回は、AIイラストを高画質にする「アップスケール」の方法についての大型まとめ記事をお届けします。
先日、FANBOXのメインコンテンツである「StableDiffusion超入門」をアップデートしたのと同時に、FANBOX全体の過去記事を見直しました。目につく古い情報はちょこちょこと書き直したのですが、イラストのアップスケール(高解像度化&高精細化)については総論的な記事が不備であることに気づいたので、今回はあらためて現状のアップスケール方法をおさらいしてみたいと思います。
【全体公開】AIイラストが理解る!StableDiffusion超入門

こちらの記事は2023年版のものです。特に理由がなければ、SDXLやForgeにも対応した2024年版の「AIイラストが理解る」をお読みくださいませ。 こんにちは!2022年10月からAIイラストの技術解説記事を連載してます、サークル「スタジオ真榊」の賢木イオです。この記事は、これまで投稿してきた100本(約40万文字)を超える...
アップスケールのやり方はそれぞれの個性や好みが出るところですし、フォトリアル系なのかアニメ調なのか、描き込み量を多くしたいのかそのままにしたいのかといったことによっても変わります。また、各設定値についても、おのおのの好みによって最適な調整は大きく変化するため、これといった「決定版」は存在しないのですが、本記事では界隈でよく使われている手法を総覧しつつ、最後に私のよくやるアップスケールのワークフローを紹介していければと思います。
///////////////////////////////////////////////////////////////////////////////////////////////////////////////
【目次】
キャンバスサイズ設定の基本
高解像度補助(Hires.fix)
追加アップスケーラーのススメ
アップスケーラーごとの違い
text2imgとimg2imgでモデルを変える「疑似マージ」
Extra欄でできる「そのままアップスケール」
CN「Tile」を使った高精細化
「やりすぎTile」を防ぐには
VRAM不足には「Tiled Diffusion with Tiled VAE」
- (1)Tiled Diffusion
- (2)Tiled VAE
- (3)実際の使用例
CN「Tile」×「Tiled Diffusion」
LoRAを使った高精細化
絵柄を極力変えたくない場合は
スタジオ真榊のワークフロー
終わりに
///////////////////////////////////////////////////////////////////////////////////////////////////////////////
キャンバスサイズ設定の基本
さて、アップスケールについて考える前に、まずは基本であるキャンバスサイズの話から入りたいと思います。
AIイラスト画像を生成する上で、キャンバスの縦横比は非常に重要な意味を持ちます。縦長のキャンバスなら、このように人物が単独で大きく映っているイラストが描かれやすく…
{kind=link}
横長なら、被写体が複数だったり背景が大きく映り込んだりしたものが描かれやすい傾向が現われます。
{kind=link}
上の2枚のイラストはどちらも全く同じ「1girl」から始まるプロンプトですが、2枚目は横長のキャンバスにしたために「1girl」というプロンプトを無視して2人目が生成されています。これは、学習データとなった無数のイラストに「横長のイラストは複数人が描かれていることが多い」という傾向が強く存在するため。男性キャラクターがなかなか出にくかったり、"looking away(向こうを向いて)"とどんなに強調しても"looking viewer"になってしまったりするように、キャンバスサイズによっても構図やキャラクターの配置は学習傾向による影響を受けます。
正方形からおおむね4:3くらいまでの比率なら生成結果が比較的安定しますが、極端な縦横比のイラストを描かせようとすると、キャンバスサイズに無理に合わせた構図になるため、人体が妙に「間延び」してしまったり、謎のオブジェクト(布状が多い)が現れたりするなど、構図が崩壊しがちになります。
{kind=link}
▲胴が長くなってしまい、布状のオブジェクトが出現した例
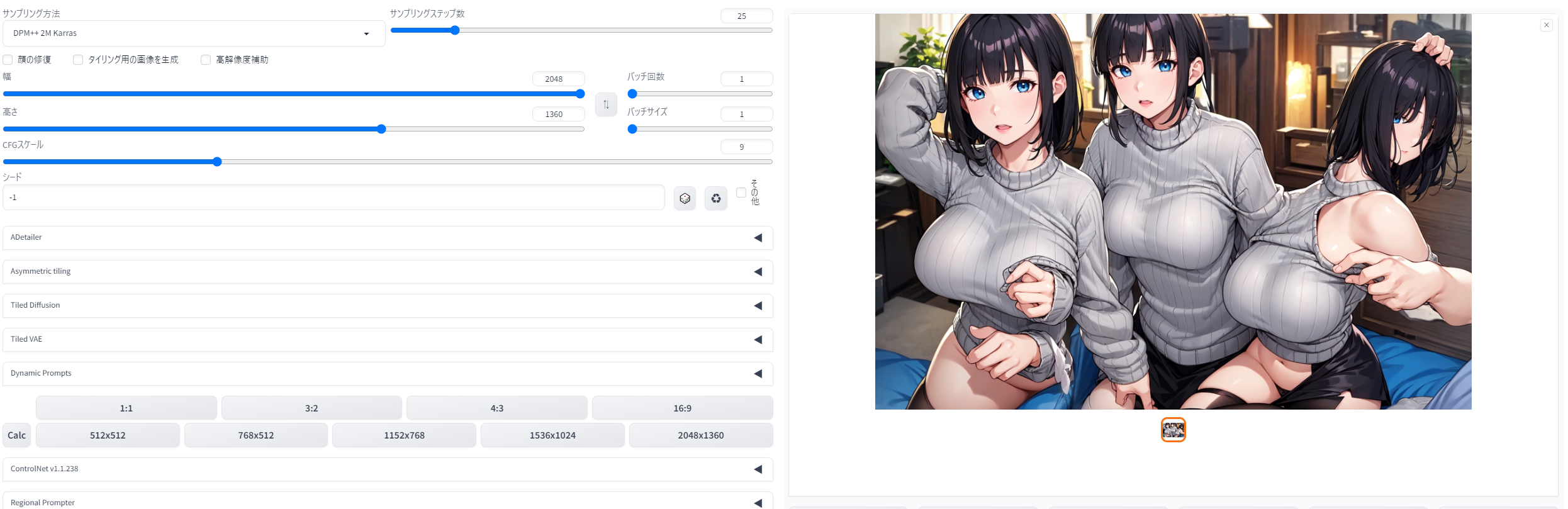
キャンバスの比率だけでなく、サイズそのものも大切です。たとえ比率が4:3でも、いきなり長辺が1200pixelを大きく超えるような画像を描かせようとすると、
「絵柄が崩壊しやすい」「不自然なポーズや大量の被写体などが描かれる」「1枚あたりの生成に時間が掛かる」「出力されたイラストを気軽にレタッチできなくなってしまう」…といったデメリットが生じます。
大崩壊していて苦手な方もいると思うので小さめで掲載しておきますが、こちらはいきなり長辺2048ピクセルで生成しておかしなことになった例。
{kind=link}
全く同じ設定・Seed値でも、768x512サイズにして生成すればこのようになります。
{kind=link}
つまり、横着せずいったんこのイラストを挟んでから、これを2048pxサイズにアップスケールすれば良いことになります。指が増えてしまっている部分の修正も、アップスケール前にやっておけば良いですね。
ここまでの基本をまとめると、要するに「できるだけ常識的な縦横比で、小さく作って、必要な修正を加え、大きくアップスケールする」がAIイラストの基本になるわけです。
ただ、小さいサイズでキャラ1人の画像を生成すると、下図のようにどうしてもキャラクターを中央に大きく描く構図ばかりが出てしまいがちです。マスピ顔(Chckpointごとに存在する定番の顔立ち。Masterpiece顔)ならぬ、マスピ構図。
{kind=link}
あえてこうした構図から外したい場合は、じっくりプロンプトを練るか、Controlnetを使うなどする必要が出てきます。
どんなサイズで生成するのが良いかはいろいろな考え方がありますが、賢木はNovelAIにおける「Normal」サイズである768×512pixelを基本にしています。いずれも64の倍数なのでWebUI上の拡張機能で扱いやすい、というのがその理由。この縦横比のまま1.5倍にすると1152×768pixel、それをimg2imgの既定値の最大サイズにするなら2048×1360pixel。(※これだけ64の倍数ではなくなります)
最終的にイラストに整える場合は拡大しても見やすいようにもう少しキャンバスサイズを落としますが、このあたりの数字を覚えておいて、イラストによってアップスケール方法を使い分けることにしています。
キャンバスサイズの基本をおさえたところで、さっそく具体的なアップスケールの手法について見ていきましょう。
{kind=link}
高解像度補助(Hires.fix)
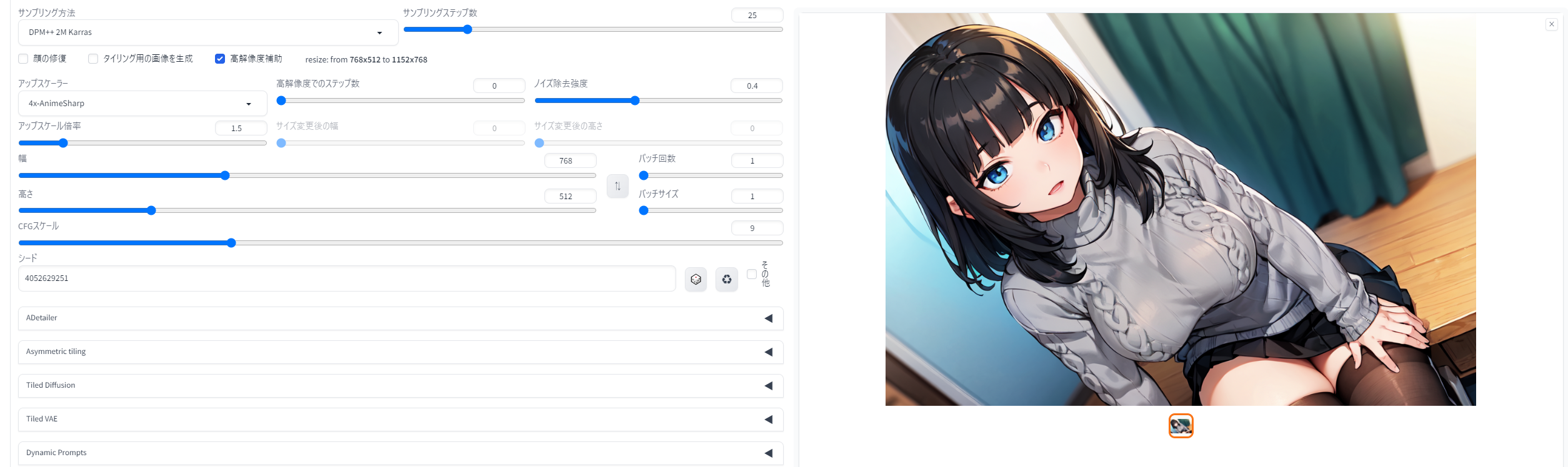
多くの方が最初に試すアップスケールが「高解像度補助(Hires.fix)」ではないでしょうか。これはText2imageで画像生成する際、SDwebUIにあらかじめ組み込まれている各種アップスケーラーを使って、同時に等倍アップスケールを掛けることができる機能です。
通常のt2i生成に引き続いて自動で高画質化が行われるため、Forever生成(停止するまで生成を続けるモード)をスタートして外出しても、1枚1枚同じ設定でアップスケールを掛けることができるのがHires.fixの大きなメリット。あまり強く掛けると絵柄が崩壊しがちですが、大量生成するならその中から崩壊していないものを選び出せば良いので、「数打ちゃ当たる」式の生成が可能です。初心者にも優しいアップスケール方法と言えるでしょう。
{kind=link}
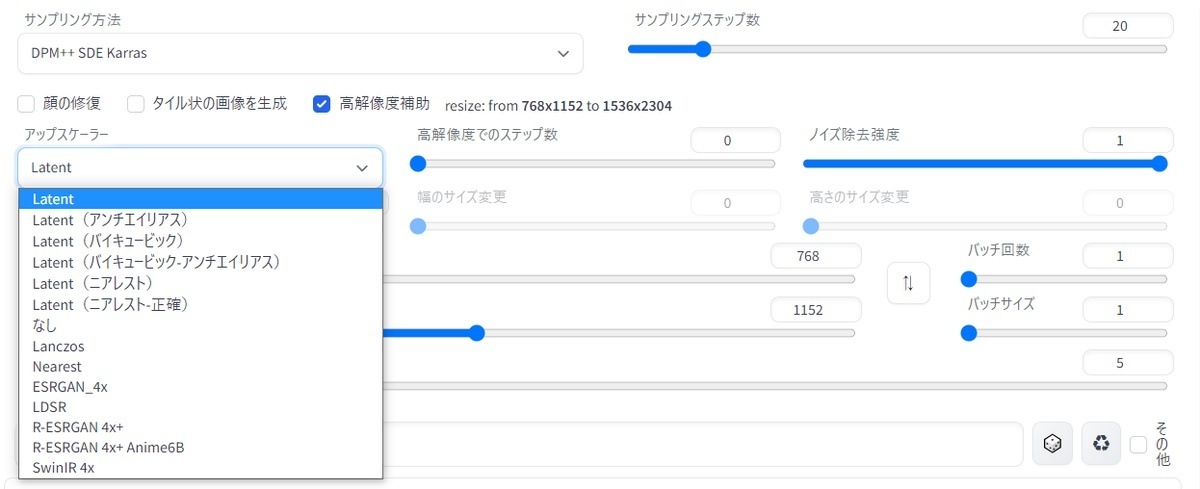
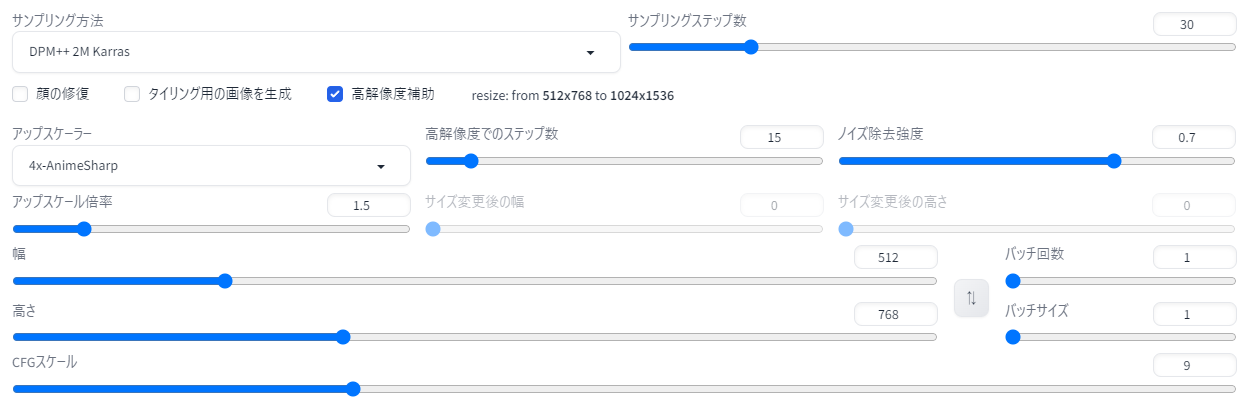
「Latent」や「Real-ESRGAN 4x plus anime 6B」など、あらかじめ用意されたアップスケーラーから好みのアルゴリズムを選べるのが特色で、「アップスケール倍率」で何倍に引き伸ばすかを選び、「ノイズ除去強度」で影響度を決定します。ちなみに、ウェブ上で配布されているアップスケーラーを「models\ESRGAN」フォルダに格納することで増やすこともできます(後述)。
高解像度でのステップ数(Hires steps) は「0」にすると本生成のSTEP数と同じ回数だけ高解像度化処理が行われますが、生成結果の高精細化はある程度で飽和しますので、完全なノイズから画像生成する本生成と同じSTEP数は必要ないことが多いです。結果がさほど変わらないのに生成時間が増えてしまうのはもったいないので、私の場合、本生成が25~30STEP程度だったらHires stepsは15前後にしていることが多いです。
ノイズ除去強度はHiresを使う上で最も重要。アップスケーラーによって大きく結果が変わることに注意が必要です。「Latent」系のアップスケーラーを使用する場合、ノイズ除去強度は0.5より低いと逆に低劣化して線がジャギジャギになりますし、高すぎると崩壊します。下図は「Latent」アップスケーラーでノイズ除去強度を変化させた例。0.65前後がだいたいの目安でしょうか。0.5と0.7の手元を見ていただくと分かるように、Latent系は元絵が変化するのを厭わないので、ある程度崩壊を修正してくれる力がありますが、0.8くらい強くなると元絵から大きく離れてしまいます。
{kind=link}
「Real-ESRGAN 4x plus anime 6B」や後で紹介する追加Hires「4x-AnimeSharp」など、画像をできるだけそのままの構図で高精細化してくれるアップスケーラーの場合、さほど神経質にならなくても大丈夫。下図はR-ESRGAN 4x+ Anime6Bのノイズ除去強度による違いを示した図です。
{kind=link}
ノイズ除去強度が弱ければ元画像からさほど変わりませんし、0.7くらいまでなら顔立ちが大きく変わることもあまりありません。
(※ちなみにこの2つはGPU負担が重めなので、2倍サイズで4枚同時バッチ生成しようとすると、RTX3060を使っている賢木の環境では頻繁にCUDA OUT of Memoryになります)
追加アップスケーラーのススメ
さて、いま触れた「4x-AnimeSharp」というアニメ調イラスト向けのアップスケーラーは、SDwebUIにはビルトイン(同梱)されていませんので、利用するためにはウェブ上から追加ダウンロードする必要があります。
他にも、「アニメ調特化」「写真特化」「顔特化」「白黒漫画特化」などさまざまな特徴のあるアップスケーラーがウェブ上で公開されています。こちらのデータベースから、気になるのを探してみるのもよいでしょう。
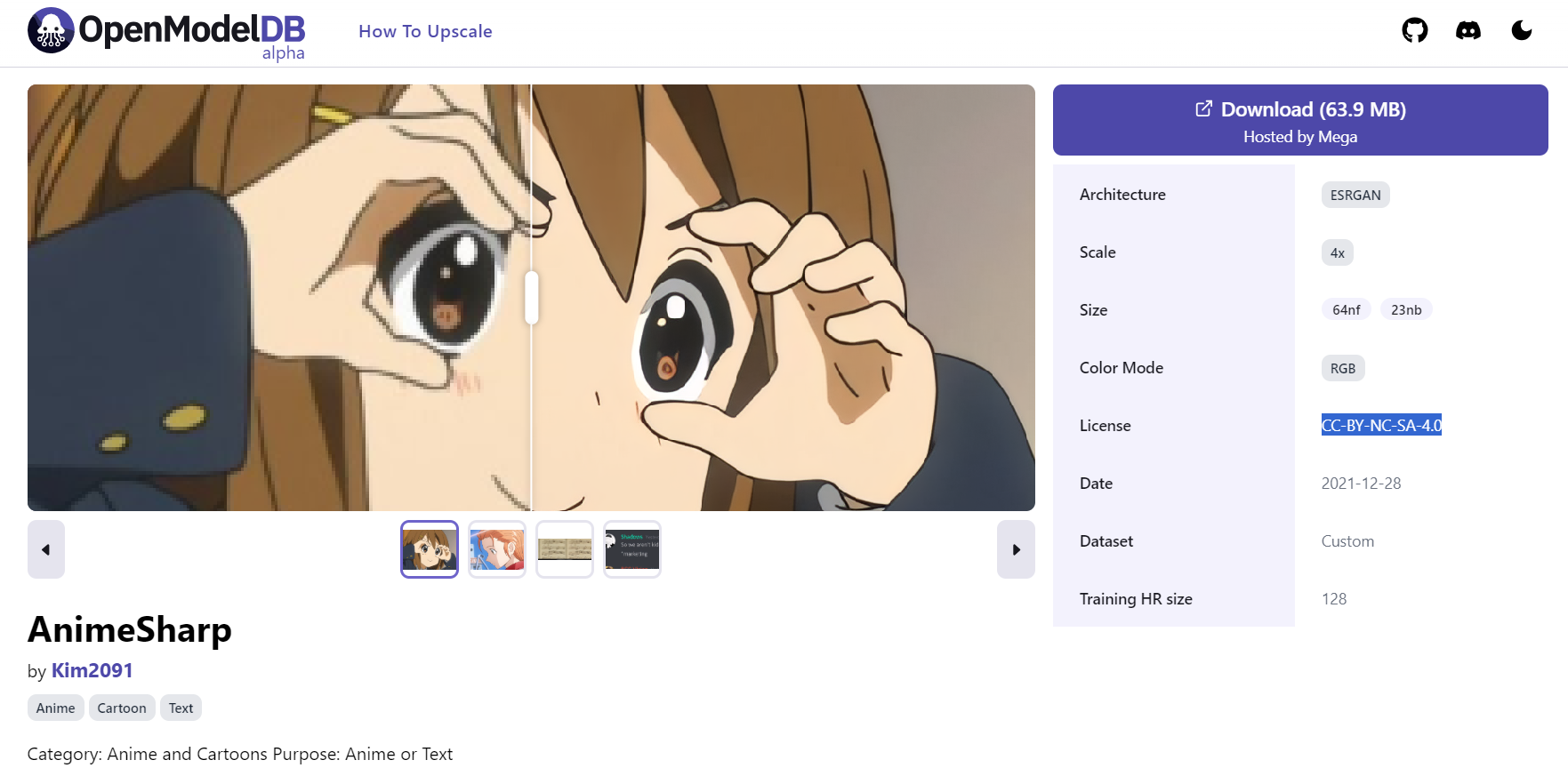
【重要】アップスケーラーも学習モデルである以上、CheckpointやLoRAなどと同じようにそれぞれ配布者が設定したライセンスが存在します。利用する際は必ずライセンスの内容を確認するようにしましょう。
{kind=link}
▲「License」欄をチェック
【アニメ系アップスケーラーの例】
※ライセンスはいずれも「CC-BY-NC-SA-4.0」です(※基本的にアルファベット二文字が規定事項を示し、末尾の数字がバージョンを示しています。CC-BY-NC-SA-4.0は『著作者情報の表示義務』『営利使用不可』『改変して新しいアップスケーラーなどを作成した場合は元のライセンスを継承する必要あり』の意味です)
・4x-AnimeSharp
・UltraSharp
・Lollypop
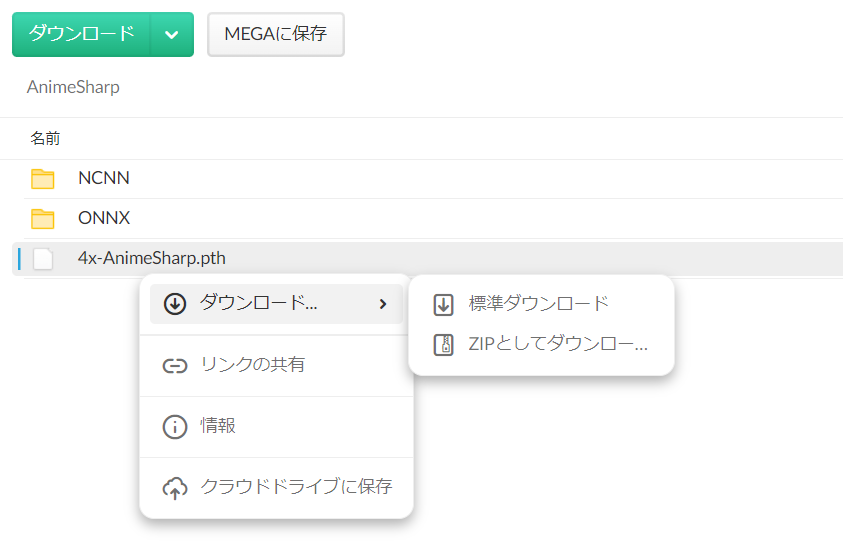
【4x-AnimeSharpのダウンロード例】
リンク先のダウンロードボタンをクリックすると、ストレージサイト「mega」に遷移するので、このように右クリックして「4x-AnimeSharp.pth」ファイルを標準ダウンロード。
{kind=link}
あとはSDwebUIの「models\ESRGAN」フォルダに置いて再読み込みすれば、ほかのアップスケーラーと同様に利用できるようになります。
【2023/08/30追記】
アップスケーラー「UltraSharp」と「AnimeSharp」のライセンス表記がCC-BY-NC-SA-4.0(非営利、クレジット明記、ライセンス継承すれば改変・再配布可)となっている件につき、「生成した画像にもこのライセンスの効果は及びますか?」と制作者のKim2091氏に問い合わせたところ、お返事を頂きました。
結局のところ、法律専門家でなければライセンスの正確な法的効果については結論を出せないとのことですが、制作者としてライセンスに込めた意図や希望としては上記リンク先に書かれた通りとのことです。利用される場合はご一読ください。
アップスケーラーごとの違い
こちらの768x512ピクセルでポン出しした画像について、アップスケーラーの総当りを試してみましょう。
{kind=link}
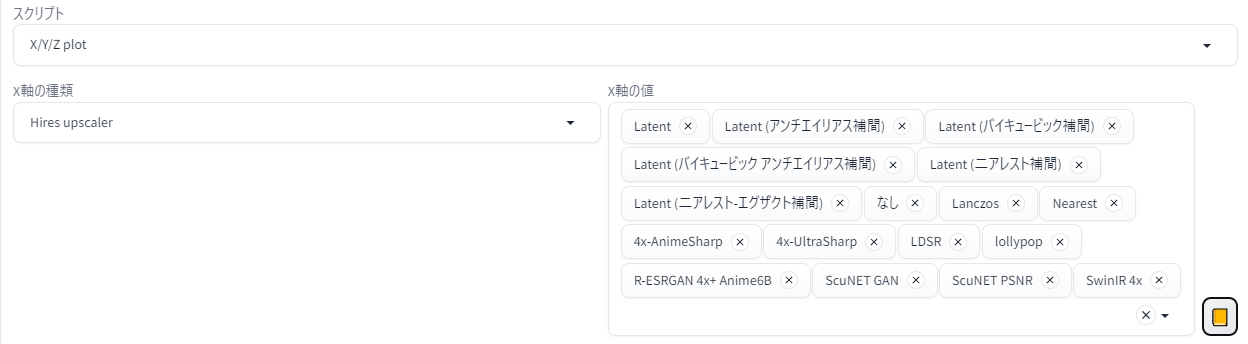
ちなみにX/Y/Zプロットでこうした総当りを試すときは、右側の黄色いボタン(▼)を押すと、現在使用できるすべての値が欄に自動記入されます。
{kind=link}
{kind=link}
倍率は768✕512pixelから1.5倍、ノイズ除去強度は0.7に固定して比較実験したのがこちら。(適宜拡大してご覧ください)
①Latent系 +アップスケーラー「なし」
{kind=link}
②その他
{kind=link}
ほとんど変わらないじゃないですか!?
{kind=link}
まあ実際ほとんど同じなわけですが、特に違いが出ているのは左手付近に黒いベルトのようなオブジェクトが生じているかどうか。ノイズ除去強度が0.7と強めなので、元絵の一部が変異してこうしたものが生じがちです。また、親指の長さもかなりまちまちなのがわかります。アップスケール元の画像とアップスケーラーの組み合わせによってどんな現象が起こるかはそのときどきなのですが、アップスケーラーがそれぞれ異なる処理をしていることがよく分かると思います。
各アップスケーラーの効果は使用するCheckpointによって異なりますし、各ユーザーの求める画風によっても価値が変わってくるので、あくまでご参考まで。Checkpoint配布者がおすすめのHiresの種類や設定を記載していることも多いので、覚えておきましょう。
{kind=link}
image2imageアップスケール
Hires.fixの次の選択肢が、みんな大好き「image2imageアップスケール」です。
{kind=link}
こちらは、元画像を「image2imageに送る」などで読み込み、同じプロンプトでより大きなサイズにi2iするやり方。デフォルト設定ではアップスケーラーを使わないため、Hires.fixのような予期せぬオブジェクトの出現がしにくいですし、Latent系のように強さが0.5~0.65前後に限られるといったこともありません。あまり大きく絵柄を変更することはできませんが、表情程度ならプロンプトを一部変更することで変えることもできます。(例:smile→sadなど)
Checkpointやプロンプトを変えたり、Controlnetを効かせたりすることもでき、さまざまな選択肢を選べるのがメリットです。その代わり、手動で設定値を入力しないといけないので、Hiresのように大量生成時に自動でアップスケールしてもらうことはできません。HiresがAIお任せのアップスケールとすれば、i2iはオーダーメードに当たるアップスケールと言えるでしょう。(※ちなみに「設定」タブから、img2img時に、Hiresと同様に各種アップスケーラ―を使用する設定にすることもできます。デフォルトではアップスケーラ―「なし」になっています)
{kind=link}
重要なのは、アップスケール前に細部を修正する選択肢が生まれること。上のイラストは、青いショートヘアの女の子を赤いロングヘアにインペイントしてアップスケールした例です。単にプロンプトをBlue_hairをRed_hairに変えてもうまくいきませんが、このようにInpaintと併用することで被写体を自由に操作することができます。
レタッチ(inpaint)機能が理解る!修正&入れ替え徹底解説

こんばんは、スタジオ真榊です。今夜の記事は、image2imageを画像の一部だけに掛けて修正できる「レタッチ機能」についてです!設定値と生成結果が直感的に結びつきにくいので、みんななんとなく体感でなんとかしている(そしてたいていなんとかならない…)のが、このレタッチ機能。いろいろな実験結果と共に、ようやく...
上のメイドさん画像の例では、右手のカフスが2つ出てしまっているなど不自然な部分なども修正した後、アップスケールすることでなじませています。他にも、「差分シリーズ」の過去記事で紹介したテクニックを使えばあらかじめ絵柄を大きく変更し、それからアップスケールすることができるのがi2iアップスケールの優れたポイントです。
{kind=link}
ちょっと強引な絵柄変更でも、そのあとにアップスケールをすれば、多少のディティールの破綻はきれいに整えてくれます。いまはLamaCleanerやAdobe「生成塗りつぶし」、ControlnetのInpaintOnlyなど、さまざまな修正の選択肢がありますので、以前よりも格段にimg2imgアップスケールの取り回しのしやすさを感じます。
768×512pixelで生成したイラストをレタッチで直したら、i2iで1.5倍の1152×768pixelにいったんアップスケールし、さらに2048×1360pixelにアップスケールするのが賢木のよくやる方法。1152pixelサイズにアップスケールするときは、Seed値-1で4枚生成にし、一番好みのものを2048pixelサイズにアップスケールすると失敗が少ないです。さらに、よく似たイラストが計5枚できるので、クリスタなどの画像編集ソフトを使って、2048pixelの崩壊部分を「人力マージ」することもできます。
(※ほぼ同じ構図の複数のアップスケール版をサイズ統一してからレイヤーで重ねて、不要な部分をやわらかい消しゴムで消すなどして「いいとこ取り」する手法をスタジオ真榊の記事ではこう呼んでます)
text2imgとimg2imgでモデルを変える「疑似マージ」
小さいサイズでt2i生成するときと、i2iで大きくアップスケールするときでCheckpointを変えることで、双方の良いところを活かす手法があります。2つのCheckpointをマージしたかのような絵柄になるので、私は勝手に「疑似マージ」と呼んでいます。
例えば、Counterfeitシリーズのように比較的背景が得意なモデルで768pixelサイズのイラストを生成(▼左イラスト)した後、レタッチで破綻を直してから一度1152pixelサイズにアップスケール(▼中央イラスト)。その後、AbyssOrangemixシリーズのようなややリアルめに寄せた人物描写ができるモデルでノイズ除去強度弱め(0.25~0.45程度)にアップスケールを掛ける(▼右イラスト)ことで、双方のモデルの特色を破綻なく融合することができます。
{kind=link}
意図に沿った構図を作った後、好みの絵柄に寄せることができるので、なかなか使い所の多いアップスケール手法です。「下書き用モデル」と「仕上げ用モデル」を分けるイメージですね。レタッチ機能を使えば、アップスケール前の残したい要素をマスク(保護)することもできますし、さきほど紹介した「人力マージ」をしても良いですね。
{kind=link}
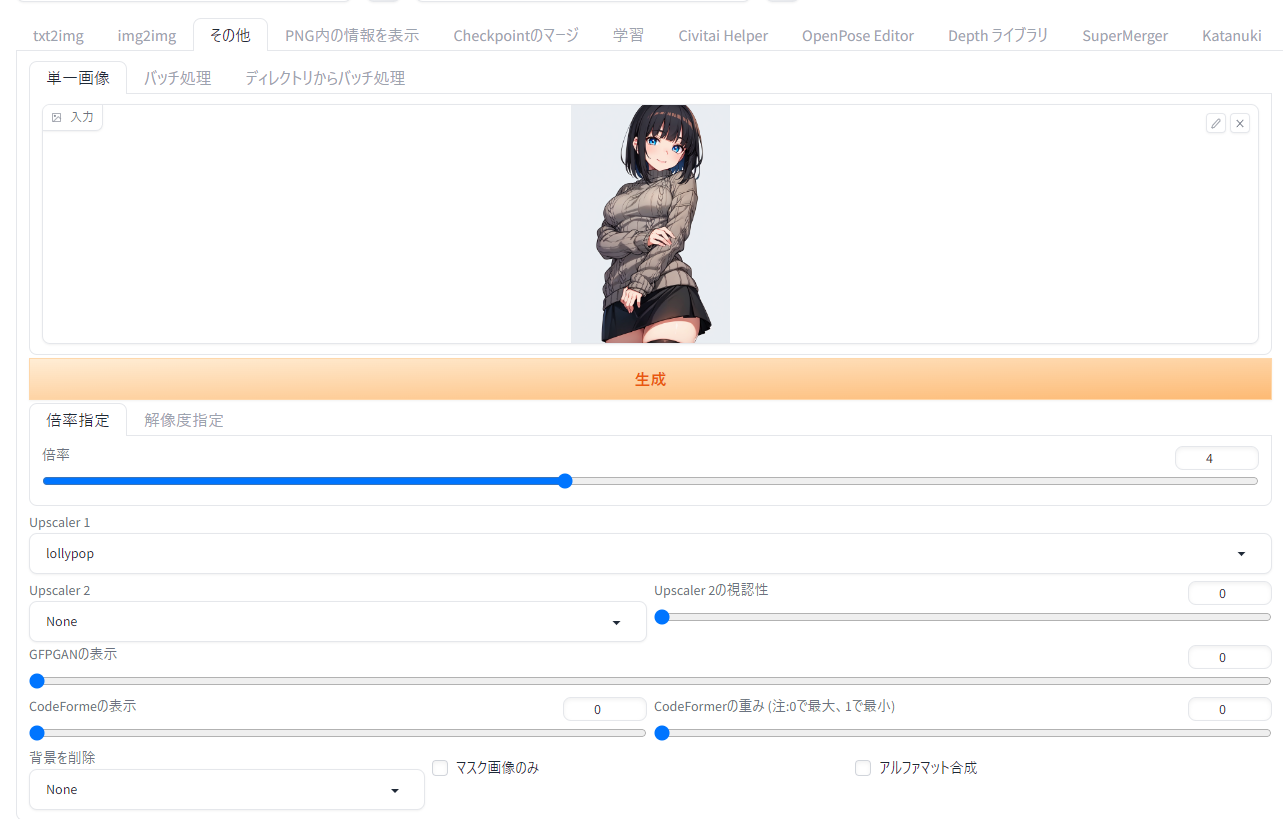
Extra欄でできる「そのままアップスケール」
{kind=link}
SDwebUIの画面上部のタブを御覧ください。左からt2i欄、i2i欄ときて、3つ目に来るのがその他(Extra)欄です。ここでは既に完成したイラストをより大きなサイズに変更することができます。Hiresやi2iアップスケールのように絵自体が変化することはなく、画像を拡大したときに違いが分かる「拡大&ぼやけ補修」のようなアップスケール手法です。
例えば1024x1536ピクセルのAIイラストをそのまま8倍程度に拡大表示すると、普通はこのようにドットが目立ってしまいます。
{kind=link}
「その他」の画面で「アップスケーラー1」に任意のアップスケーラーを指定し、倍率を「4」にして生成ボタンを押してみます。出力されたものを同じように拡大表示してみると、このように粗いドットが補修され、スムーズなタッチになっているのがわかります。
{kind=link}
絵のデザインは元の絵に忠実に描かれるため、「スムーズ化」はされても描き込み量が上がったりはしませんが、画面上で大きく表示したり、印刷したりするときには手軽なアップスケール方法と言えます。絵柄が改変されず生成に掛かる時間も短めなので、イラストが完成したらとりあえずこれを掛けてから投稿しているという人も多いようです。
▼Twitter投稿時は注意!
Twitterにある程度大きいpng画像をアップしようとすると、自動でjpeg変換アルゴリズムにかけられて低画質化してしまうことが知られています。こちらの記事で検証されていますが、あらかじめ自分で高画質なjpg画像(5MB未満、4096x4096pix未満が推奨)にしてアップすると、これを防げることがあります。
Twitterが「X」に移行したことでこのあたりのルールも変化している可能性がありますが、高解像度のイラストを投稿される場合はご一考ください。
さて、これまで紹介したテクニックは、基本的に「きれいに高解像度化(サイズアップ)」するためのアップスケール方法でした。ここからは、描き込み量を増やしてリッチにする「高精細化(クォリティアップ)」の手法を紹介していきます。
{kind=link}
CN「Tile」を使った高精細化
まずはControlnet1.1から追加された「Tile」を使った方法です。Tileの詳細については個別記事を参照のこと。
アップスケール?描き直し?新モデル「Tile」ができること
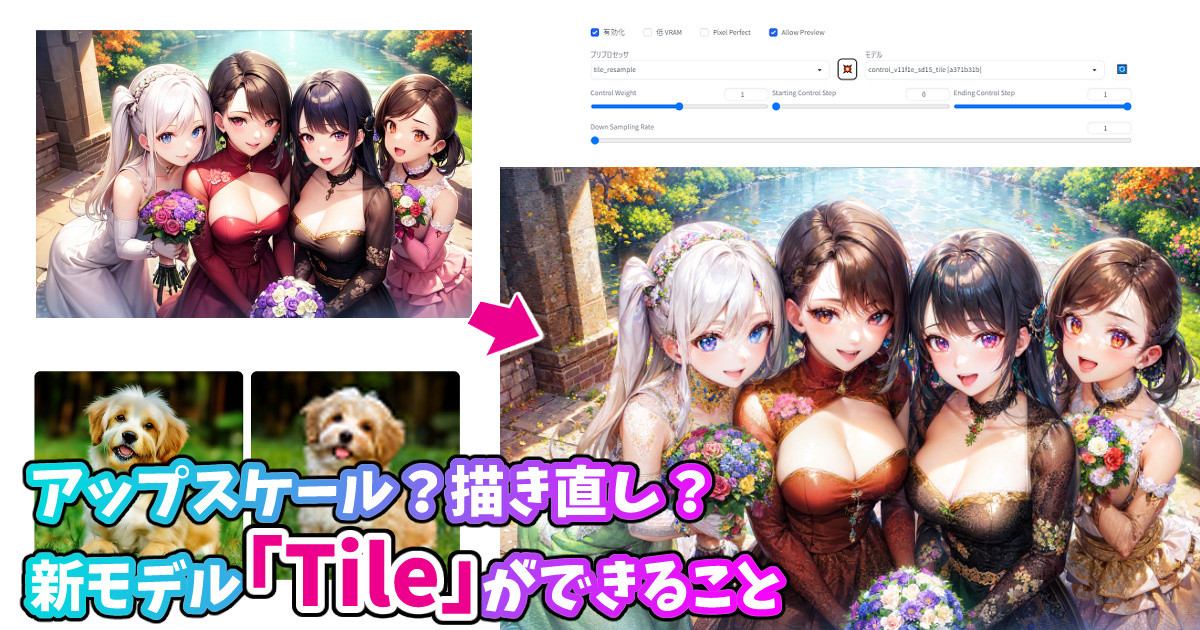
こんばんは、スタジオ真榊です。今夜は2023年4月25日付で完成したばかりのControlnet1.1用モデル「Tile」についての報告です。Controlnet1.1で使えるものの中でもひときわ異質なこのモデル。アップスケール用なのか?それともCannyやDepthのように構図を写し取るためのものなのか?いろいろと検証してみました。 ※Contro...
Tileには3つの専用プリプロセッサがあります。「Tile resample」「tile colorfix」「tile colorfix+sharp」がそれで、「resample」は入力した元画像を単にダウンサンプリングするだけのプリプロセッサ、「colorfix」は「resample」が色合いを変化させてしまう弱点を補ったもの、「+sharp」はcolorfixが線をぼかしてしまう弱点を補ってくれるものです。基本的に「tile colorfix+sharp」を使っていて問題ありません。
{kind=link}
これは、一番左の画像をそれぞれのプリプロセッサで2倍近くの大きさにアップスケールしたもの。text2text画面のControlnet欄に元画像を放り込み、高解像度補助はOFF、サイズをいきなり1360x2048サイズに指定して生成しています。Tile resampleは描き込みを増やしたことで色合いが秋のように変化してしまっていますが、colorfixと+sharpはいずれも新緑のカラーを維持できており、sharpのほうがcolorfixよりも「シャープ」になっていることがわかります。(一つ気になるのは、左手の描写がどれも崩れてしまっていることですね)
大きいサイズで見てみましょう。こちらがcolorfix。
{kind=link}
こちらが+Sharpです。遠目にみるとシャープに見えましたが、アップにすると塗りがパキパキになりすぎて不自然になっていますね。
{kind=link}
開発者のイリヤスフィール氏は「現時点ではcolorfix+sharpを使用するのが最善」としているので、基本的にはcolorfix+sharpを選んでよいのですが、上の例ではシャープになりすぎているので、設定値をデフォルトからいじる必要があります。
{kind=link}
こちらはControlnetの重みを0.6にしたもの。
{kind=link}
こちらはSharpness(シャープさ)をデフォルトの1から0.5に下げたものです。
{kind=link}
いずれにせよ、左手の崩壊は引き継がれてしまっています。影になった手とベンチの境目がAIに分かりにくかったのが原因と思われ、この部分は何らかの方法で修正しないといけませんね。描き込み量がキャンバス全体でアップすると非常に見にくいイラストになってしまうので、「人力マージ」の手法で取捨選択するとよいと思います。
Tileで描き込みを増やしたものと、単にアップスケールしたものをぴったりレイヤーで重ね、描き込まれすぎた部分を消しゴムでやんわり消します。下の画像は、消した部分がわかりやすいようTile適用レイヤーだけを表示したもの。
{kind=link}
するとこのように、高精細に見せたいところだけをシャープにし、シンプルでいいところや崩壊していない部分を残す「取捨選択」ができます。Tile独特の見にくさを軽減する手法の一つとして覚えておくとよいと思います。
{kind=link}
「やりすぎTile」を防ぐには
上の例はわかりやすさを優先するためにtext2imageでTileを適用しましたが、細部が描き込まれすぎる問題を防ぐために、text2imageではなくimg2imgでTileを適用する方法も一般的です。その場合、ノイズ除去強度を0.4~0.5程度にすると、ちょうど元画像とTileの中間くらいの描き込み量に調整できるイメージです。
こちらがその設定で生成したTile使用img2imgアップスケール。さきほどのt2iと比べ、Tileの影響が控えめになっていることがわかります。
{kind=link}
Tileは「低劣な細部」をいったん捨てて「描き直す」Controlnetです。さきほどのようなパキッとしたアニメ調のイラストはあまり得意ではないのですが、少し「半リアル・半イラスト」寄りの学習モデルで使うと、このようにとんでもなく高精細に描き込まれる傾向があります。
{kind=link}
ただ、「ここに何が描かれているか」を勘違いして別の質感のものに書き換えてしまうこともありますし、よく見ると細部がおかしいということも。「イラストは高精細であればいい」というものでもないので、人力マージなどの手法で情報量の交通整理をしたり、見やすく視線誘導したりしてあげると良いでしょう。
VRAM不足には「Tiled Diffusion with Tiled VAE」
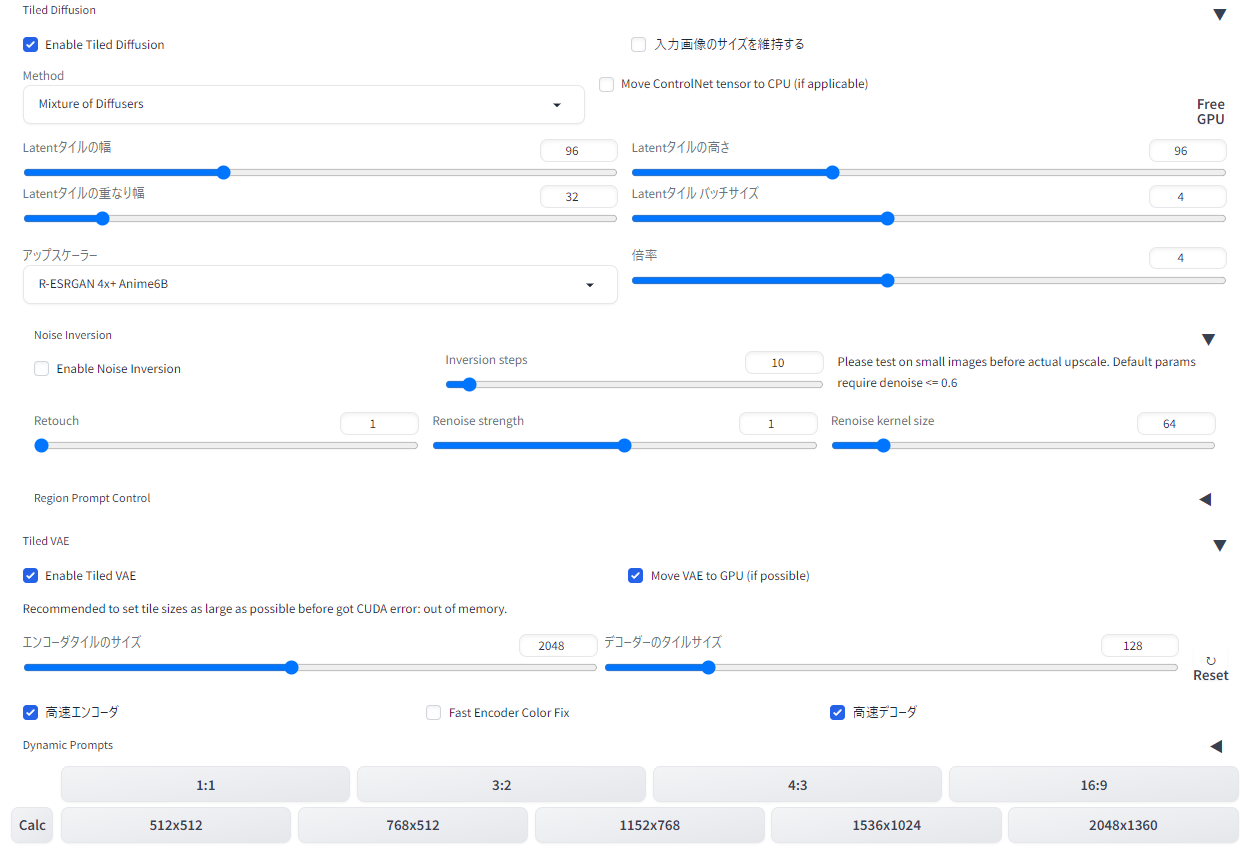
グラフィックボードの限界を超えた設定でアップスケールをしようとすると、VRAMが不足して「CUDA out of memory」エラーが生じてしまい、生成がストップしてしまいます。そうした場合は、画像をいったん複数の「タイル」に分割しておのおの高解像度処理をした後、またつなげてくれる「Tiled Diffusion」と、VAEの処理時にVRAM使用量を抑制する「Tiled VAE」という拡張機能を併用しましょう。生成時間は多めに掛かりますが、グラフィックボードの限界以上に大きな画像を生成することができます。
弱点は、タイルごとにアップスケールを掛けるため設定が繊細で、失敗すると画面上に「小人」がたくさん生成されてしまうこと。1回あたりの生成時間が非常に長く掛かるので、失敗すると大きなロスタイムになってしまうのも痛いので、しっかり設定を確認してから生成開始するようにしましょう。
【インストール方法】
通常の拡張と同じく、「Install from URL」タブから「https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.git」と入力してインストールすればOK。Controlnetなどと同じ位置に「Tiled Diffusion」「Tiled VAE」のプルダウンメニューが追加されます。
(1)Tiled Diffusion
Tiled Diffusionは「Enable Tiled Diffusion」をオンにすることで動作します。入力された画像を細かいタイルに切り分け、それぞれ高画質化して貼り合わせる作業が何度も行われます。既存画像のimg2imgアップスケール時によく使われますが、text2imageで使用することももちろん可能。顔や手をアップスケールしてくれる「ADetailer」を、キャンバス全体にタイルを敷き詰めるようにして掛けるのに近いイメージです。
{kind=link}
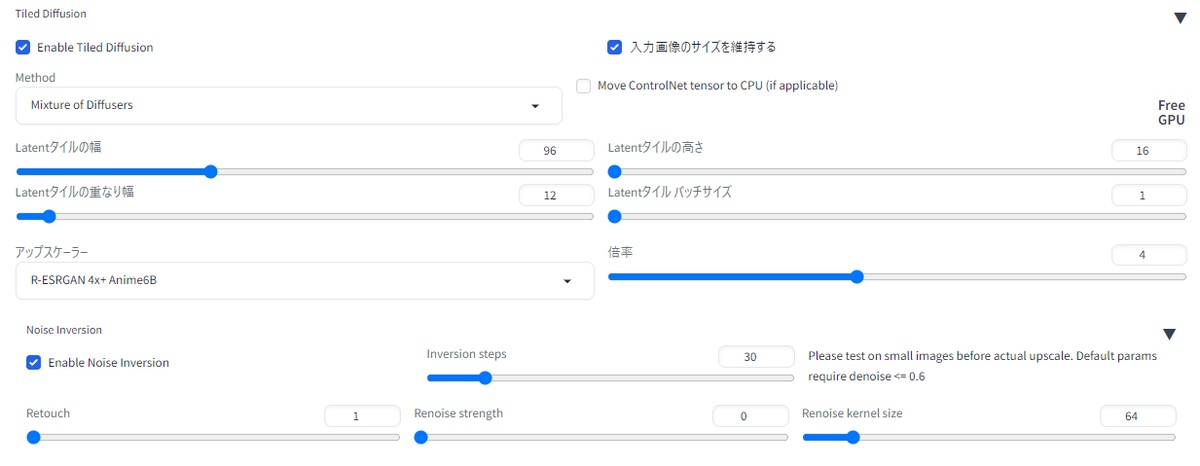
・「MultiDiffusion」と「Mixture of Diffusers」のいずれかのアルゴリズムを選ぶことができます。どちらのアルゴリズムを選んだかで生成結果や時間が変化しますが、さほど大きな差はありません。私は特段の理由がなければ「Mixture of Diffusers」を選んでいます。少し早い・・・かな・・・?
・「入力画像のサイズを維持する」にチェックを入れると、image2image画面で入力した元画像のサイズが維持されます(つまり、img2img画面でどんなキャンバスサイズに設定しても意味がなくなる)。ここにチェックが入っていて、後述する「アップスケーラ―」がnoneだと、入力画像と同じサイズの画像がimg2img生成されます。
※ちなみに、この項目はtext2textだと「Overwrite image size(現在の画像サイズで上書き)」になり、こちらもオンにするとt2iのキャンバスサイズ設定を無視します。
・「Latentタイルの幅と高さ」は小分けするタイルの大きさを設定するもので、96ピクセルがデフォルトです。タイルサイズを大きくすると、必要なタイルの数が少なくなるため、生成時間が短くなります。
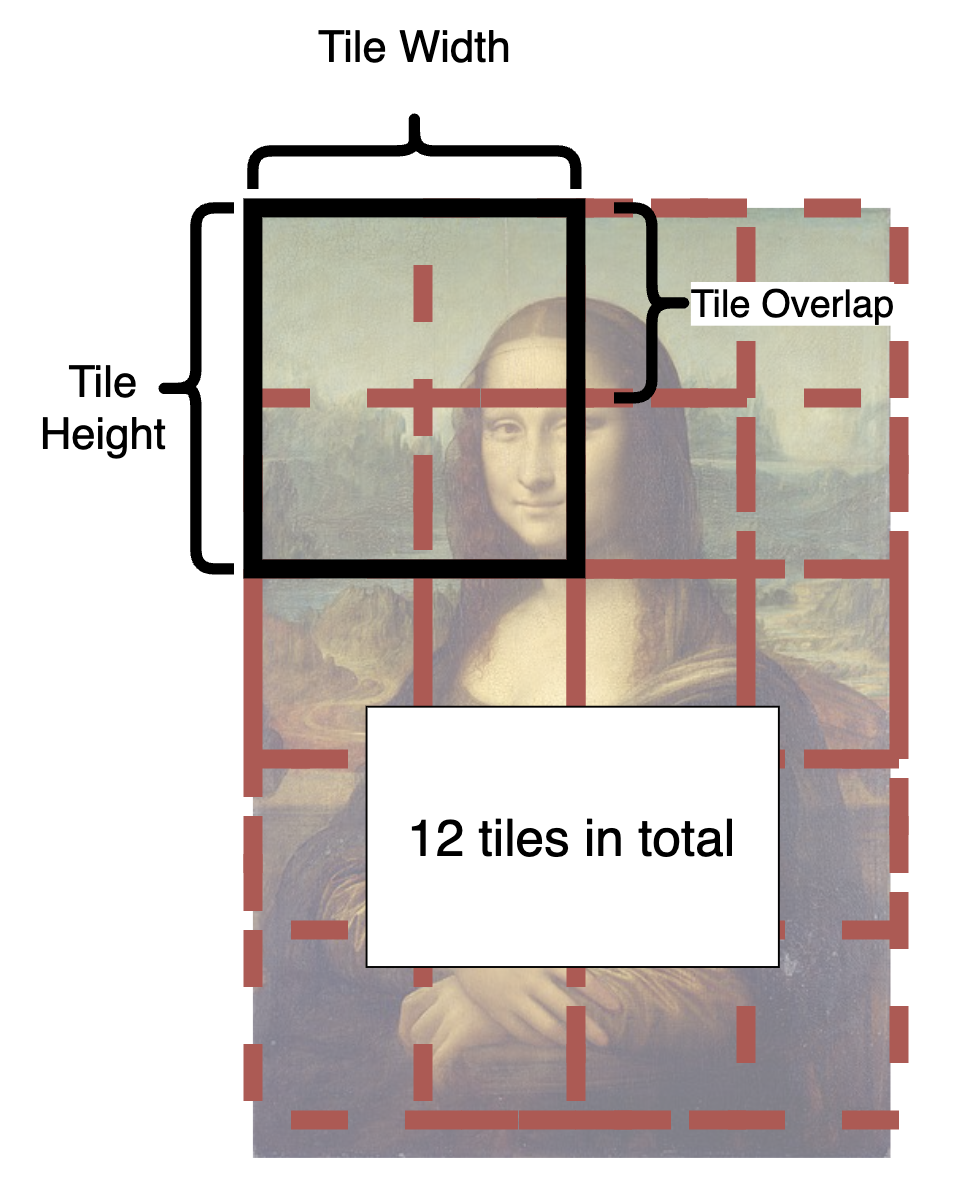
・「Latentタイルの重なり幅(Latent tile overlap)」はタイル同士を重ねて融合させることで、継ぎ目がどこにあるか目立たなくするための設定値です。MultiDiffusionは32か48、Mixture of Diffusersは16か32推奨。考えてみれば当然ですが、重なり幅のサイズは、各タイルのサイズよりも小さくするのを忘れないようにしましょう。
(例:こちらの公式画像をご覧下さい。黒い四角形がタイルサイズで、重なる幅がその半分に指定されています。黒いタイルをモナリザのキャンバス内に普通に敷き詰めようとすると4つまでしか入りませんが、「重なり幅」があるおかげで、横に3つ分×縦に4つ分=計12個分のタイルが敷き詰められることになります)
{kind=link}
・「Latentタイルのバッチサイズ」は各タイルをいくつ同時に処理するか。多いとCUDA OUT of Memoryになりやすいので、グラボ性能と相談してエラーが出ない範囲で多めにしましょう。
・「アップスケーラ―」をNone以外にすると、その横の倍率に従って画像がアップスケールされます。img2imgのキャンバスサイズを元画像の4倍にしていて、こっちでも4倍にすると、結果元画像の16倍サイズになってしまうので注意しましょう。
・「Noise Inversion」は、TiledDiffusionの下部に表示される独自のアップスケーラー項目です。生成画像にさらにノイズを加えてはノイズ除去を行う方法で、「VRAM12GBのグラボでも最大8Kの高解像度画像が生成可能」「キャラクターの顔も元画像から変更されにくい」特徴があるとのこと。オンオフはお好みで。
(2)Tiled VAE
{kind=link}
こちらはVAE(画像生成時の"アンカー"に当たるモジュール)がエンコード・デコード作業を行う際のVRAM使用量を大幅に減らしてくれる拡張機能。オンにすると生成時間が伸びるかわりに、非力なグラボでも高解像度の画像生成が可能になります。
基本的には上の図のデフォルト設定のまま使用すればOKですが、これでもCUDA out of Memoryエラーが生じた場合は、「エンコーダタイルのサイズ」「デコーダのタイルサイズ」をそれぞれ小さくすると回避できるようです。(※ただ、タイルのサイズが小さすぎると、画像が色褪せて不鮮明になってしまうケースがあり、その場合は「Fast Encoder Color Fix」をオンにすると良いとのこと)
(3)実際の使用例
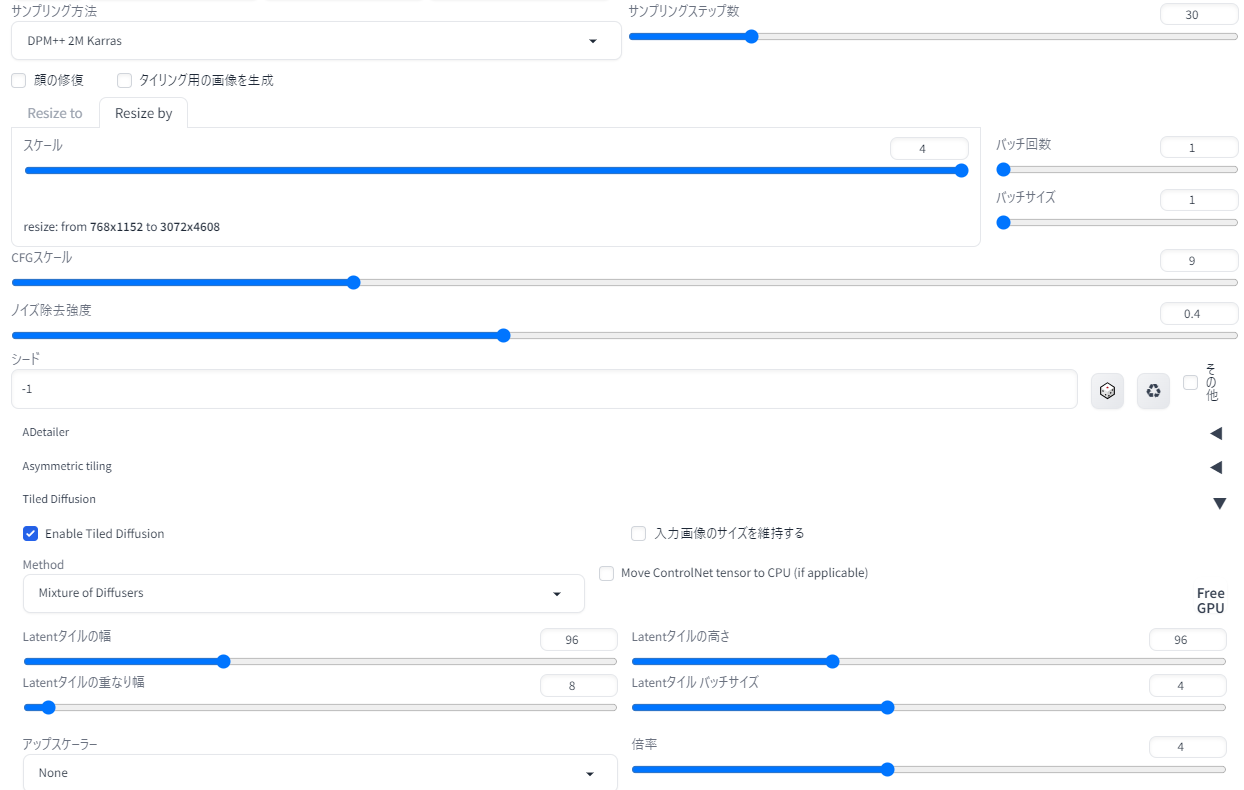
{kind=link}
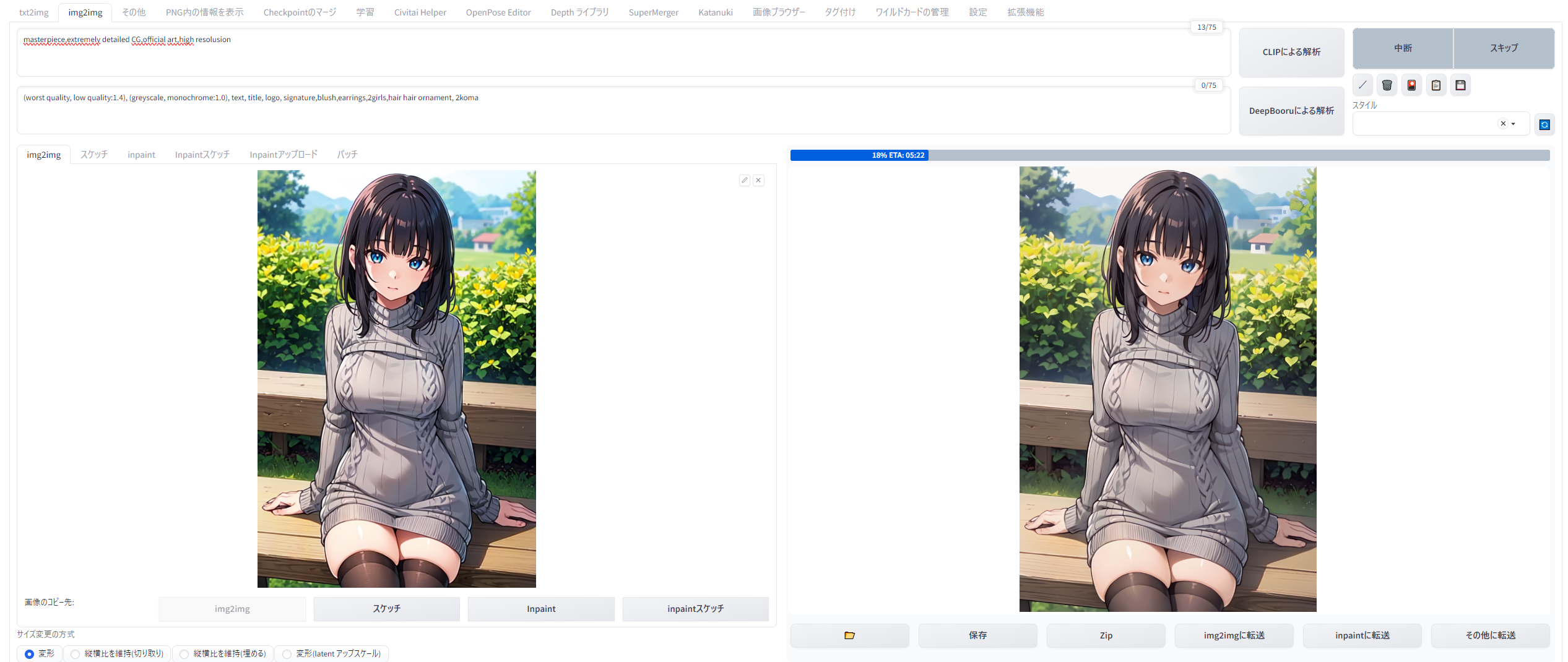
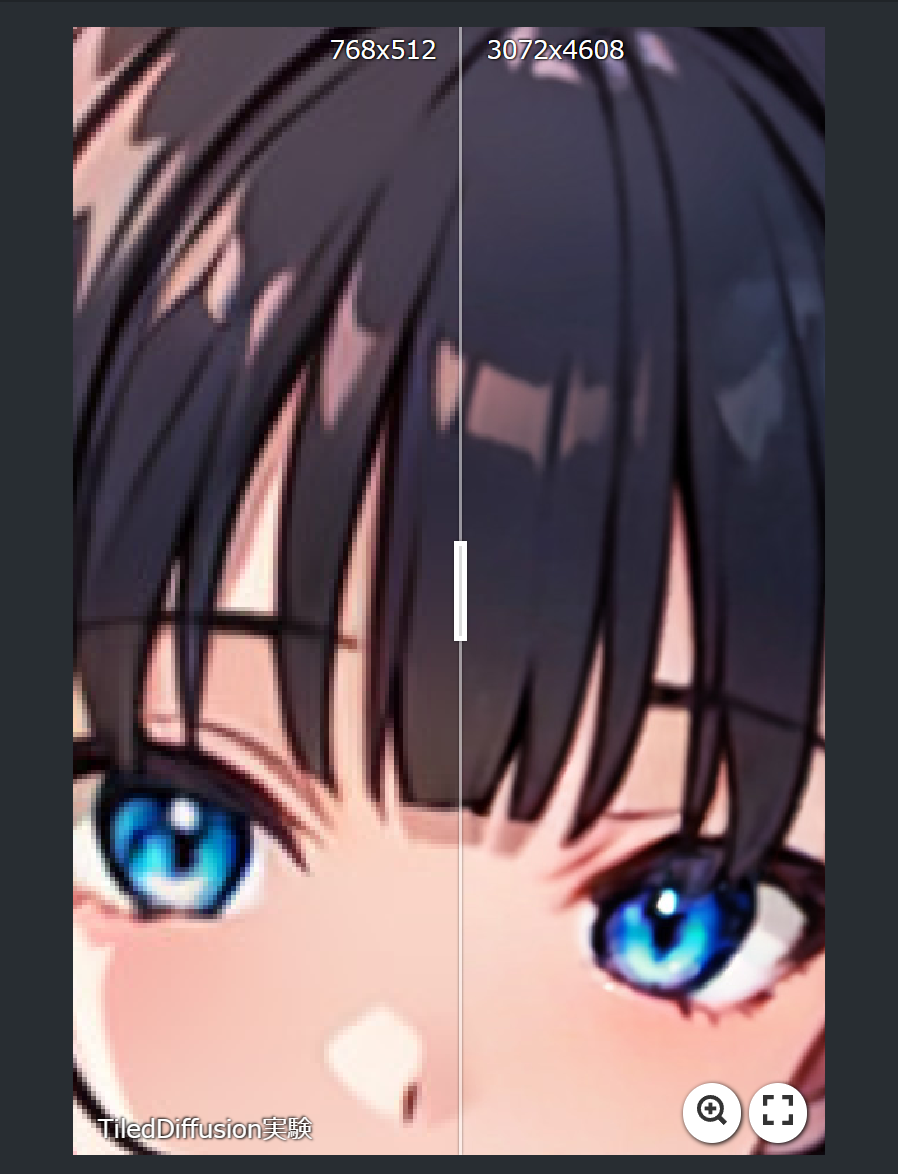
では、Tiled Diffusion with Tiled VAEを使って、 768x1152pxのイラストを縦横各4倍の3072x4608pxにアップスケールしてみましょう。いったん完成したイラストを「その他」欄から単純に4等倍する方法ならこのサイズの生成も可能ですが、普通にimg2imgアップスケールや高解像度補助を使って画像生成するのは、RTX3060には不可能なサイズです。
{kind=link}
img2imgのノイズ除去強度は0.35。img2img画面で設定するキャンバスサイズは768x1152のまま。プロンプトはクォリティタグのみ(masterpiece,extremely detailed CG,official art,high resolusion)とし、Seed値は-1にしました。
TiledDiffusionの設定値は以下のようにしました。NoiseInversionは今回は使用せず、R-ESRGAN4x+Anime6Bで4等倍にする設定です。一つあたりのタイルサイズは96x96px。重なり幅は32pxですから、タイル同士の横縦3分の1ぶん重なる設定ということです。
{kind=link}
Tiled VAEの設定はデフォルトのまま、「Enable」に。
{kind=link}
こちらが4分程度で完成した生成結果です。
ち、違いがわからん!!
{kind=link}
こちらから比較できますが、アップスケール前が既にHiresによってそれなりに高精細化していたため、違いは拡大してやっと分かるレベルですね。
{kind=link}
しかし、ここで「プロンプトを基に戻したり、ノイズ除去強度を上げたりしたら高精細になるんじゃない?」と思うところですが、それをやると失敗してしまいます。こちらがその失敗例で、よく見ると色んなところに小さなキャラクターや目などが生じてしまっています。
{kind=link}
これがTiledDiffusionの難しさで、さじ加減を間違えるとこうした失敗を何度も繰り返すことになってしまいます。さらに、Checkpointとの相性によっても生成結果が大きく変わるので、習熟が必要です。
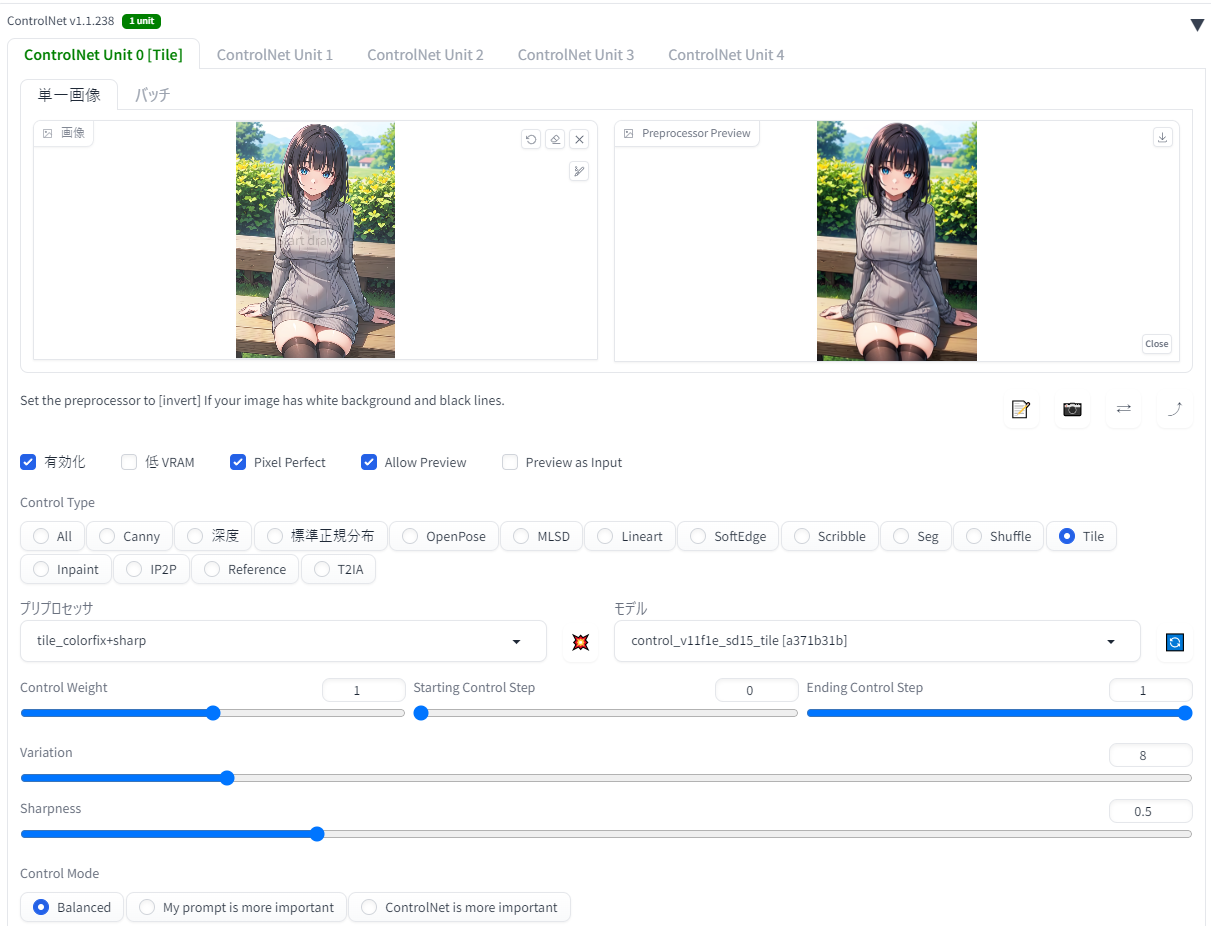
CN「Tile」×「Tiled Diffusion」
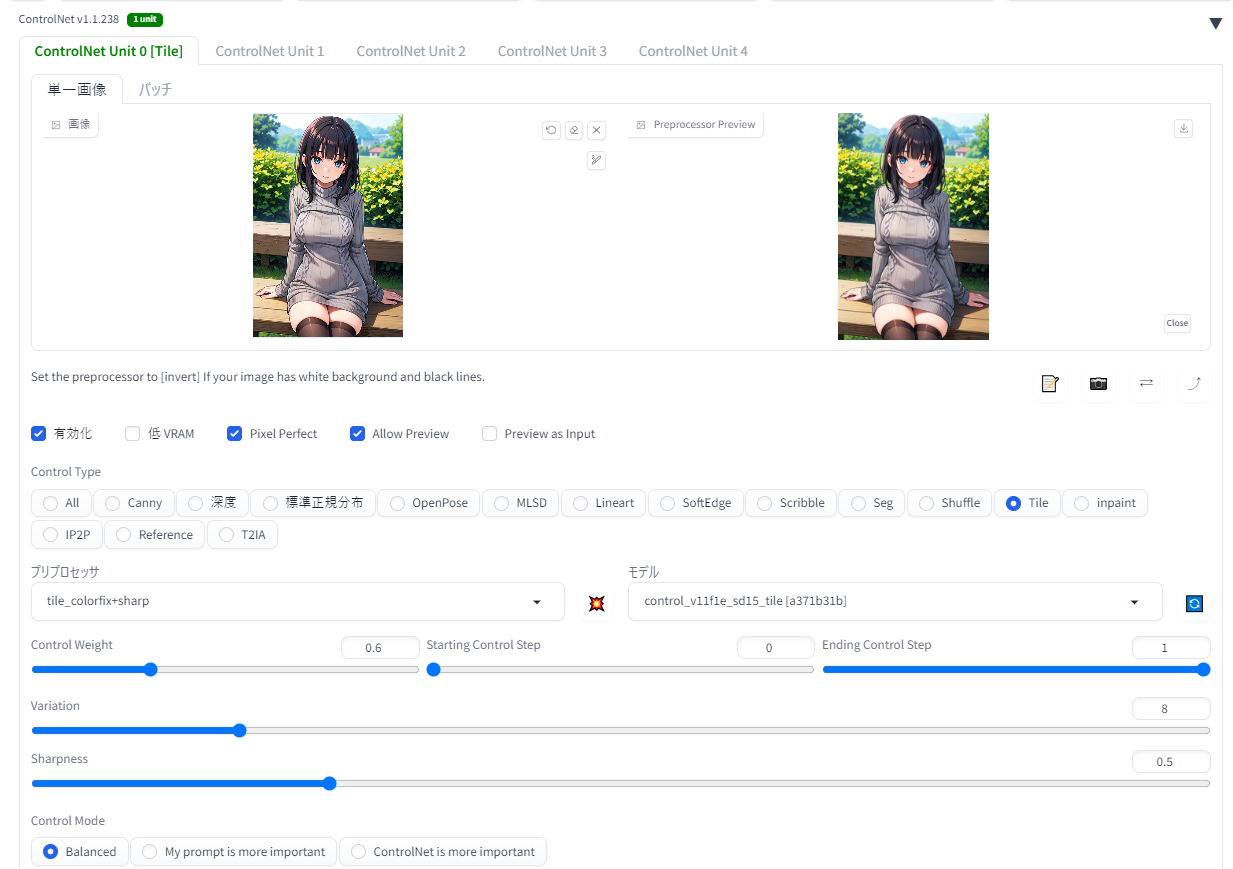
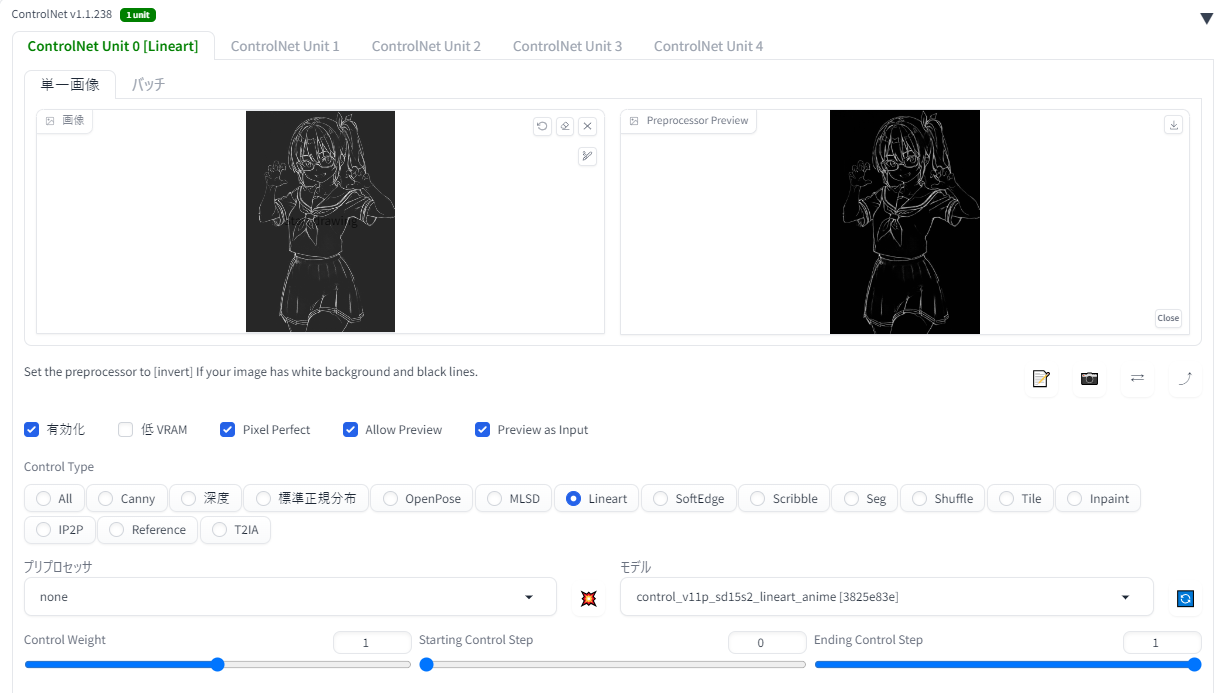
「Tiled Diffusion」をCN「Tile」と組み合わせて、image2imageで通常ではVRAM不足になる高解像度イラストを生成してみます。
CN Tileと組み合わせるときの公式おすすめ設定は以下の通り。
・i2iのノイズ除去強度:0.75以下
・メソッド: Mixture of Diffusers
・Noise Inversion Steps:Noise Inversionを使うなら30以下にする
・Renoise strength:Noise Inversionを使うなら0にする
・Latentタイルの重なり幅(Latent tile overlap):8
今回はこのように、CN Tile(colorfix+sharp)のSharpness0.5、重み0.6で掛けました。
{kind=link}
i2iの設定はこんな感じ。サイズを元画像から4倍に。ノイズ除去強度は0.4としました。
{kind=link}
生成結果がこちら。
{kind=link}
比較画像を見ると、元画像のラインはそのままに高精細化できていることがわかりますが、元画像がおかしいところ(左耳など)も継承されています。こうしたことを防ぐためには、アップスケール前に修正しておく必要があります。
{kind=link}
以上見てきたように、TiledDiffusionはグラボの限界を超えて生成できるものの、一回あたりの生成時間が掛かる上に、設定がそれなりに繊細なため、失敗することも多いです。今回はアニメ調イラストで実験しましたが、公式の比較画像を見ると分かるように、本来はもっとフォトリアルな画像生成に向いた拡張機能と言えるかもしれません。自分の使用Checkpointや好みの描き込み度合いを基に、最適な設定値を探求してみてください。
{kind=link}
LoRAを使った高精細化
さて、イラストをサイズアップするのではなく、イラストの描き込み量を増やしてリッチに見せる「高精細化」は、Controlnetだけでなく、LoRAを使うことでも可能です。この項目では、高精細化に役立つ三種のLoRAを紹介します。
・FLAT2
最も革新的だったのが、以前も紹介した月須和 那々 (2vXpSwA7)様のFLAT2 LoRA。これは他のLoRAと違い、マイナス適用することで描き込み量を増やすLoRAです。
ご覧のように、「1」で掛けるとフラットになりますが、「-1」で掛けると描き込み量がアップしているのが分かります。一方で、背景や衣装の細部なども少し変化しています。
{kind=link}
・Add More Details
こちらも描き込み量が増えるLoRA。Flat2とは違い、通常のLoRAと同じように正方向に掛けることで細部のクォリティがアップします。
こちらが適用例。FlatLoRAよりも被写体が別のものに置き換わることがありますので、InpaintOnlyや人力マージと組み合わせて部分的に使うと良いでしょう。-1~1の範囲ならおおむねうまく作用してくれるようですが、背景や細部に無視できない影響が生じます。
{kind=link}
・Details Tweaker LoRA
こちらはキャラクターなど被写体のデザインをできるだけ維持しながら描き込み量を調整するためのLoRA。こちらは-2(フラット化)~+2(緻密化)の範囲で、どんなタイプのモデルでも描き込み量を調整することができるとのことです。
こちらが生成結果。More Detailesに比べて背景への影響が少ないように見えます。
{kind=link}
いずれも生成結果がイメージしやすく、言ってみれば「調整スライダー」のように描き込み量を調整できるため、非常に重宝します。瞳や衣装の細部、建物などここぞという被写体をピンポイントで高精細化することで、イラストの印象を強めたり、視線をスムーズに誘導することができるでしょう。
絵柄を極力変えたくない場合は
これらのLoRAは画像の描き込み量を増減させるのに非常に便利ですが、背景や衣装が置き換わるのを避けたい場合は、Controlnetと組み合わせて線画を固定したり、ADetailerと組み合わせて顔のみに掛けたりすると良いでしょう(下の記事参照)。ちなみに、拡張機能の「LoRA Block Weight」を使うことで、LoRAが影響する範囲をコントロールすることもできるのですが、やや上級者向けです。
「ADetailer」が理解る!部位別詳細化と5つの「応用」

こんばんは、スタジオ真榊です。今回は「ハンドビューワー」を使った手の修正方法の記事で少し触れた、手や顔といった細部を自動修正してくれる拡張機能「ADetailer」の解説と研究をやっていきたいと思います。 ADetailer(After Detailer)は、通常の画像生成に引き続いてキャンバス内の顔や手といった部位を自動検出し...
こちらはControlnet「LineartAnime」で線画を固定しつつ、FLAT2を掛けた例です。確かに描き込み量は変化しているのですが、線画が強く固定されすぎているため、AIが自由に描画することができず、バキバキとしてやや低劣に感じる出来になっています。
{kind=link}
そこで、Controlnetモードを「Balance」から「prompt is more important」に変えたのがこちら。こうすることで、線画の固定度をほどほどにし、プロンプト(≒LoRA)の効きを重要視させることができます。
{kind=link}
ちなみに、プリプロセッサを「LineartAnime(アニメ線画)」でなく「LineartCoarse(粗い線画)」に変更したのがこちらの例。Controlモードほどではありませんが、線画の固定度合いに差があることが分かります。このあたりは好みですね。
{kind=link}
これらをレイヤーで重ね合わせて「人力マージ」で部位ごとに取捨選択すると、「髪は-2(超高精細)、背景は1(フラット)、服は-1(高精細)」のような表現も可能になります。そのようにして作った画像を「下絵」にしてimage2imageアップスケールすると、下図のようになります。画面全体を「-2」にすると、すべてが濃ゆく描き込まれて見にくいですが、重要でない部分はこれくらいあっさりさせると髪の細密度を強調させることができて良いですね。
{kind=link}
{kind=link}
スタジオ真榊のワークフロー
最後に、スタジオ真榊で画像生成するときのアップスケール手法について触れておきます。基本的には、これまでもワークフロー記事で紹介してきたように「下絵」を作るのが最初のステップ。この段階で全体の構図とキャラクター造形、ポーズ、小物、色合いなどをおおまかに決めておき、必要な修正を加えて、そこからアップスケールしていくことが多いです。普段はControlnetやNiji journeyを組み合わせたかなり面倒な工程を行うのが好きなのですが、今回は割愛して、アップスケール手法だけを簡潔に紹介します。
【Seed探し】
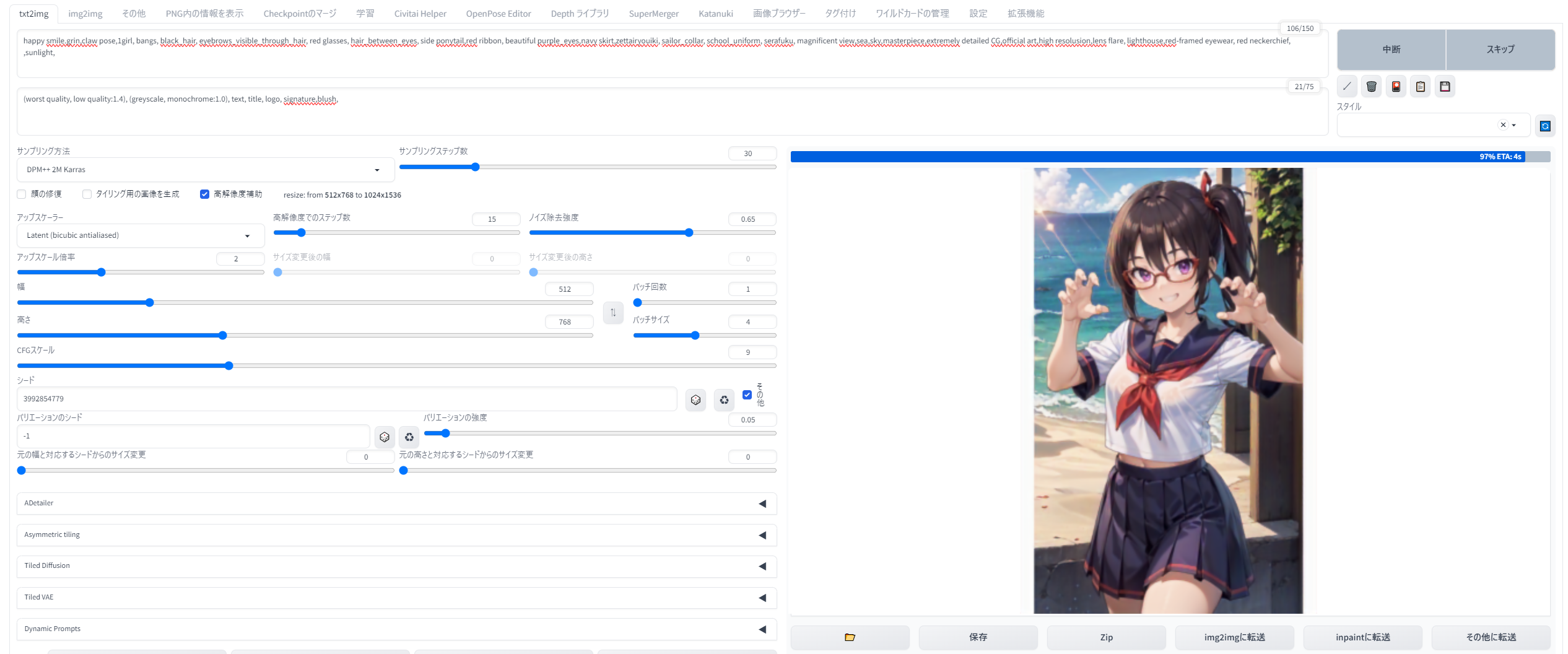
・プロンプトとCheckpointを決め、768x512サイズでまず適切なseed探し(seed値-1にしてForever生成)。大量生成した中で目を引くものをチェリーピック(選別)します。今回はポーズがうまく出たこの右上をピック。
{kind=link}
背景がいまいちなので、ポーズだけLineartで固定しておきます。背景部分を入れ替えたいので、背景の線だけ黒塗りして消してあります。
{kind=link}
【Hiresバリエーション】
さて、今度は高解像度補助をオンにして1.5~2倍サイズに設定。このとき、バリエーション生成を使ってもう一度大量生成するのがオススメです。一発Hiresだと手や衣装、背景に破綻がどうしても生じるのですが、バリエーションの中からチェリーピックすることで、破綻修正の手間を大きく省くことができます。
「惜しい画像」捨てないで!Variation機能の活用法

こんばんは、スタジオ真榊です。日々色んなLoRAを試しては生成、試しては生成で、ぜんぜん本来業務(同人製作)が進んでおりません! 行けるところまで行ききらないと同人の続きが作れる気がしなくなってきたので、もう開き直ってきました。 そんなわけで、今日は「惜しい画像」についての記事です。 皆さん、お目当て...
設定値はこのような感じ。LatentバイキュービックでHiresを2倍掛けし、「その他」にチェックを入れて0.05強度のバリエーション生成を掛けました。1回4枚バッチ生成されますが、Forever生成してももちろん構いません。
{kind=link}
クォリティはこの時点でしっかり上がりますね。背景は固定していないのでまあランダムなんですが、キャラクター部分は固定されているので安心感があります。
{kind=link}
【下絵修正】
次にimg2imgアップスケールを掛けるので、この段階でイメージと違う部分はLamaCleanerや手描き修正などを用いて修正しておきます(雑でOK)。コイカツ!時代の経験から、特に「手の表情」と「視線の向き」が重要だと思っています。手の修正方法はこちらが参考になるかと思います。
posemaniacsに神機能!「ハンドビューワー」でできる手修正

====================================== 2023/08/11:記事後段に新項目「さらに正確に指を再現する」を追加しました。 ====================================== こんばんは、スタジオ真榊です。以前からこのFANBOXでもたびたび紹介してき...
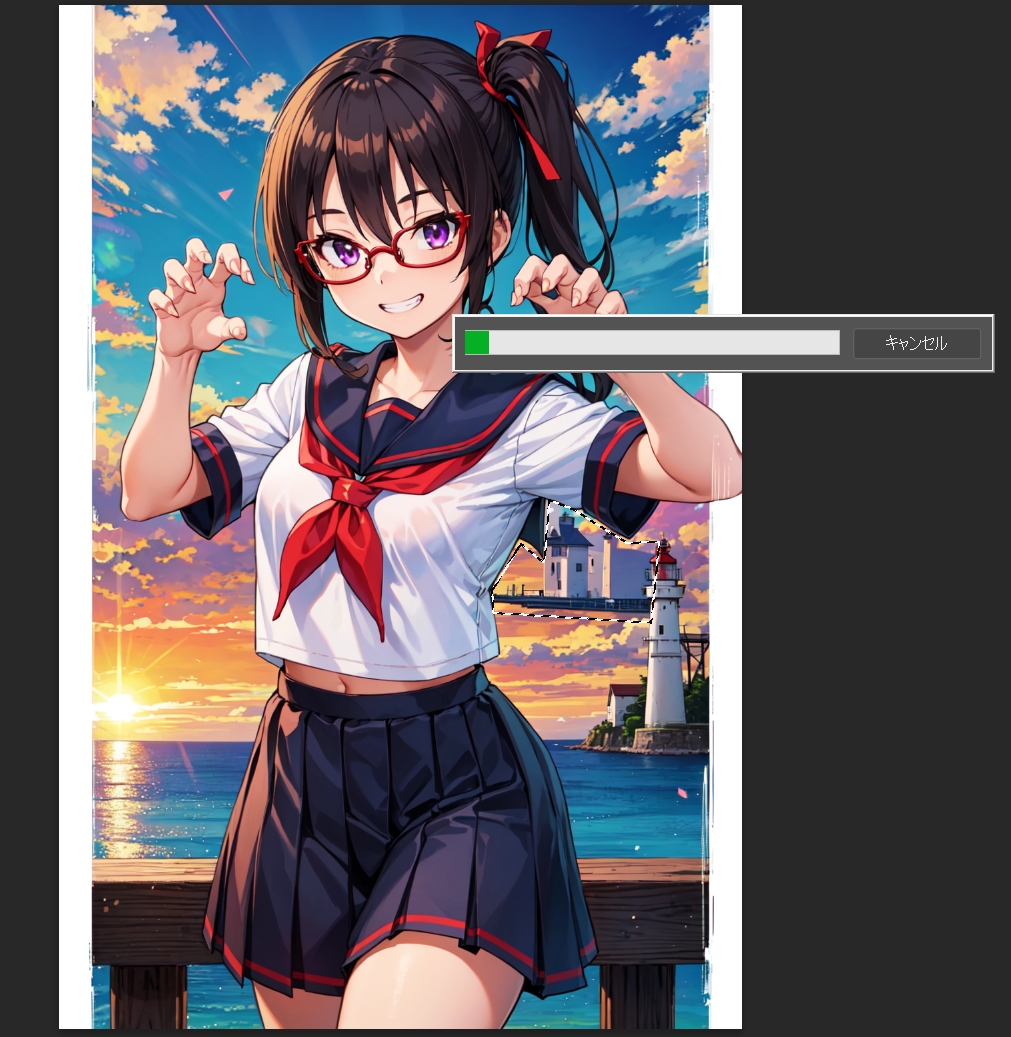
Adobe税をせっかく払っているので、今回は生成塗りつぶしで修正してみましょう。まず、空中に浮かんだ謎の灯台を囲んで消します。
{kind=link}
ポートレート風の左右の白線もついでに削除。
{kind=link}
「claw pose」は可愛いのですが、爪先が尖ってしまう副作用があるので、これも雑に塗りつぶしておきます。周囲からスポイトで色を拾って塗りつぶしただけです。今回は最初の段階でほぼ手の形ができていたので、修正も楽ですね。
{kind=link}
これで下絵が完成です。
【LoRA使用でimg2imgアップスケール】
1536×1024サイズの修正済みHires下絵ができたので、ここからimg2imgアップスケールを掛けていきます。仕上げに向いたCheckpointに変更して、強さ0.3~0.45で「疑似マージ」することが多いです。このとき、描き込み量をアップさせたい場合は、CN「Tile」を併用したり、FLAT2 LoRAを-1前後で適用したりします。
アップスケール後のサイズは2048×1360にすることが多いです(このあたりを超えるとVRAM不足でエラーが起こるため)。高精細すぎるイラストを作ることが少ないので、TiledDiffusionやTiledVAEを使う機会はあまりありませんが、3072x4608pxなどの大きいイラストを生成するときはONにします。このとき、いくつか描き込み量の違うバリエーションを作っておくとよいでしょう。
今回の設定値はこのような感じ。1024x1536から2倍の2048x3072サイズにアップスケールするので、TiledVAEをオンにしてVRAM不足エラーを回避してあります。seed値はもうあまり意味がないのでランダムで。プロンプトは同じですが、 を冒頭に入れて描き込み量を増やします。CNは不使用!
{kind=link}
こちらがアップスケール結果。適当に塗りつぶした手もある程度キレイになっていますね。こちらから下絵と比較することができます。
{kind=link}
【人力マージ&仕上げ】
これで完成でもいいのですが、最後に「人力マージ」をしても良いですね。さきほど最後のアップスケールをする際に、複数のCheckpointを使ったり、FLAT2 LoRAの重みを変更して数種のバリエーションを作っておき、それらをクリスタでレイヤーとして重ね合わせて、消しゴムツールで「良いとこ取り」をします。
ついでに手で修正できるところは全体に修正してしまいましょう。このタイミングでクリスタを使って各種エフェクトを掛けたり、直しきれなかった部分を加筆したりして、ようやく完成。
必要があれば、Extra欄でさらにアップスケールしましょう!
終わりに
ずいぶん長い記事になってしまいましたが、おおむねアップスケールについての基本知識を総覧できたでしょうか。アップスケールの手法はユーザーによって全然違うと思いますし、破綻修正とも密接にリンクしているので、「これ」と言ったベストパターンというのは存在しないと思います。AIイラスト独特の作業ですが、アップスケール手法をたくさん知っておくと、表現の幅が広がるので、「Hiresだけ」とか「img2imgだけ」と言わず、色んなやり方を試してみるのがオススメです。
アップスケールに凝るとどんどん緻密なイラストになりがちなのですが、あまりぎちぎちと詰まったイラストも見にくくなってしまうので、人力マージや消しゴムマジックの力で視線誘導を意識すると、よい結果になることが多いです。
余計な部分を消しゴムマジック!LamaCleanerでできる「修正」と「粗密」

こんばんは、スタジオ真榊です。世間がAdobeの画像生成AI機能「ジェネレーティブ塗りつぶし」に揺れている中、今夜は「消し」に特化したインペイントツール「LamaCleaner」についての検証記事をお伝えします。というのも、ジェネレーティブ塗りつぶしについて検証を行っていくに当たって、その前にどうしても触れておか...
それでは、今日はこのへんで。この記事が、読んでくださった方にとって何かの役に立つことを祈っております。スタジオ真榊でした。
(*記事中の漫画コマ画像は、こちら亀有公園前派出所 第141巻収録『あこがれ
ライダーの巻』/集英社より引用)
Files