Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

【全体公開】AIイラストが理解る!StableDiffusion超入門 (Pixiv Fanbox)
Content
こんにちは!2022年10月からAIイラストの技術解説記事を連載してます、サークル「スタジオ真榊」の賢木イオです。この記事は、これまで投稿してきた100本(約40万文字)を超えるAIイラスト術のFANBOX記事をもとに、画像生成AIを最短距離で学ぶための必要情報をまとめたメインコンテンツです。画像生成AIにもいろいろありますが、当FANBOXでは主に、「StableDiffusion」を使ったイラスト作りの方法を解説しています。
これからAIイラストを学んでみたい初心者の方や、手描きのイラストにAI技術を取り入れてみたい方向けに、できるだけ分かりやすく解説しています。素敵なイラストを思い通りに生成するために覚えるべきことを紹介しつつ、つまずきやすいポイントや参照すべき過去記事、やってはいけないことなどを紹介していますので、最初にこの記事から読んでいただくとスムーズに理解できるはず。
解説役は更木ミナちゃんです。どうぞよろしくお願いします!
{kind=link}
目次
画像生成AIの仕組みをざっくり解説
「StableDiffusionWebUI」とは
画像生成AIをまず触ってみたい人は
必要なマシンスペックは?
グラボ以外のCPUやHDDは?
画像生成に必要な基礎知識
- ①学習モデル
- ②VAE
- ③プロンプトとネガティブプロンプト
- ④ステップとスケール
- ⑤サンプリングアルゴリズム(サンプラー)
- ⑥SEED値
実際にイラストを生成してみよう
インストール後にやるべきこと
学習モデルはどこで入手する?
【注意すべきこと】NovelAIリーク問題
生成した画像は必ず取っておこう
image2imageしてみよう
【重要】画像生成AIでやってはいけないこと
よく聞く「LoRA」って何?
Controlnetでできるようになったこと
中級者になるために
終わりに
画像生成AIの仕組みをざっくり解説
まず最初に、画像生成AIがどうやってイラストを出力しているのかについて、難しいこと一切抜きの「イメージ」で簡単に解説します。
画像生成AIは、教師データとなる多数の画像と文章のペアから学習することで、それに基づいた新しい画像を出力することができるAIです。そうした訓練を積んだAIのことを「学習済みモデル」と呼び、この記事で紹介する「StableDiffusion(以下、SD)」もその一つです。text-to-image(=文章から画像)と言って、「プロンプト」と呼ばれる呪文のようなテキストを入力すると、何を生成したらよいかを判断して、適切な画像を描くことができます。
例えば「1girl,sky,smile」と打ち込まれたら、このように笑顔の少女と空が描かれたイラストを生成します。
{kind=link}
なぜそんなことができるのか。SDは「拡散モデル」とも呼ばれますが、こうしたモデルは「元画像にノイズを加えたものからノイズを取り除く訓練」を積んでいます。その訓練をひたすら繰り返していくうち、AIは全く無意味なノイズからでも、テキスト指示に従って「存在しない元画像」を推測できるようになるわけです。
よくある誤解として、「AIは絵師のイラストを切り貼りしてコラージュしている」というものがありますが、教師データであるイラストそのものはAIの中には記憶されていません。もし何十億枚という教師データを全て記憶していたなら、学習済みモデルが4GB程度で済むはずがありませんよね。AIは学習した画像そのものを使うのではなく、テキストとのペアから学んだ「特徴・傾向」に従ってイラストを生成しているのです。
画像生成は「ステップ」と呼ばれる段階を踏んで行われます。無意味なノイズから「存在しない元画像」を推測する過程を1ステップ、2ステップと繰り返すことで、より鮮明・高画質なイラストができあがっていくわけです。さきほどのイラストの生成過程を見てみますと…
{kind=link}
AIくんは最初、まったく無意味なノイズ画像を渡されて「これは空と笑顔の女の子の画像だよ、ノイズを取り除いてごらん」と言われます(Step0)。健気なAIくんは教師データから学んだ傾向に従って、なんとなくそれらしい感じにノイズを取り除き、ちょっぴり「少女・笑顔・青空」っぽい何かができます(Step1)
その画像が再度AIに渡されて、ノイズを同じように取り除くと、だんだんと空や人間らしきものが浮かび上がってきます。何度もこの工程(ステップ)が繰り返される中で、AIくんはなんとなく「背景に黄色い構造物がある笑顔の女の子」を見出したあと、それをさらに元画像としてノイズ除去していくうちに、黄色い構造物を金髪ツインテールと解釈して、その方向でブラッシュアップが進んでいったことが画像からわかると思います。このように、画像生成AIは「青空を背景に立つ金髪の女の子」のイラストを教師データの中から検索して、それを基に「切り貼り」しているわけではなく、連想ゲームのようにテキストにあった画像にブラッシュアップしているのです。
ただし、AIは「読み込ませた画像のコラージュ」に近い行為をすることもできます。それは「text2image」ではなく「image2image」と呼ばれる別の仕組み。それについては後述します。
「StableDiffusionWebUI」とは
さて、我々がAIイラストを楽しむ方法は、大きく分けて次の3つがあります。
①自分のパソコンにツールをインストールして使う(ローカル生成)
②ウェブ経由のAI画像生成サービスを使う(DALL-E、Midjourney、Niji journey、NovelAIなど)
③クラウド環境にツールをインストールして使う(Paperspaceなどのサービスを利用)
①は電気代以外は無料で利用できるため、自宅PCで好みのイラストを無限に生成できる代わりに、ある程度のマシンスペック(主にグラフィックボード)が要求されます。nsfw(not safe for work、いわゆる18禁)コンテンツなどの生成も自由です。
②、③は利用料金が掛かることが多いですが、画像生成自体は運営側で行われるため、ネット環境さえあれば気軽に楽しめるのがメリット。特に、23年9月20日にOpenAI社(ChatGPTの会社)が発表した最新の画像生成AI「DALL-E3」は、検索エンジン「Bing」上で誰でも無料で生成できる上、予備知識をほぼ必要とせずに高精細なAI画像をイラスト・写真問わず作り出せるとして大変注目を集めています。一方、二次元イラストでは、最低月10ドル(年払い8ドル)の課金で利用できる「Niji Journey」が高い人気を誇っていて、群雄割拠の様相を呈してきていますね。なお、こうしたウェブサービス系(②)は、版権キャラクターや成人向け画像、暴力的画像の生成が制限されているところが多いです。
この記事ではこのうち①を紹介するわけですが、StableDiffusionをローカル環境で使うための代表的ツールが、AUTOMATIC1111氏が配布されている「StableDiffusionWebUI」(以下SDWebUI)です。多くのローカル勢がこちらのツールを使ってAIイラスト生成を行っており、より正確に絵作りを指示できる「Controlnet」などの拡張機能や、よりクォリティの高い学習モデルなどが日々公開され続けています。
ちなみに、A1111版SDwebUIのほかにも、SD.next、ComfyUI、SwarmUI、FooocusなどさまざまなWebUIが登場しており、ユーザーの生成環境は枝分かれしつつあります。こちらの記事で、gitやpythonについて全く知識がなくてもそれらのUIを一発導入できる便利なインストール手法を解説しています。
画像生成AIは「StabilityMatrix」で超簡単インストール!a1111版SDwebUI、ComfyUI、fooocusどれでも一発導入

こんばんは、スタジオ真榊です。こちらは「StabilityMatrix」という便利なアプリケーションを使って、automatic1111版のStableDiffusionWebUI(以下SDwebUI)を始めとしたローカル生成環境を導入する方法についてまとめたHowto記事です。 AIイラストの初心者向け解説については「AIイラストが理解る!StableDiffusion超...
こちらはSDwebUIだけを自分でインストールしたい方向けの解説記事です。「gitやpythonが必要」と言われて抵抗のない方はこちらをどうぞ。
失敗しない!StableDiffusionWebUIを誰でもインストールできる方法

こんばんは、スタジオ真榊です。今回は、初心者向けに改めてStableDiffusionWebUI(以下SDwebUI)をインストールする方法をコンパクトにまとめたHowto記事です。 AIイラストの初心者向け解説については「今から追いつく!AIイラスト超入門」に詳しくまとめてありますが、今回の記事はそちらでは省略した「SDwebUIを実際...
画像生成AIをまず触ってみたい人は・・・
AIイラストを全く触ったことがなく、グラフィックボードなどを買おうか迷っている方は、StableDiffusionに挑戦する前にまず「DALL-E3」や「Niji Journey」を先に体験してみることをおすすめします。とりわけ、Microsoftの検索エンジン「Bing」に搭載された「ImageCreator」では、MicrosoftアカウントさえあればDALL-E3を今すぐ試せるので、初心者はまずこちらで遊び倒すのがいいでしょう。
それぞれのサービスについてはこちらに詳述しています。
画像生成AI「DALL-E3」はどう凄いのか?StableDiffusionユーザーから見た「違い」
にじジャーニーが理解る!「SD✕虹」でできること

「予備知識もグラボも不要で、簡単に高精細なイラストが作れるなら、もう全部DALL-Eでいいんじゃない?」となりそうですが、実はそうではありません。DALL-Eはかんたんな日本語(例:暗い部屋でテレビを見て涙を流すガンダム)で高精細な画像を生成できますが、逆に言えば「基本的にAIお任せ」なので、AIに言葉で伝えられないようなこまかな指示をすることはまだできません。22年9月から進化してきたStableDiffusionはやや操作が難解ではあるものの、より各ユーザーの感性を活かした自由な画像生成が可能である点で、全く異なるAIツールと言えます。
必要なマシンスペックは?
SDWebUIを使うためには、NVIDIA製「GeForce RTX20」シリーズ以降のグラフィックボードが搭載されたPCが必要です。搭載VRAM(ビデオメモリ)の容量は最低8GB、できれば12GB以上のものがないと、GPUに負担のかかる高画質な画像生成や複数同時生成が難しくなります。とはいえ、基本的なイラスト生成だけを楽しむならVRAM8GBでも問題ありません。ただ、後述する「LoRA」などの追加学習を自前で行う場合は、最低12GB以上のグラボが欲しくなってきます。
こちらはツイッター上で実施された、AI術師の利用しているグラボのアンケート結果です。
一番のボリューム層が、スタジオ真榊でも利用しているコスパ最強グラボ「RTX3060(12GB)」。RTX3060にはVRAM8GBモデルもあるのですが、もし購入するのであれば12GBモデルを強くオススメします。高価なグラフィックボードほど1枚の画像生成に掛かる時間が短縮され、高解像度なイラストの複数同時生成も可能になりますが、GPUの性能が低いと、生成途中にVRAMが圧迫され、しばしば「CUDA out of memory」エラーが発生してしまいます。
ただ、FANBOXではVRAM4GBでもちゃんと動いているとの情報も寄せられていますし、賢木が以前使っていたGTX1060でも時間は掛かるもののちゃんと画像生成できたので、いきなりグラボを買う前にまずは試してみるのがいいかもしれません。
5万円のRTX3060を買ったら作業効率が天翔龍閃した件

こちらは23年1月に旧世代の「GTX1060」からRTX3060に交換した際の全体公開記事です。生成速度の違いを動画で比較しています。当時3060は5万円以上しましたが、この記事を書いている23年8月現在は4万円を切りました。
1月に調査されたさきほどの術師グラボTier表によると、RTX3060の次のボリュームゾーンはRTX3090、その次がRTX4090です。あるサイトでそれぞれの画像生成速度を比べたところ、RTX3060に比べ、3090は約2倍、4090は約4倍の速さで同じ画像を生成できたという調査結果が出たそうです。その後、グラボの価格はかなり下がってきていますが、RTX3060の次に視野に入ってくるグラボといえば、85000円程度から購入できるRTX4070(VRAM12GB)でしょう。さらに上が、ついに25万円を切ったRTX4090(同24GB)。これからAIイラストを始めるのに、いきなりこの世界に飛び込める人はなかなか少ないと思いますが、富裕層・好事家の方はぜひ挑戦してみてください。
いずれにせよ、自信を持っておすすめできるエントリーモデルはRTX3060で間違いないかと思います。画像生成AIとグラボについては、「ちもろぐ」さんのこちらの記事に大変詳しくまとまっており、あらゆるモデルの実力が網羅されているので、購入検討されている方はぜひ参考にされてください。
グラボ以外のCPUやHDDは?
では、CPUやディスク容量についてはどうでしょうか。WebUIにおける画像生成は基本的にはGPU依存なので、よほど古いCPUを積んでいなければ大丈夫と言われています。ある程度生成速度には差が出るようですが、GPUほど明確な差は出ません。むしろ、画像生成や追加学習中にいろいろな作業をする場合は、メモリをできるだけ増設しておくことをおすすめします。
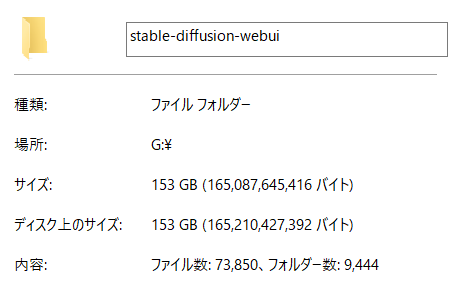
一方、HDD容量については、あればあっただけ良い!2TB欲しい!という感じです。学習モデルは一つあたり4~8GBほどありますし、Controlnetに必要なモデルもかなりストレージを圧迫します。さらに、外出中にも高解像度の画像をバカスカ無限生成していくとなると、最低でも100GBは開けておきたいところです。
おすすめなのは、HDDでなくSSDを増設して画像生成関連専用のドライブにしてしまうことです。スタジオ真榊では7月にこちらの中華SSDを12,980円で購入しました。読み込みは早いし容量はたっぷり余裕があるしで、大変買って良かったです。最近はグラボだけでなくSSDも安くなっているので、思い切ってパソコンごと買い換えてしまうのもよいかもしれませんね。(ドスパラではRTX4070搭載モデルが20万円から出ていました)
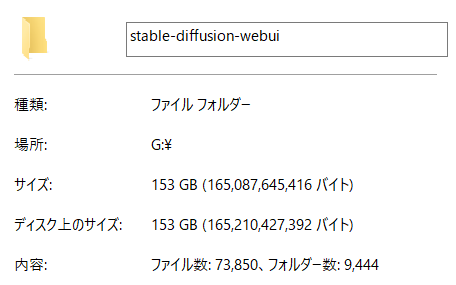{kind=link}
ちなみに、現在賢木のSSD内に保存されているSDwebUIのフォルダサイズを見てみたところ、153GBありました。生成した画像は別ドライブに保存しているので、SDwebUIを動かすのに必要なデータやCheckpoint(学習モデルのことです。詳しくは後述)、Controlnet用の各種モデル、LoRAなどの追加学習関連ファイル等でこのサイズです。
ただ、このうち収集したCheckpointだけで94GBを占めていたので、1~2種類あれば十分という方はこれほど大きいサイズにはなりません。ご参考まで。
画像生成に必要な基礎知識
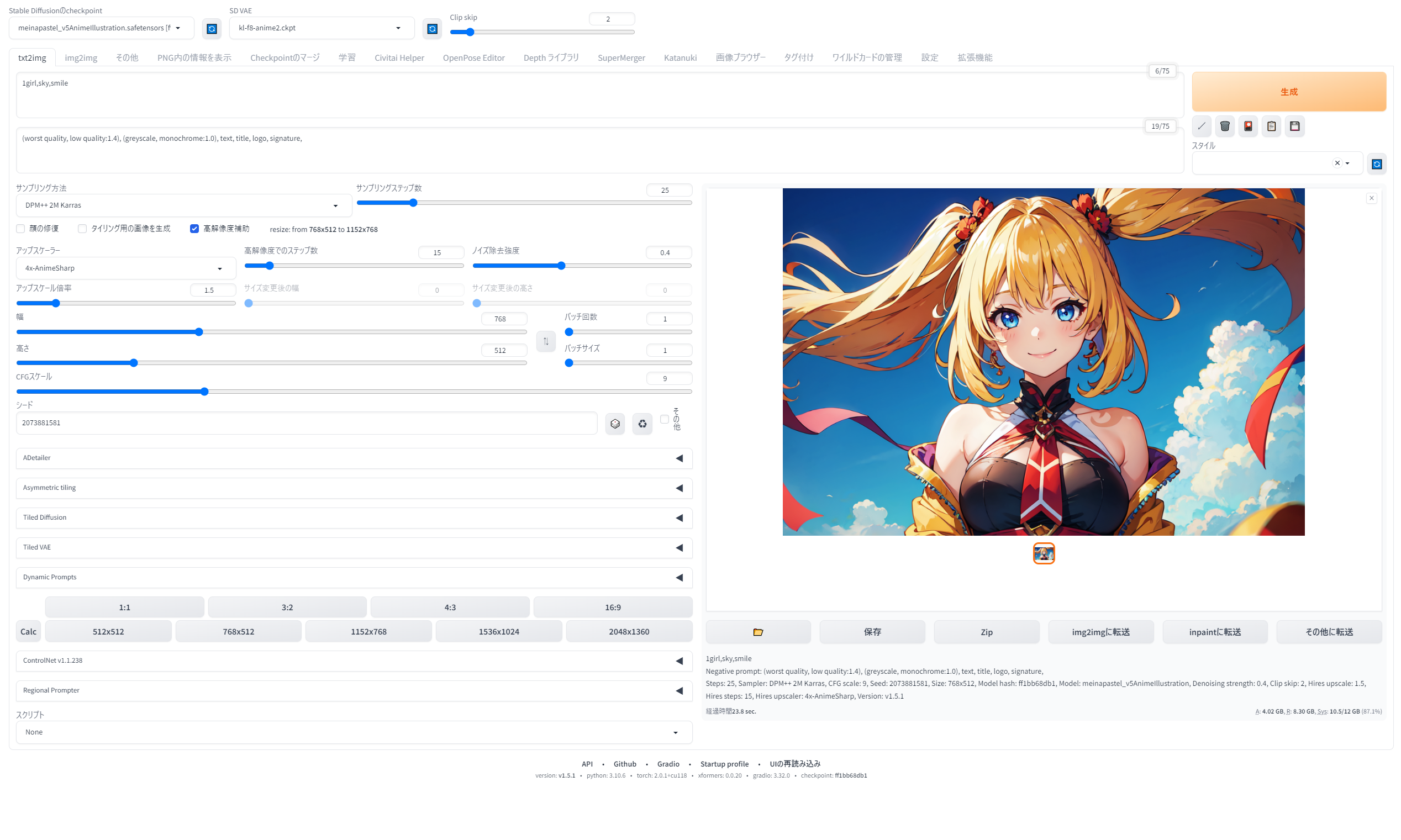
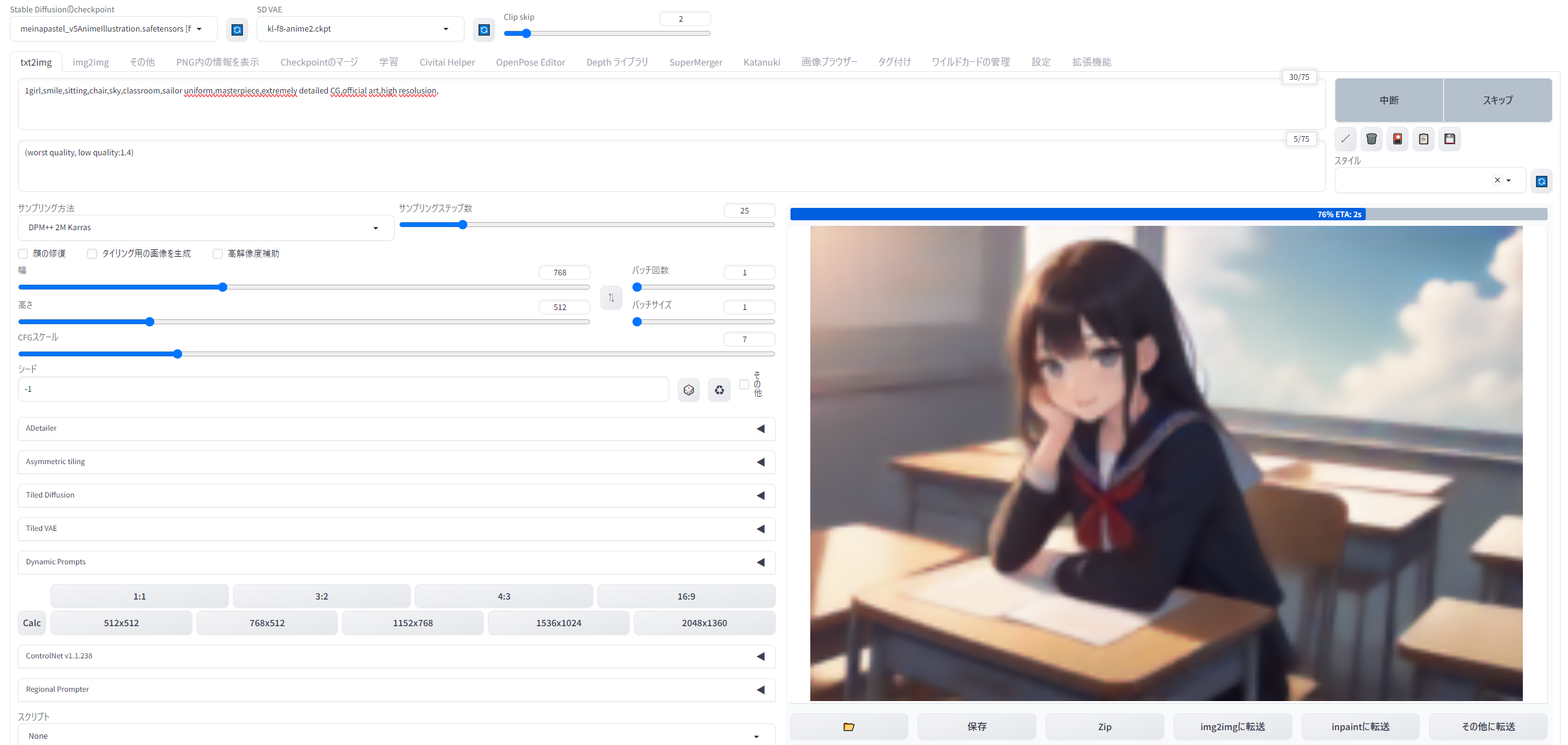
さて、PC環境が整い、無事SDWebUIをインストールできたら、さっそく画像を生成していくことになります。こちらがWebUIの操作画面です。
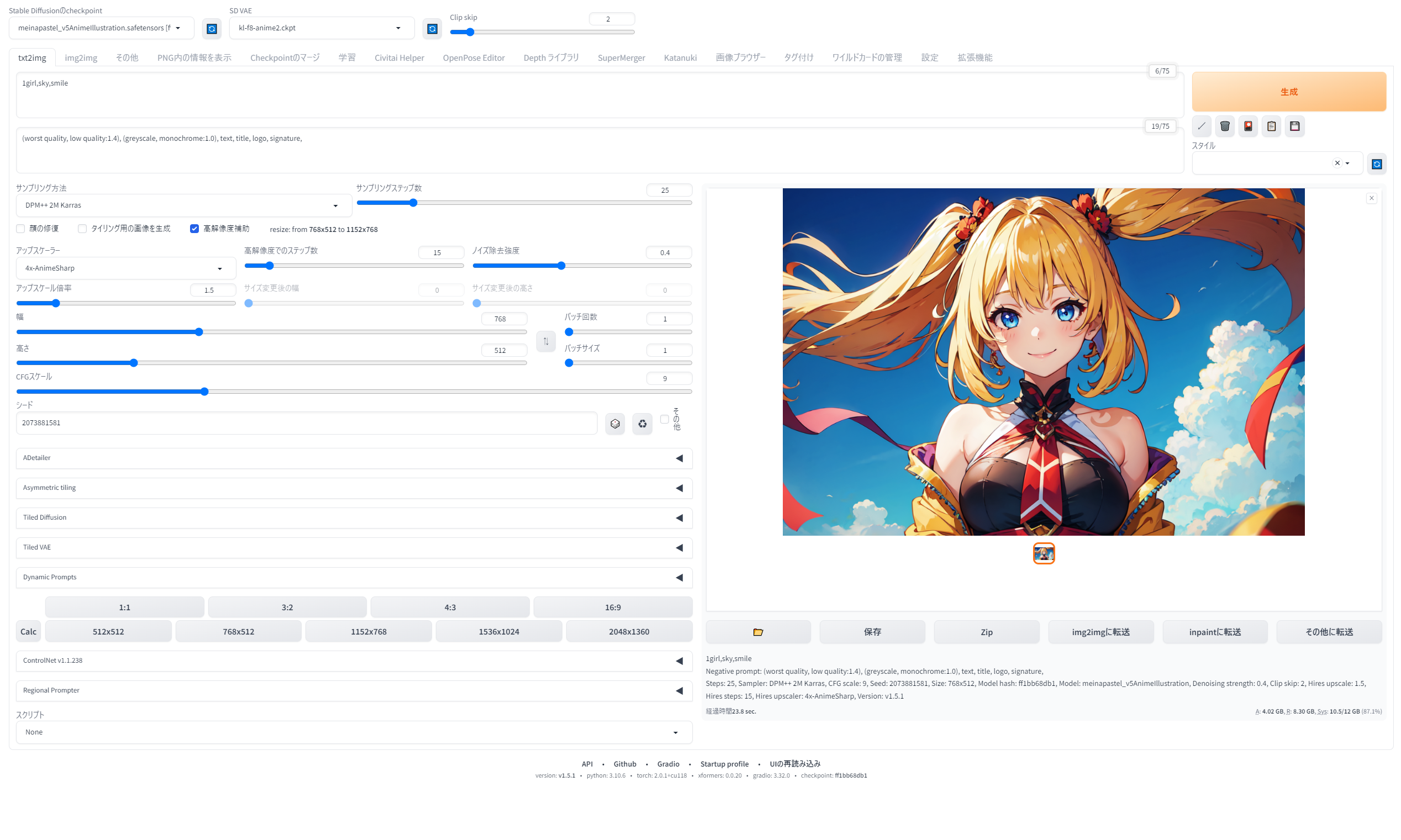{kind=link}
日本語化した上、拡張機能も多数導入していますので、インストールしたての画面とは異なることをご了承ください。
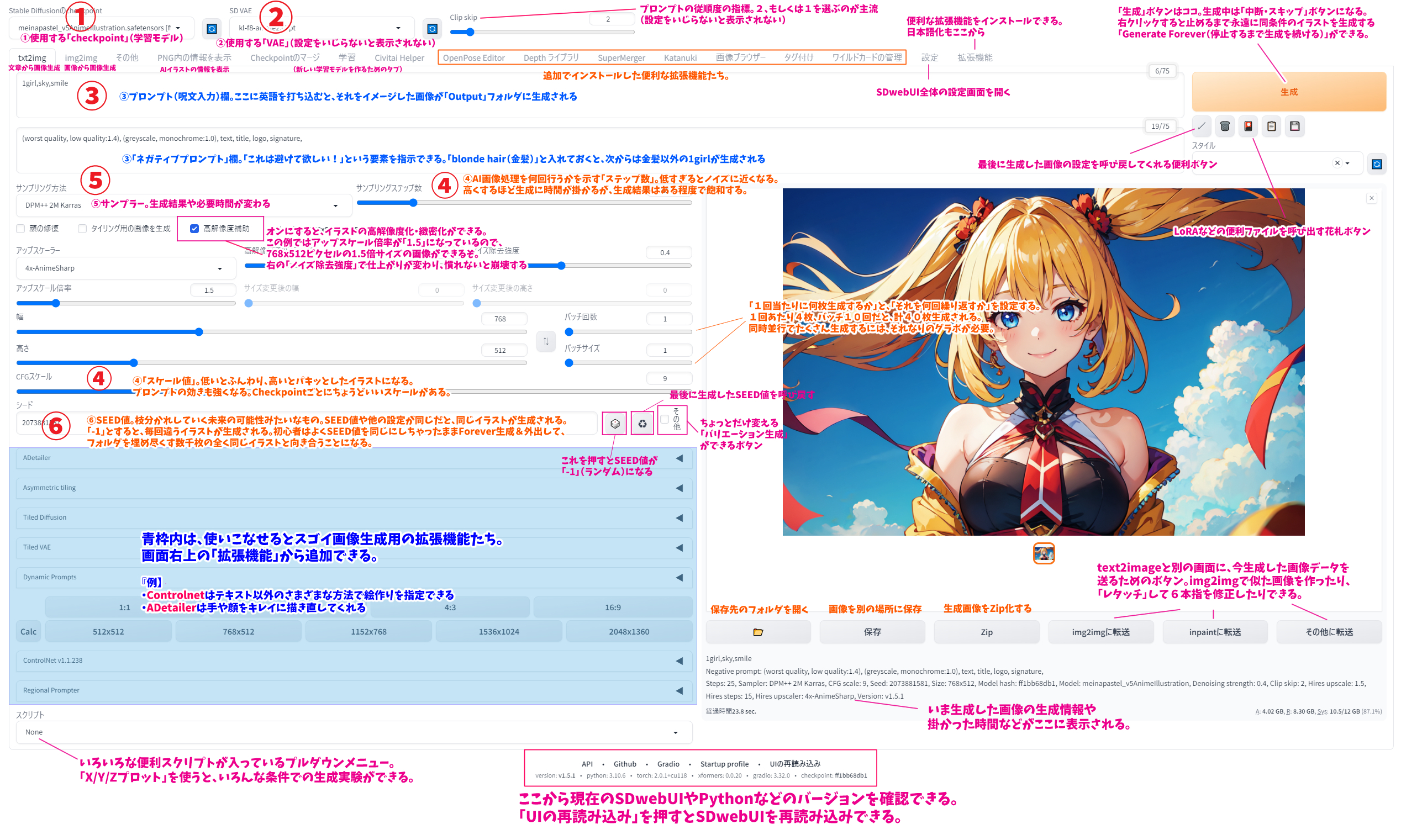
初めてだと何がなんだかわからないと思いますので、こちらに画像の説明文を作りました。拡大してご覧ください。画像内の大きな数字①~⑥は、下記の項目ごとの数字に対応しています。
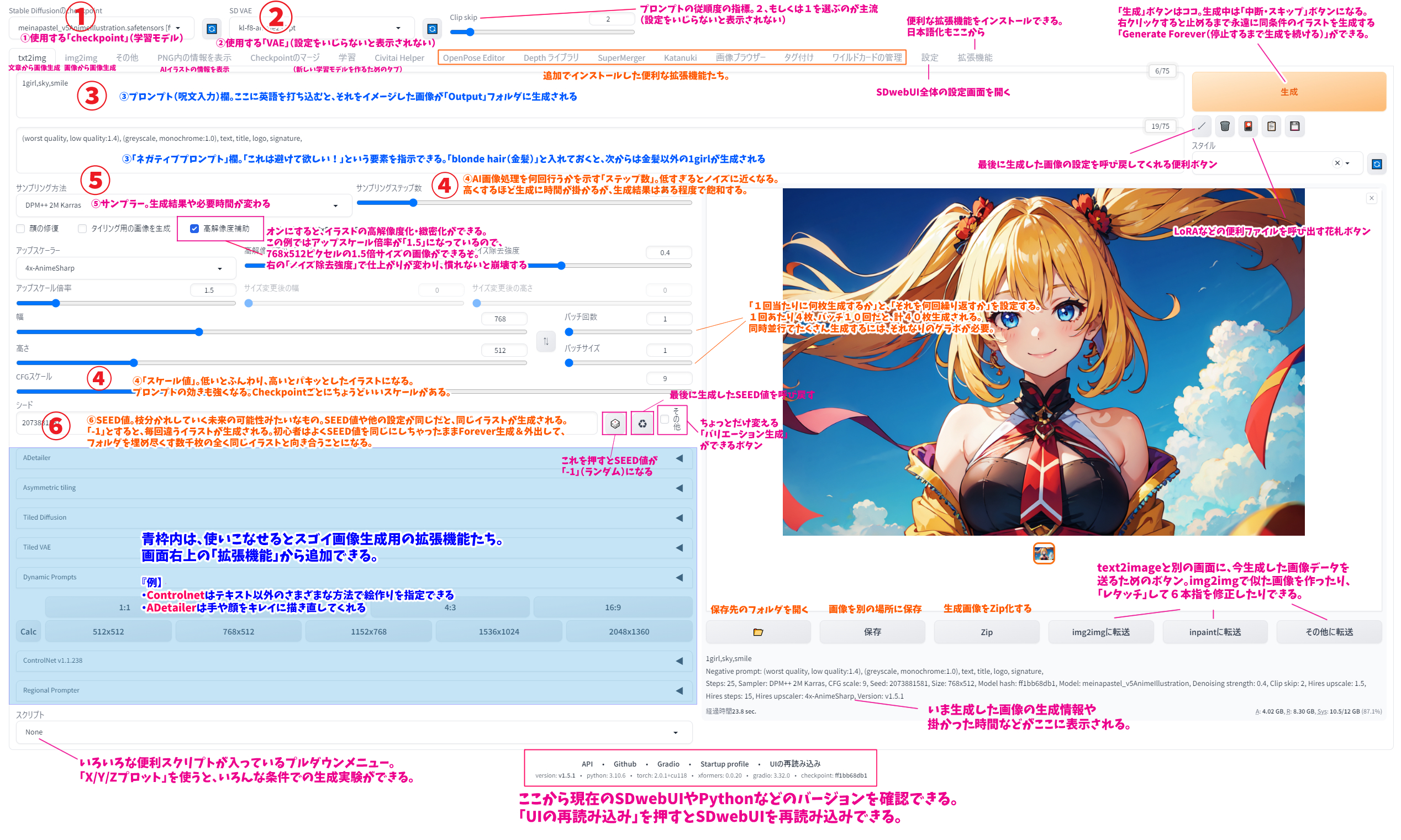{kind=link}
①学習モデル(Checkpoint)
SDwebUIはAIではなくただのインターフェースですので、それ単体では画像生成を行うことができません。大量の画像とテキストのペアから学習した「学習済みモデル」と組み合わせる必要があります。『Checkpoint』や、単に『モデル』とも呼ばれますが、実写のようなフォトリアルな画像に特化したものや、アニメ調のイラストが得意なモデル、緻密で美しい風景の再現が得意なモデルなど、主に学習させたデータセットによりさまざまな特徴・種類があります。
つまり、どんなモデルを使うかによって、生成されるイラストやテキストの再現度は大きく変わることになります。学習モデルは拡張子「.ckpt」または 「.safetensor」で、一つあたりおよそ4〜8GBの前後の容量があります。拡張子によって生成結果に変化はありませんが、safetensorsはckptにあった問題点を改善したものとされており、現在はこちらが主流です。
学習モデルは既存のものを融合させて好みのものを作り出すことができるため(マージと言います)、さきほど説明したLoRAと同様、日々無数のモデルがウェブ上に投稿され、共有されています。学習モデルによってライセンス表記があり、「生成画像の商用利用禁止」などのルールが定められているので、必ずチェックした上で使用する癖をつけましょう。
【注意喚起】使用モデルのライセンスを再確認しよう!

こんばんは、スタジオ真榊です。今日は学習モデルのライセンスをめぐって界隈がちょっとざわついた件をめぐる、「もう一回自分の使っているモデルのライセンスを確かめてみよう!」という注意喚起系の記事です。 このたび「ChilloutMIX」というフォトリアル系の人気モデルのライセンス表記が急に変更となったのですが、...
②VAE
「Variational Autoencoder」の略。何をしているかを説明するにはまず、拡散モデルの画像生成AIには「テキストエンコーダ」「U-NET」「VAE」の三つのモジュールがあり、潜在空間上でノイズ除去が・・・などなどというややこしい説明が必要なのですが、ここでは割愛します。
「人間がプロンプトを指示」▶「テキストエンコーダが翻訳」▶「U-NETが不思議空間でAIにしか見えないお絵描きをする」▶「VAEが人間にも分かる『絵』に翻訳してくれる」という、画像生成プロセスの最後の部分を担当する役割だと理解すれば十分です。
{kind=link}
VAEによって何が変わるかというと、学習モデルが生成した画像の「見栄え」「色合い」が変化します。こちらの画像は、全く同じ生成設定でVAEだけを変更したもの。右は色合いがビビッドになっていることがわかります。(胸のリボンなど細かい意匠も微妙に変化しています)
{kind=link}
学習モデルやLoRAなどに比べるとあまりたくさんのVAEが流通しているわけではなく、「なぜか色が褪せて見えるな?」と思ったら別のVAEを使ってみる、程度の認識でOKです。学習モデルごとに対応するVAEが配布されていることもありますが、賢木はずっと同じVAE「kl-f8-anime2.ckpt」を使っています。保存先は「models\VAE」です。
③プロンプトとネガティブプロンプト
プロンプトとネガティブプロンプトは、Text2image(文章から画像生成)における最も重要な要素。AIはプロンプト欄に書かれた呪文を基に画像を生成します。「1girl,smile,sky,school uniform,peace sign,looking at viewer」などと、基本的にはカンマ「,」で区切って、盛り込みたい要素を箇条書きで並べていくだけでOKです。「被写体は何人でどんな構図か、どんな見た目の誰がどこで何をしているか、どんな画風か」を指定するのがコツ。正しい「呪文」でないと認識しないわけではなく、DeepL翻訳でざっくり英文化して放り込んでもけっこう理解してくれます。
スペルを間違えても理解してくれることがありますが、「white hair ribbon」と指示したらキャラの髪が白くなってしまった("white hair"+ribbonと誤解された)、ということもたまにあるので、上手な意思疎通をするにはコツが要ります。分脈より、あくまで書いた単語に反応しがちな傾向があります。
{kind=link}
「何を生成するか」を指示するプロンプトに対し、「何を生成しないか」を入力する欄であるネガティブプロンプトも同じくらい重要です。「金髪はだめ」「男は描くな」と指示するだけでなく、「低品質な画像はダメ」と指示すると高品質になるので、この2つがうまく釣り合うことで素敵なイラストが生成できるようになります。
詳しいプロンプトの書き方については、こちらの記事にまとめてあります。「超入門」の次にこちらを読むと、画像生成がスムーズにできるようになっていくと思います。
プロンプトが理解る!基本から上達法まで、1万5000字で徹底解説

ローカル生成におけるプロンプト・ネガティブプロンプトについては「プロンプト辞典」に詳しくまとめているので、慣れてきたらこちらをご参照ください。また、chichipuiなどのAIイラスト投稿サイトでは、先輩術師さんのプロンプトがイラストと一緒に公開されていますので、大変参考になります。
髪型指定からエロ用語まで!画像生成AI用プロンプト辞典

現在はモデルや生成環境の多様化が進み、Controlnetを始めとしたさまざまな手法も登場したため、プロンプトは以前ほど大きな存在ではなくなってきています。それでも、やはりどんなイラストが生成されるかはプロンプトが大きく左右するもの。まずはいろんなプロンプトを試して、text2imageに習熟するのが上達への道です。
ちなみに、AIを使う人が「AI術師」と呼ばれることがあるのは、呪文のようなプロンプトを駆使して画像生成するから。「AI絵師」と呼ぶ人もいますが、この表現は努力して手描きイラストのスキルを積んできたクリエイターの気分を害することがあり、自称する人は減っています。スタジオ真榊では単に「画像生成ユーザー」と呼ぶことが増えてきました。
④ステップとスケール
ステップは AI がノイズを取り除く作業の反復回数のこと。先程「青空と少女」のイラストで実験したとおり、ステップ1だと、まだ意味のないノイズからさほど離れることができず、ぼんやりした概念のようなものが生成されます。ステップ数が多いほど絵のクオリティが上がる反面、生成に時間がかかります。適正なステップ数は使用する学習モデルにもよりますが、「テスト生成は12以上、本番生成なら20以上推奨」が目安。
スケールは直感的にわかりにくいですが、「プロンプトの再現度」に近い概念です。低スケールだと柔らかい絵画風になり、高スケールにするほどディティールが細かく描写され、AIがより厳密にプロンプト(ユーザーの指示)を再現しようとします。学習モデルごとにおすすめのスケール値が案内されていることが多いので、それを参考にして好みに調整してみましょう。
{kind=link}
こちらは「青空と少女」のスケールを1、3、5、7…と変化させたもの。どれも25ステップ掛けて生成しているので、概念のようなぼやけた絵にはなりませんが、このようにそれぞれ違う結果になりました。
ちなみに、こういう比較実験画像は「X/Y/Zプロット」というスクリプト機能で簡単に作ることができます。
X/Y/Z plotで初めてのモデルと仲良くなろう!

⑤サンプリングアルゴリズム(サンプラー)
AIがノイズ処理する際のアルゴリズムのこと。Euler a, Euler, LMS, Heun, DPM2, DPM2…といろんな種類があり、同じ学習モデル・SEEDでもサンプラーを変えると雰囲気がだいぶ変わります。人気なのは軽さとクォリティが両立した「DPM++ 2M Karras」と、少し重めですがクォリティに定評のある「DPM++ SDE Karras」。これも、学習モデル配布時におすすめのサンプラーが案内されていることが多いです。
こちらはやや長くなりますが、AOM3というCheckpointでサンプラーだけを変えて同じ画像を生成してみた実験結果です。
{kind=link}
同じプロンプト・設定でも、サンプラーによって全然違う画作りになることが分かると思います。ちなみに、崩壊してしまっているのはそのサンプラーが悪いわけではなく、ステップやスケールなどが最適な設定ではなかったのだと思われます。
⑥SEED値
乱数を作成するときの最初の設定値のことをシード(種)値と言います。画像生成AIにおいては、生成画像ごとに割り当てられている固有の背番号のようなものと考えてみてください。全く同じプロンプト指示をしても、このSEED値が異なると違うイラストが生成されますし、同じSEED値を指示すると、プロンプトが多少変わっても似たイラストになります。以前生成したイラストと全く同じものを生成するためには、このSEED値が不可欠になります。
生成するたびに同じイラストが作られてしまうと困るので、普通はseed値を固定したくありませんよね。seed値を毎回ランダムにするためには「-1」と入力するか、欄の横のサイコロボタンを押せばOK。おおむね好みのイラストができたけれども、ちょっと変えたいとか、クォリティをアップしたいときに、このseed値が役に立つことになります。
{kind=link}
「外出中に無数のエッチ画像を作るよう指示したはずなのに、最後に生成したイラストのseed値が入力されたままになっていて、帰ってきたら数千枚の全く同じエッチ画像がフォルダを埋め尽くしていた…」というのが術師あるあるです。
インストール後にやるべきこと
日本語化やxformersによる高速化など、インストール前後にやっておくべきことは基本的にこちらの記事に書いてありますので、まずはこちらをご参考に。
失敗しない!StableDiffusionWebUIを誰でもインストールできる方法
こんばんは、スタジオ真榊です。今回は、初心者向けに改めてStableDiffusionWebUI(以下SDwebUI)をインストールする方法をコンパクトにまとめたHowto記事です。 AIイラストの初心者向け解説については「今から追いつく!AIイラスト超入門」に詳しくまとめてありますが、今回の記事はそちらでは省略した「SDwebUIを実際...
テスト生成が無事できるようになったら、「設定」タブから以下のように設定を変更することをおすすめします。
【おすすめ初期設定】
・「保存する場所」で画像の保存先を決める。デフォルトは「Output」フォルダだが、ストレージに余裕がなければSDwebUIと別のドライブに変えてもよい。
・「フォルダについて」で、保存先にサブフォルダを作るか決める。「サブフォルダに保存する」を選ぶと生成日ごとにフォルダ分けできる。
・「UI設定」内の「テキストからUIに生成パラメータを読み込む場合(PNG情報または貼り付けられたテキストから)、選択されたモデル/チェックポイントは変更しない」欄にチェックを入れる。入れないと不意に面倒な学習モデルの再読み込みが起きるので、とりあえず最初に入れておく。
・「UI設定」内の「クイック設定」欄に「sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layers」と入力。こうすると、先程の解説画像のようにVAEやClipSkipを表示する欄が画面上部に表示される(再読み込みが必要)
・画面上部のプルダウンメニューからVAEを変更する。インストール解説とは異なりますが、個人的にはwaifu-diffusion-v1-4のVAE「kl-f8-anime2.ckpt」が彩り豊かでおすすめ。保存先は「(SDwebUIのインストールフォルダ)\models\VAE」です。
学習モデルはどこで入手する?
さて、ここまでがStableDiffusionで画像生成するための基礎知識です。インストールがうまくいき、プロンプトやスケール値がどんなものか理解できれば、少なくとも「1girl,smile,sky」というプロンプトでイラスト生成することまではできるようになっているはずです。では、イラスト生成のクォリティに直結するモデル(checkpoint)やVAEなどをみなさんどこで入手しているのかというと、「HuggingFace」や「Civitai」といった海外プラットフォームが主な流通場所となっています。
「HuggingFace」は学習済みの機械学習モデルやデータセットなどを公開している米国発のプラットフォーム。下記のCIVITAIに比べてより技術者寄りで、アップデートや技術討論などが盛んに行われています。WebUI用の拡張機能などはこちらで配布されることが多いです。
{kind=link}
「CIVITAI」はStable Diffusionのモデルをアップロードできる海外プラットフォーム。こちらはHuggingFaceに比べてより一般ユーザー寄りで、多くのユーザーが学習モデルのほか、「LoRA」や「Textual Invarsion」と呼ばれる追加学習のファイルなどを公開しています。無修正の18禁画像などもバンバン出てくるアングラムード漂うサイトなので、自己責任でご利用ください。
※サインアップ方法や基本的な使い方は「LoRAでキャラ再現!15分でできる追加学習入門」で解説しています。
【注意すべきこと】NovelAIリーク問題
ここで一つ、AI術師として経緯を把握しておくべき事件があります。2022年10月、ブラウザ上でアニメ調のAIイラスト生成が楽しめる有償サービス「NovelAI」のモデルが何者かにハッキングされ、ウェブ上に流出する事件がありました。(詳しい経緯はジャーナリスト・新清士さんの「画像生成AIの激変は序の口に過ぎない」および「AIの著作権問題が複雑化」参照)。流出したCheckpointそのもの(以下リークモデル)を勝手に販売したり、それを使ったサービスを提供したりすることは、NovelAI運営側に対する不正競争防止法違反や権利侵害となるリスクがあります。本来はNovelAIにお金を払わないと生成できないはずのイラストがローカルで作れてしまうわけで、多くのAIイラストコンテストでも、リークモデルを使った作品の投稿は禁じられています。
問題はここからで、学習モデルは別のものとマージ(融合)することができるため、その後リークモデルをマージしたとされる「Anything v3.0」を始め、無数の派生モデル(以下リークマージモデル)がウェブ上で公開されてきました。リークモデル、リークマージモデルそれぞれに対し、NovelAI運営側がどのような法的対応を取るのかは現時点で明らかにされていません。ただ、例えリークマージモデルの配布者が「商業利用可」としていても、NovelAIに対する権利侵害に当たるのではないか?という懸念がぬぐえない状況となっています。
リークマージモデルかどうかは、配布者が「レシピ」を公開していて分かる場合もあれば、分からない場合もあります(例えばAbyssOrangeMixシリーズの一部にはリークモデルがマージされていることが明かされています)。リークモデルの二次派生モデルを、そうと知らずに別の人物がマージした三次モデルが配布されているケースもあるかもしれません。リークモデルにパーミッションやライセンスなどあるはずがないので、その派生モデルの法的な扱いは非常に不安定です。特にこうした学習モデルの商業利用を考えている場合、権利関係が複雑化しており、自己責任が強く問われる現状になっています。
学習モデル配布者の示しているパーミッションを遵守するのは当然として、モデルの出自によっては自分で使用用途を判断し、リスクを勘案して自己防衛するしかないことを書き留めておきます。
【注意喚起】使用モデルのライセンスを再確認しよう!
こんばんは、スタジオ真榊です。今日は学習モデルのライセンスをめぐって界隈がちょっとざわついた件をめぐる、「もう一回自分の使っているモデルのライセンスを確かめてみよう!」という注意喚起系の記事です。 このたび「ChilloutMIX」というフォトリアル系の人気モデルのライセンス表記が急に変更となったのですが、...
◆次世代モデル「SDXL」の登場で沈静化?
ただ、その後もすべての始祖であるStableDiffusionのアップデートが続いており、2023年7月26日にStable Diffusion XL(SDXL)がリリースされました。これまで最もポピュラーなのはStable Diffusion1.5で、流通しているCheckpointも1.5をベースにしたものが多い(そしてその中にリークマージモデルも多数混入している)のですが、今後SDXLが普及していけば、自然と上記のNAIリーク問題をめぐる疑心暗鬼も沈静化していくものと思われます。
実際にイラストを生成してみよう
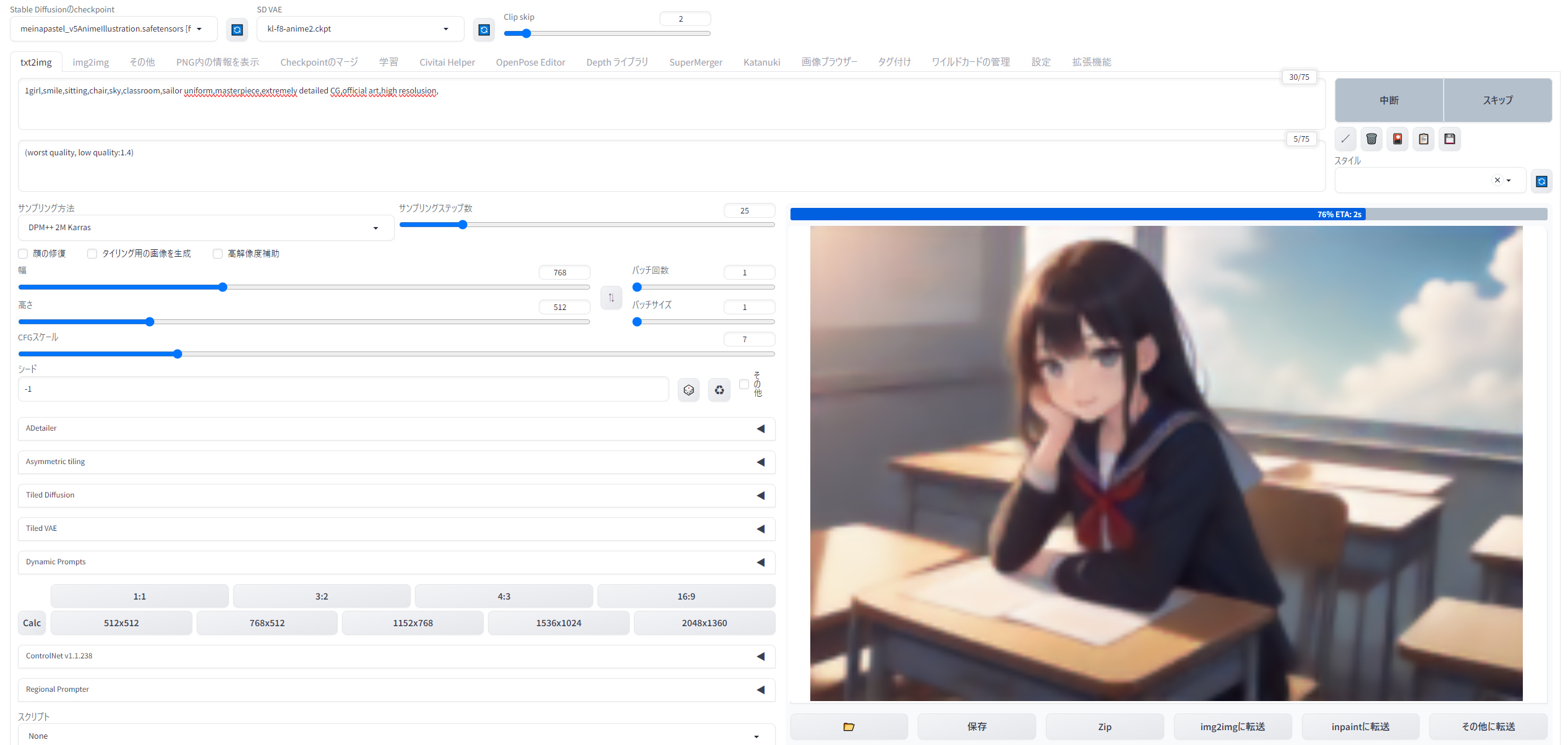
さて、ここまでの基礎知識を覚えたら、あとは実行するだけ。一緒にテスト生成をやってみましょう。
このテストではHuggingFaceからダウンロードしたMeinaPastelというCheckpointのVer.5(SD1.5ベースのアニメ調モデル)を使用しましたが、各自の判断で好みの学習モデルをご使用くださっても構いません。
{kind=link}
リンク先からダウンロードしてきたmeinapastel_v5AnimeIllustration.safetensorsを「stable-diffusion-webui\models\Stable-diffusion」のフォルダに放りこめば、左上のプルダウンメニューに表示されます(表示されない場合は横の青い更新ボタンを押しましょう)。VAEはさきほど紹介したwaifu-diffusion-v1-4のvae「kl-f8-anime2.ckpt」を使います。
プロンプト欄には「1girl,smile,sitting,chair,sky,classroom,sailor uniform,masterpiece,extremely detailed CG,official art,high resolusion」
ネガティブプロンプト欄には「(worst quality, low quality:1.4)」と入力します。このネガティブプロンプトは入れておくと画像のクォリティが上がるもの。サンプラーは軽くて良質な効果が期待できる「DPM++ 2M Karras」、ステップ25、スケール7。Seed値は「-1」(ランダム)とします。
準備ができたら、右上の「生成」ボタンをクリック。
{kind=link}
私の環境では、このような画像が表示されました。「セーラー服姿の女の子が1人、笑顔で教室の椅子に座っており、空が映り込んでいる良質で高画質なCG」というプロンプト通りのものが描かれていますね。
学習モデルやSeed値によってそれぞれ全く違うイラストが生成されたことと思いますが、望む結果は出たでしょうか。ちなみにこのイラスト、「高解像度補助(Hires.fix)」を効かせていないので、まだ実力の半分も出せていません。
「高解像度補助(Hires.fix)」は、生成された画像を縮小してスケールアップ、縮小してスケールアップを繰り返すことでより緻密にクォリティアップしてくれる機能。今度はこれをオンにしてみます。MeinaPastelの配布ページの「Show more」というところをクリックすると、配布者によるおすすめ生成設定が書かれているので、これを参考にしましょう。
{kind=link}
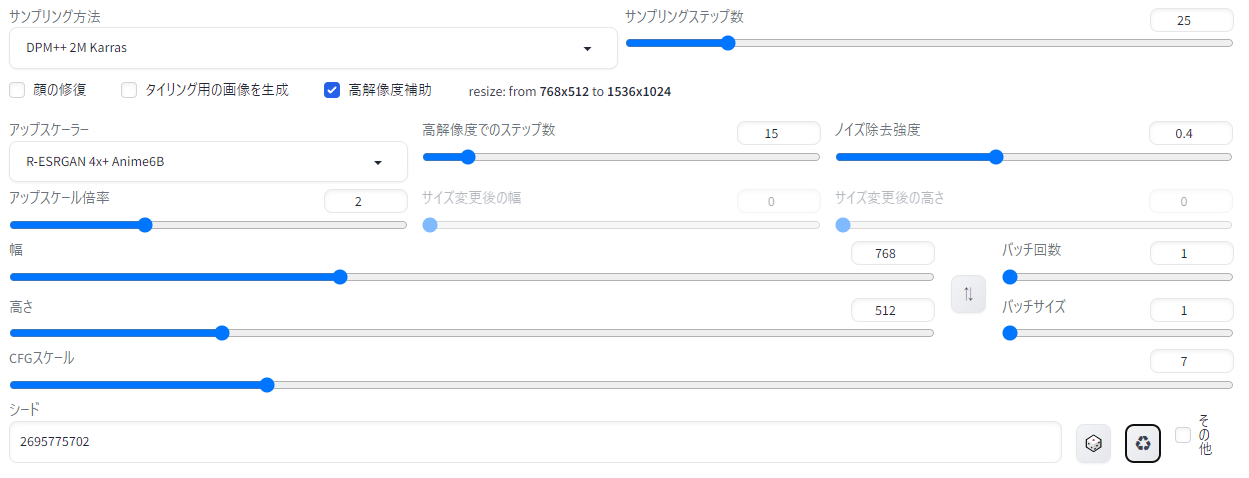
「スケールは4~11がおすすめ」「サンプラーはDPM++ 2M Karras/SDE Karras/euler aあたりで、ステップ20~40くらいで生成してね」といったことが書いてありますが、「Hires.fix」という欄に「R-ESRGAN 4x+Anime6bを15ステップ、ノイズ除去強度0.4で掛けてね」とあるのがわかります。
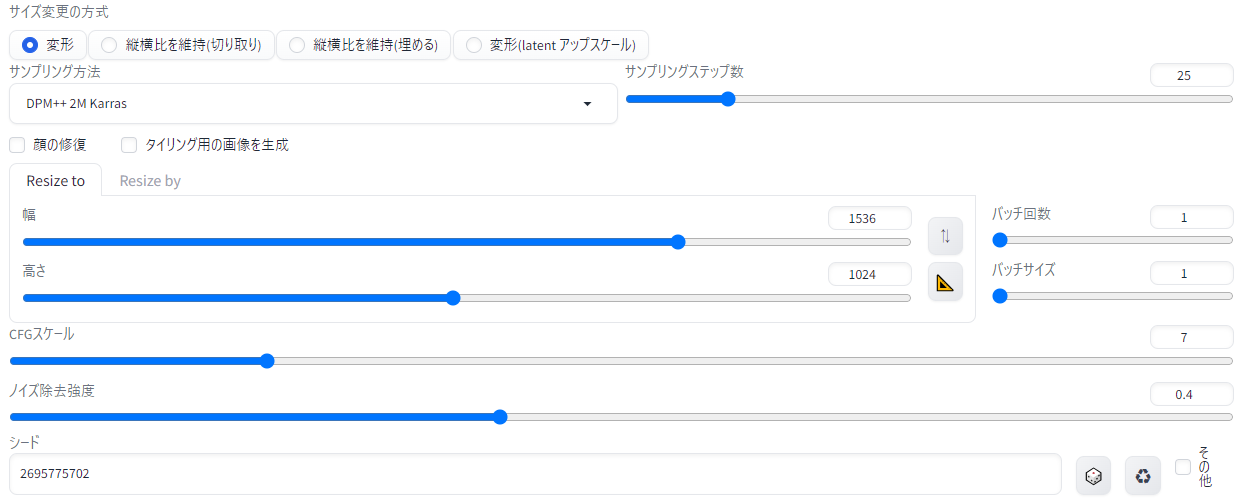
Hires.fixの「アップスケーラー」はサンプラーと同様にいくつも種類があるのですが、今回は「R-ESRGAN 4x+Anime6b」を使います。下図のように設定してみましょう。「高解像度でのステップ数」が高解像度補助を何ステップ掛けるか、ノイズ除去強度は高解像度補助をどれくらいの強さで掛けるか、アップスケール倍率は768x512サイズの画像を何倍のサイズに高画質化するか…といったことを示しています。
ついでに、さきほどの教室の女の子と同じ画像にしたいので、右下のリサイクルボタンを押して直前に生成した「シード値」を呼び出しました。これで、同じ画像に高解像度補助を2倍で掛けた画像が生成されるはずです。
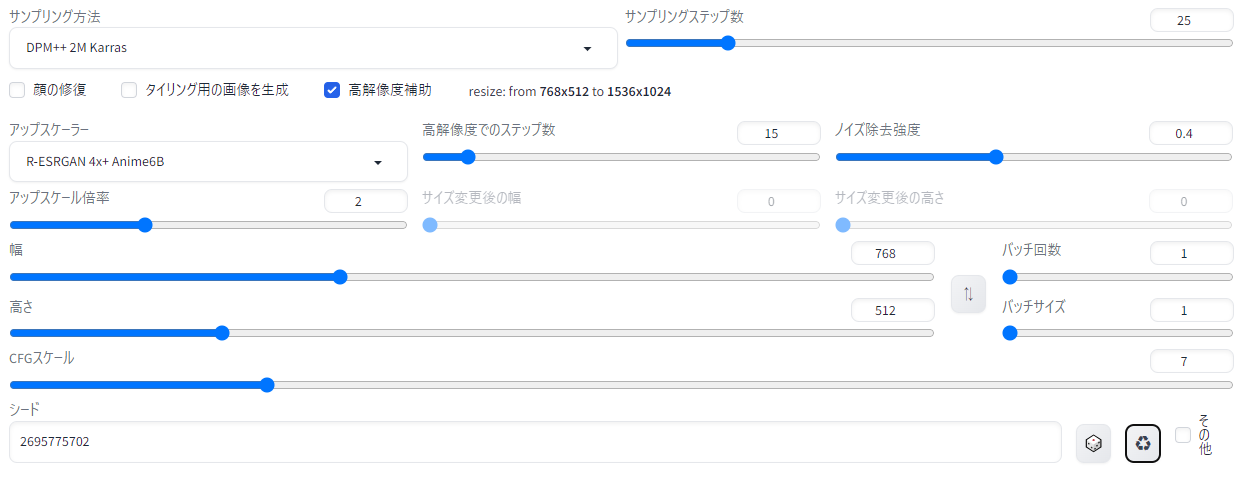{kind=link}
※なお、こちらの記事に高解像度補助の種類別結果やサンプラーを総当たりした実験結果を掲載していますので、高解像度補助の各アップスケーラーの特徴について詳しく知りたい方は参考になるかもしれません。
最適設定を探せ!「AbyssOrangeMix3」最速レビュー

こんばんは、スタジオ真榊です。本日、賢木も愛用している「AbyssOrangeMix」の最新バージョン、「AOM3」が公開されました!カワイイ、アーティスティック、そして遠慮のないエロと三拍子そろったAOM2は層別マージモデルの傑作だったわけですが、その進化形となる「AOM3」は一体どんなモデルなのか?さっそくレビューし...
さきほどの設定で生成したのがこちら。
{kind=link}
このように美しいイラストに仕上がりました!
GIF動画で比較してみましょう。
{kind=link}
おおむねほぼ同じものが描かれつつ、明らかにクォリティアップしていますね。
ただ、よく見ると背景の机は位置や形状がおかしいですし、教室の背後に窓があるのもやや不自然です。壁に書いてある文字もよく考えると意味不明。これがAIイラストの弱点である「意図しないオブジェクトの生成」と「文脈の欠如」です。テキストベースの連想によって画像が作られるがために、「一見ちゃんとしているけどよく考えるとおかしいもの」が普通に出てしまうんですね。
たとえばこちらの画像は、一瞬美麗ですが、たくさんのミスがあります。すぐあとで解説するのですが、いくつ見つけられるでしょうか?
{kind=link}
シンキングタイム!
{kind=link}
はい、めがねのことは気にせず、こちらの画像をご覧ください。パッと見て分かるレベルでもこれだけありますし、もっと細かく見ていくとさらにたくさんの「おかしさ」が見えてきます。
{kind=link}
破綻ではありませんが、「文脈上」おかしいこともあります。例えば、左右の腕に巻いているフリルが何なのかよくわかりませんし、左右でデザインが違っています。瞳の塗り方もアップでみると瞳孔が溶けていて少し不気味。海でこんな格好をしているのもよく考えるとおかしいですよね。
髪になぜ花?髪飾り?をつけているのでしょう。
そのポーズの意味は?
カメラ側には誰がいて、どんな状況なのでしょう?
ChatGPTは「それらしい嘘をもっともらしく並べるAI」と言われていますが、画像生成AIも「それらしい嘘イラストをもっともらしく作ってくれるAI」です。どちらも生成物は一見して人間が作り出したものに酷似しているのですが、正確性はまだまだ。意味や意図のあるイラストに見せるには、人間の手助けが必要です。
AIイラストに見慣れるとこうした破綻に気づきにくくなってしまうのですが、ポン出し(適当なプロンプトでササっと生成しただけのAIイラスト)ならともかく、作品として世に出す場合はここから時間を掛けて微修正を繰り返すことになります。
こうした「意図しないオブジェクト」を修正するのに最適なのが、「LamaCleaner」。詳しくは個別記事をご覧いただきたいのですが、キャンバス内の余計なものを簡単かつ自然に消すことができます。
余計な部分を消しゴムマジック!LamaCleanerでできる「修正」と「粗密」

Adobe税を払っている方は、Phoshopベータの「ジェネレーティブ塗りつぶし」を使うのもオススメ。AIイラストでは手が破綻することが特に多いのですが、一旦立ち止まって他にも変なところがないかよく考えてみると、より素敵なイラストにすることができます。
生成した画像は必ず取っておこう
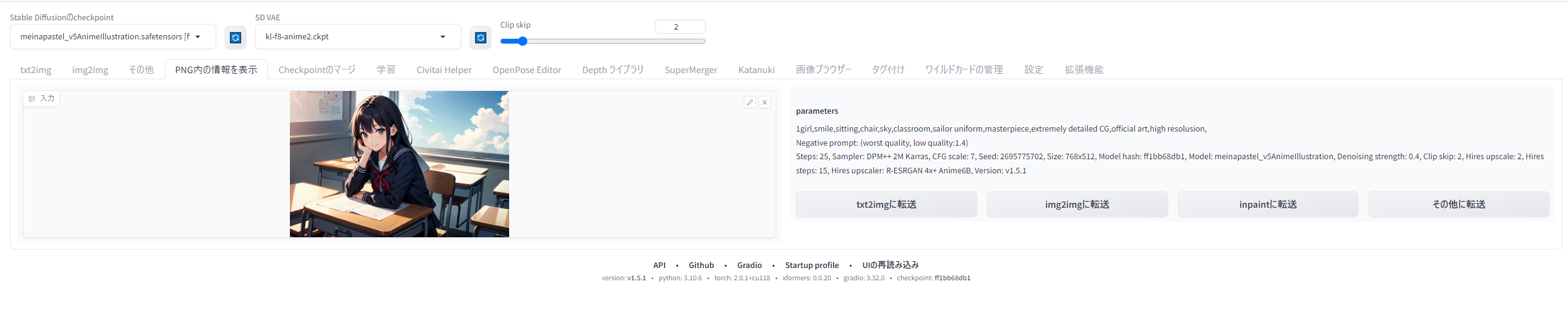
{kind=link}
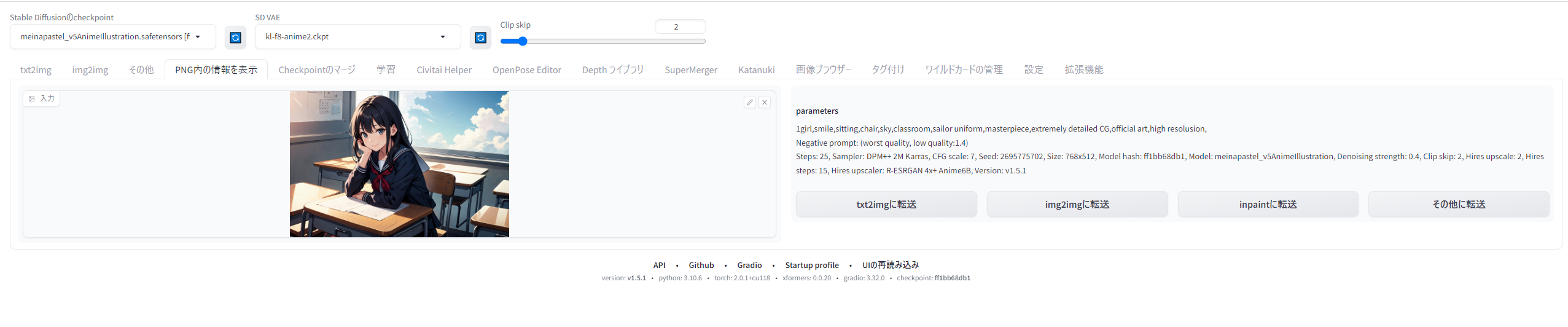
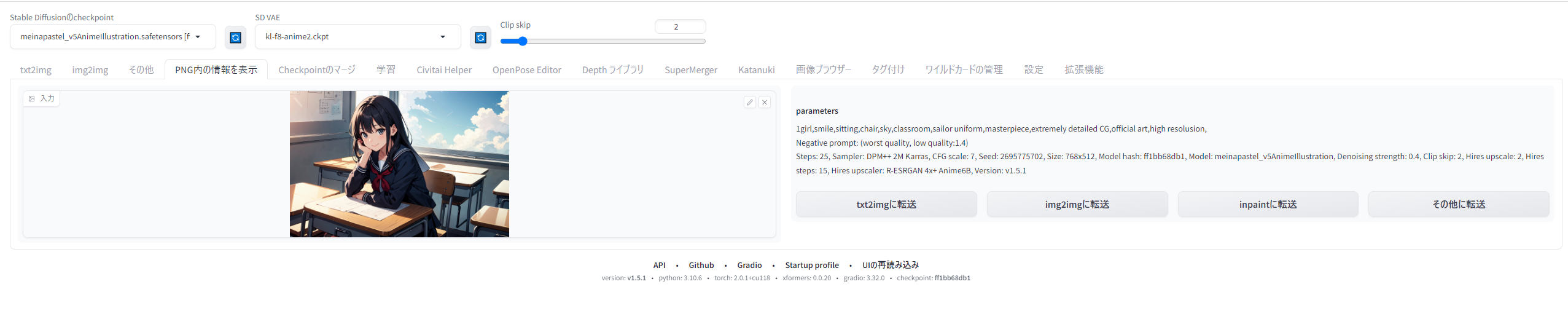
StableDiffusionで生成されたAIイラストのpngファイルには、Seed値やプロンプト、生成サイズといったあらゆる情報が保存されています。text2imageのタブの2つとなりにある「PNG内の情報を表示」タブで読み込ませると、生成時の情報をいつでも呼び戻すことができ、ボタンひとつでtxt2imageのページにすべての情報を飛ばすこともできます(▲)。不要になったイラストも、あとでどんな役に立つかわからないので、削除せず大事にとっておきましょう。
pngを大事に取っておくべき理由はもう一つあります。AIイラストやそのユーザーに向けられている目は依然として厳しく、SNSなどに投稿していたら、「既存のイラストのパクリではないか」と突然疑われてしまうことがあるかもしれません。そういったときも、そのイラストのpngに内包されているプロンプトやseed値といった情報や、前後に生成したイラスト群がきちんと残っていれば、自分がそのイラストを試行錯誤しながら生成したことを示す最高の証拠になります。無断転載した人物に「自分こそが本来の生成者だ」と自称されたときも、投稿画像にExif画像が残っていなければ相手は同じ画像を二度と生成できないので、容易に自分が本来の生成者だと証明することができます。
こちらは、実際にAIイラストレーターが盗作を疑われた例。生成した経緯や意図をきちんと証明することができれば、このように疑いを晴らすことができます。(この例では、SDではなくNiji journeyが使われています)
image2imageしてみよう
さて、ここまで説明してきたのは、完全なノイズ画像からプロンプトを頼りにイラストを作る「text2image」のやり方でした。画像生成AIを使ったもう一つの生成法が「image2image」、つまりノイズ画像からではなく、参考となる画像をもとにイラストを作る方法です。細部の書き込みを増やすクォリティーアップに使えるだけでなく、プロンプトを変更することで、おおむね構図を維持しながら、別のイラストに変えることができます。
※ちなみに、このimage2imageをイラストの一部だけに作用させる「インペイント」という機能もあります。これは、良い部分は残して、気に入らない部分だけをピンポイントでレタッチ(修正)するimage2imageです。
レタッチ(inpaint)機能が理解る!修正&入れ替え徹底解説

実際にやってみましょう。まず、さきほどテスト生成した画像を、「PNG内の情報を表示」タブで読み込ませます。するとこのような画面になります。
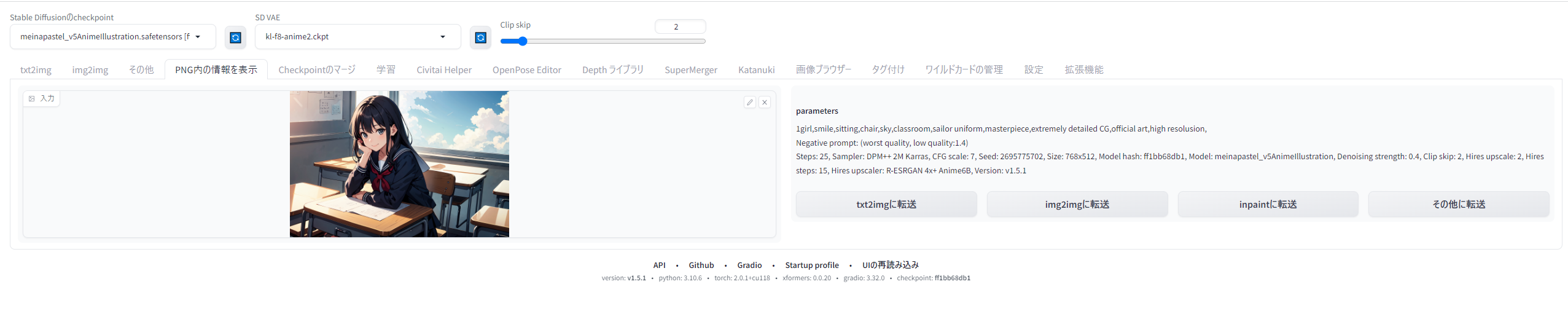{kind=link}
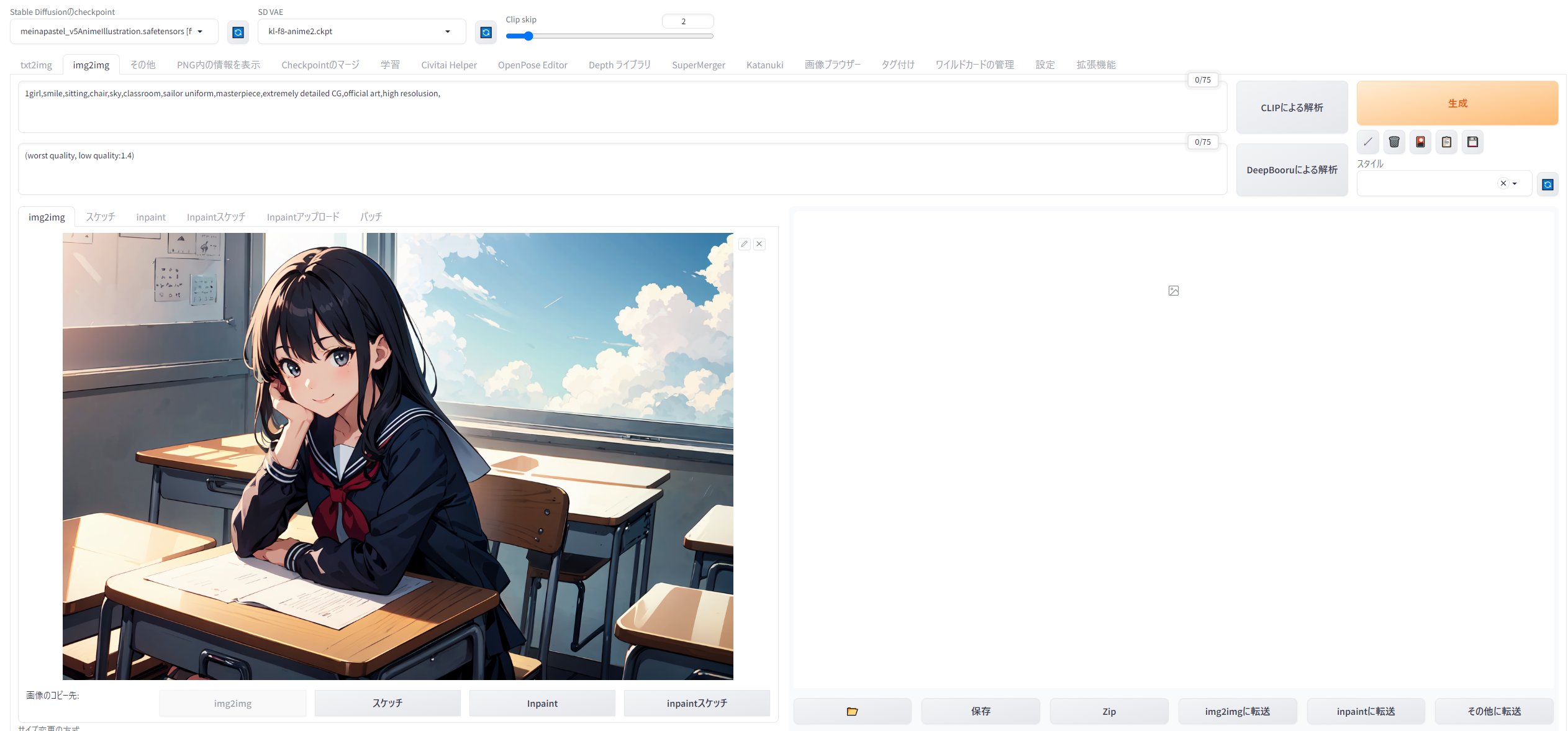
「img2imgに転送」ボタンを押すと、この画像と生成情報がすべてimg2imgのタブに転送されます。
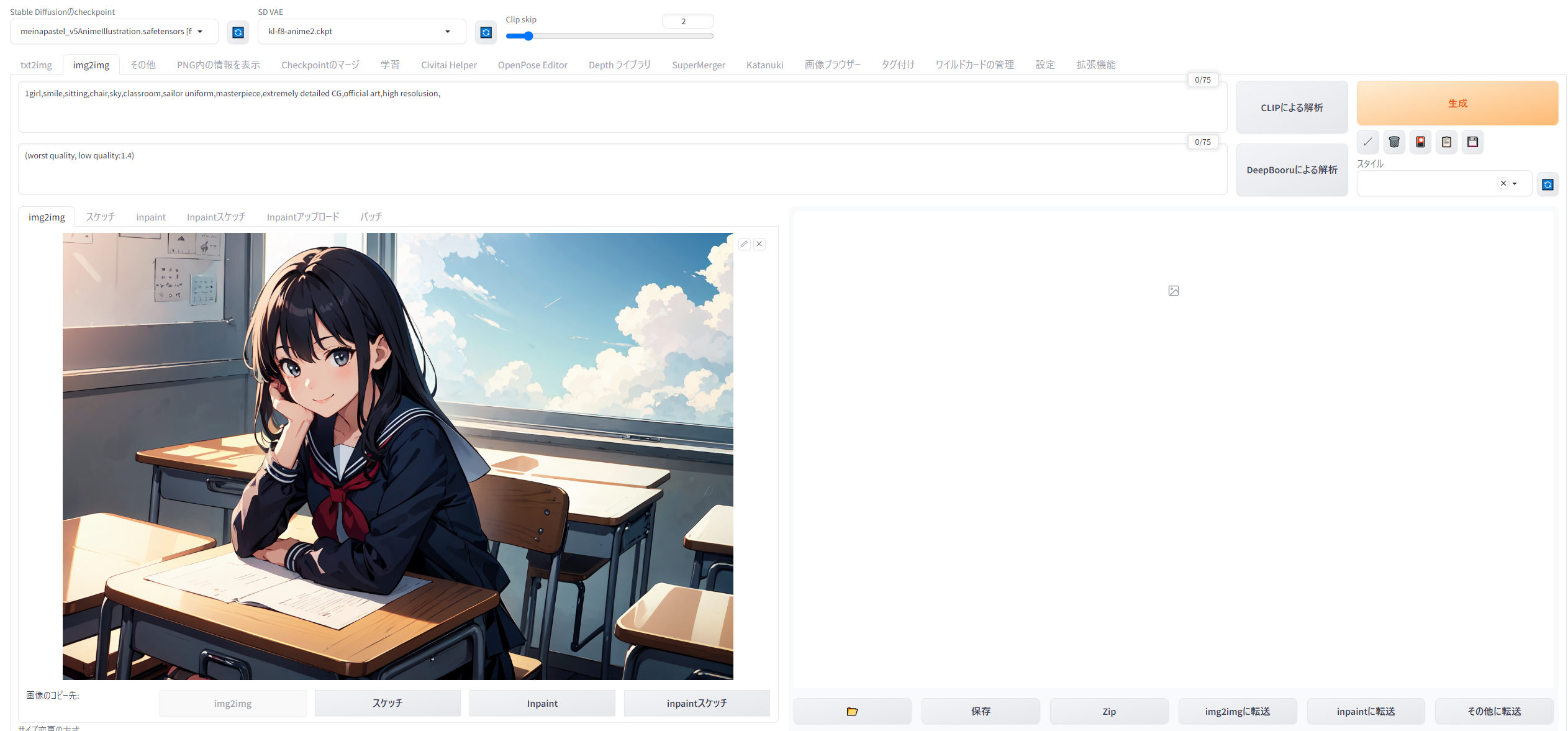{kind=link}
画面を下にスクロールすると、このような設定が。さきほどの画像は768x512を高解像度補助を掛けて2倍にしたので、そのサイズがデフォルト値として読み込まれています。
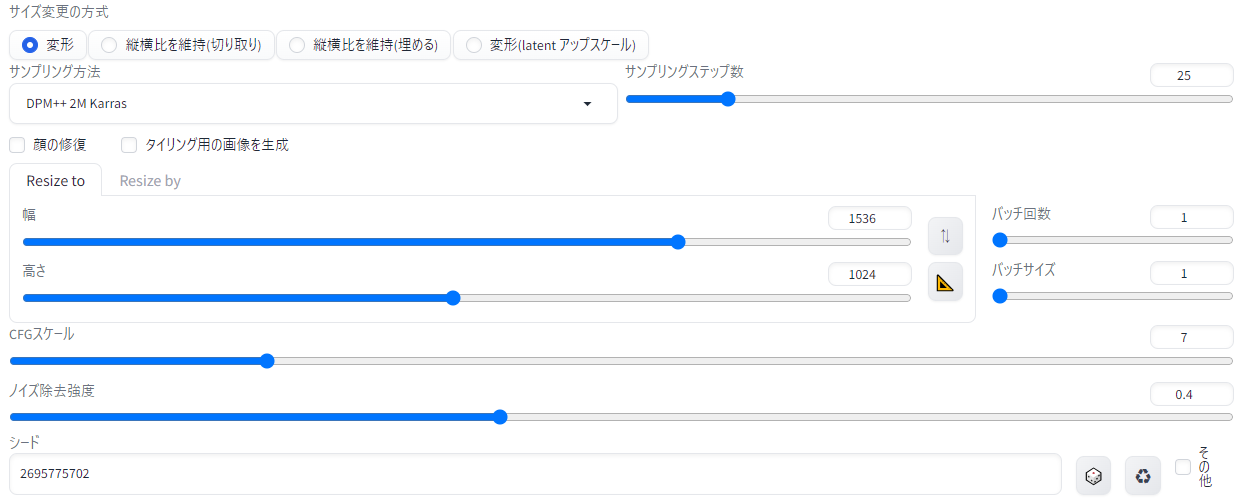{kind=link}
ステップとスケールはText2imgと同じ意味。ノイズ除去強度は「どれくらいこの元画像を参照するか」を意味しています。「0.5」までならプロンプトをもとにちょうどよく仕上げてくれ、「1」だと全く違う画像に、「0」だと全く同じ画像になります。
この設定のままで生成してみましょう。ただ、プロンプトの「smile」を「angry」に変えてみます。
{kind=link}
ほぼ同じイラストで、表情だけを変更することができました。画像がやや焼き付いたようにくどくなりましたが、これは参照元と同じサイズで生成したためです。
プロンプトを書き換えず、キャンバスサイズだけを大きくしてimg2imgすれば、単純に元画像のクォリティーアップを図ることもできます。こういう作業のことを「アップスケール」と呼びます。上の画像はアップスケールせずにimg2imgしたので、画質が変になっていますが、さらに大きい2048x1360サイズで生成すると…
{kind=link}
このようによりクォリティUPしつつ表情を変化できました。こうしたimg2imgでクォリティアップする手法を、私はimg2imgアップスケールと呼んでいます。これをやるときは「ノイズ除去強度」を0.5より下げないと、同じ構図の訳の分からない奇形画像が生じてしまうので注意しましょう。あくまで構図を維持しながらクォリティーアップしたいのなら、0.2~0.35あたりにとどめておくのがよいでしょう。
アップスケールにはこのように、img2imgを使う、高解像度補助を使う、Controlnetを使う…といったさまざまな方法があり、この手法にどれだけ熟達しているかによってAIイラストの出来は大きく変わってきます。プロンプト再現の上手なモデルAで生成し、リッチな描き込みをしてくれるモデルBでimg2imgアップスケールするのが個人的なオススメです。
クォリティ爆上げ!アップスケールを覚えよう

【重要】画像生成AIでやってはいけないこと
img2imgの話ができたので、ようやくこの話ができます。画像生成AIはさまざまな不可能を可能にする夢のようなツールですが、法律上、またはモラル上やってはいけないことがいくつもあります。必ず下記を理解した上で使用するようにしてください。
▽他人の著作物のimage2image
画像生成AIユーザーとして、最大のタブーの一つが「他人が権利を持つ画像をimage2image(通称i2i)すること」です。界隈では昨年秋頃から、他人が苦労して描いたイラストをi2iして自作品と称する悪質行為が何度も露見し、画像生成AIユーザー全体にとって大きなダメージとなっています。
i2iパクリはどんなに加工しても元絵を知っている人にはバレますし、明確な著作権侵害行為であり、訴訟に発展する恐れもあります。絶対にしないようにしましょう。i2iしていいのは、主に「自分でt2iした画像」「自分で描いた絵」「自分で撮った写真」「使用許可を取っている素材」と、それらを元に自分で加工した画像だけだと思って下さい。Google画像検索で出てきた画像をポンと放り込んでi2i・・・のようなことをしていると、いずれ大変なことになります。
AIイラストの著作権については、文化庁が開催したこちらのオンラインセミナーの動画を視聴しておくことを強くおすすめします。講義資料のPDFも公開されており、大変分かりやすい内容となっています。
ポイントは、手書きだろうがAIだろうが、「他人の著作物に相当類似していて、それが偶然でなければアウト」ということ。これを「類似性」と「依拠性」と言います。たとえある著作物に依拠していても、そもそも似ていなければ著作権侵害ではありませんが、それでも他人の著作物のi2iはトラブルを巻き起こすので、手を出さないようにしましょう。
i2iパクリをめぐるこれまでの経緯は、こちらの全体公開記事でも紹介しています。
AI悪用行為「i2iパクリ」はなぜ横行し、そして廃れたのか

こんにちは、スタジオ真榊の賢木イオ(@studiomasakaki)です。 全体公開記事なので自己紹介しますと、2022年10月のNovelAI登場当時から100本くらい画像生成AIの記事の連載を続けている変な人です(自己紹介おわり)。今回はコラムとして、悪名高い「image2imageパクリ」(i2iパクリ、img2imgパクリ)とは何か、どうして...
▽クリエイターへの敬意のない言動
画像生成AIは絵心のない人でもハイクォリティなイラストを生成できる反面、苦労してイラスト技術を研鑽してきた人々にとっては、「これまでの努力を無にするもの」と思われても仕方のない技術です。ただでさえそうした背景がある上に、先に述べたi2iパクリ事件を始め、イラストレーターや漫画家、作家などクリエイターへの敬意に欠けたAIユーザーの言動(発言&行動)が繰り返されてきました。
FANZAやPixivといったプラットフォームに連日大量に似たような作品を投稿する行為も散見され、ランキングやタグがAI生成作品ばかりになってしまう現象も。この問題は、のちにFANBOXやファンティアといった支援サイトでのAI生成コンテンツの投稿が禁止されることにつながってしまいました。(※当FANBOXのようなAI生成の技術解説コンテンツは、独自の創作性を持ったコンテンツとして利用が認められています)
激変したAIイラスト界隈、現状の整理と今後の展望

AIユーザーに対する世間の目は大変厳しいものがあり、クリエイターを軽んじるような言動は必ずトラブルを招きます。AIイラストを今後も楽しめる技術にするためにも、自己防衛するためにも、おのおのがラインを引いて行動することが大切だなと身にしみて感じています。
ただ、昨今は画像生成AIを利用した人物や、利用しているとみなした人物にSNS上で苛烈な言葉を浴びせる事案も相次いでおり、「スレイヤーズ」のイラスト担当で知られるあらいずみるい先生が「AIを使った同人誌を売った」とみなされて中傷被害に遭ったことも記憶に新しいです。誰かの権利を侵害しているならともかく、画像生成AIを使っただけで誹謗中傷や攻撃のターゲットにしてよいという法はありません。法律とモラルを守っているのであれば、必要以上に萎縮する必要はないと個人的に考えています。
▽無修正画像の投稿
画像生成AIが生成するエロ画像は、性器のほとんどが無修正です。これは、エロ画像を生成するために学習させた画像セットが無修正のものであることに由来しています。自分で楽しむぶんには良いのですが、投稿するときはかならず自分で修正するようにしてください。日本国内において、性器が露骨に描写されているものは「わいせつ物」と解釈されています。たとえ投稿先が海外サイトであっても、日本国内から投稿した場合は、刑法175条の「わいせつ物頒布等罪」が成立します。(参考:FC2事件)
エッチイラストの描写が得意なモデルだと、全年齢イラストを作るつもりのプロンプトでも、nsfwなイラストが生成されることがあります。SDwebUIの拡張機能でそうした画像が出たときはサムネイルが表示されないようにすることも可能です。
▽「本物」と見紛う画像の投稿
著作権以外にも、配慮しなくてはならない名誉権や肖像権、パブリシティー権などの問題があります。画像生成AIに習熟してくると、例えば追加学習によって特定のイラストレーターの画風をそっくり真似たり、実在する人物の「存在しない写真」を生成したり、児童ポルノと見紛うような精巧な「非実在児童」のnsfw画像を生成したりすることができるようになります。
これらは著作権上の問題をたとえクリアしたとしても、全く別の文脈で法的トラブルを招くことが考えられます。法的にはいろいろ言えるのですが、実在の人物や商標がからむ場合は「自分がされたら怒る」ことはしないようにするのが自分を守るために必要な行動だと思います。
よく聞く「LoRA」って何?
さて、「やってはいけない」ことについて語る上で触れておきたいのが「LoRA」の存在についてです。既存のキャラクターや有名絵師の画風を模倣できる技術として、初めて画像生成に触る方でも耳にしたことがあるのではないでしょうか。
{kind=link}
AIがまだ学習していない概念を後付けで学習させることを「追加学習」と言いますが、この追加学習の方法として特によく知られているのが「LoRA」や上位版とされる「LyCORIS」と呼ばれるものです。
これは数十枚程度の教師画像とテキストのペアを自分で学習させることで、特定のキャラの容姿を再現できるようにしたり、イラストのタッチやポーズなどを意図した通りに再現したりできる技術。ウェブ上では「Civitai」という海外サイトなどでこうしたモデルの公開が盛んに行われており、自分で学習させなくても、他のユーザーが作ったモデルをダウンロードして使用することが簡単にできます。
簡単な使い方やおすすめLoRAなどの基本情報はこちらから。
LoRAでキャラ再現!15分でできる追加学習入門

こちらのイラストは、「機動戦士ガンダム 水星の魔女」最終話バージョンの主人公2人の姿を再現するLoRAをスタジオ真榊で追加学習して作ったものです。RTX3060でも、1キャラあたり1~2時間程度で学習させることができました。(バージョン7くらいまで試行錯誤したので、結局完成までは数日掛かりました)
キャラ再現以外にも、LoRAやLyCORIS(学習効率などが違うだけでほぼ同じような使い方をします)を使うことでさまざまな表現が可能になります。キャラクターの目のデザインだけを変えたり、ポーズや構図を指定したり、描き込みを増やしたり、逆にフラットな塗りに変えたり、線画にしたり、画風を変えたりーと、アイデア次第でありとあらゆる絵作りができるのがLoRAの魅力です。
余談ですが、スタジオ真榊ではオリジナルのnsfw漫画の制作を目指しているので、目下登場人物のLoRAの追加学習を行っています。今後、LoRAとControlnetをフルに使った漫画作りの技術について、有用な記事をどんどん増やしていきたいと思っています。
LoRAを自分で追加学習する方法はこちらの記事にまとめてありますので、ご興味のある方はぜひ。
今日1日でLoRAが理解る!キャラクター再現超入門
一方で、さきほどの「やってはいけない」の話に戻りますと、たとえば特定の有名人の写真を追加学習させたLoRAで不名誉なニセ写真を作ったり、特定イラストレーターの過去の作品を追加学習させて本人の名前付きで頒布したりといった行為は、トラブルを呼び込むばかりか、刑事事件や民事訴訟に発展する恐れもある危険な行為です。
先程自作LoRAを使った「水星の魔女」のファンアートを紹介しましたが、AIを使った二次創作についてもさまざまな考え方があると思います。AIと著作権について言えることは「手描きイラストでやっちゃダメなことはAIイラストでも当然ダメ」ということですが、「手描きイラストでは黙認されている二次創作でも、AIを使ったらダメ」ということは成立するのか、その根拠は何か、と問われると、その回答は人によってかなり隔たりがあると思います。何がダメで何がいいかを説くような立場にはありませんが、何よりも自分の身を守るために、法律とマナーを守り、自分でラインを引いた行動を取ることをオススメします。
Controlnetでできるようになったこと
ここまで説明したことは、画像生成AIができることのほんのさわり程度です。さまざまな拡張機能やより高度なモデルの登場、それらを組み合わせた工夫によって、日々ものすごい速さで「できること」の範囲が広がっています。
その代表格が23年2月に登場したcontrolnet。この拡張機能群を使うと、例えばこんなことが可能になります。
・別の画像の「ポーズ」を継承する
{kind=link}
・同じキャラのまま「服装」や「表情」を変更する
{kind=link}
・ポーズを自由に変更する
{kind=link}
・背景だけをさしかえる
{kind=link}
・他の画像を参照して服装を差し替える
{kind=link}
・同じキャラで別イラストを作る
{kind=link}
・キャラを消す
{kind=link}
・線画化する
{kind=link}
・線画に色を塗ってもらう
{kind=link}
・手の形状を3Dモデルを参考に描いてもらう
{kind=link}
長くなるのでこのあたりにしておきますが、Controlnetが登場する23年2月まで、こうしたことは一切できませんでした。プロンプトを練りに練って「お祈り」するか、あとはimg2imgでポーズを作るしかなかったのです(これがi2iパクリが横行した理由のひとつ)。現在はここまで自由度が広がっているので、嫌がらせ目的でなければそうした迷惑行為をする必要性もなくなってきています。
スタジオ真榊では、こうしたControlnetを駆使したテクニックの研究を日夜行ってきました。きっと皆様のお役に立てると思いますので、ご興味がありましたらぜひこれまで積み重ねてきたControlnet研究の記事も読んでみてくださいね。
中級者になるために
ここまでの内容がだいたい飲み込めたら、ある程度好きなイラストを生成できるようになっていると思います。最初は好みの学習モデルを探したり、エッチな画像を作れるか試してみたり、プロンプトを勉強してみたり、スケールやステップ、サンプラーにこだわってみたり、LoRAを使ったイラストに挑戦してみたりと、触っているほどに上達していくことと思います。
次に確認していただきたいのは、記事冒頭でもご紹介したスタジオ真榊の過去記事一覧。上達していくためにまず読んでおいて頂きたいのは、次の記事です。
余計な部分を消しゴムマジック!LamaCleanerでできる「修正」と「粗密」
Controlnetが理解る!モデル15種&プリプロセッサ35種を徹底解説

手修正の最適解は?破綻を直す7つの方法「+1」

「ADetailer」が理解る!部位別詳細化と5つの「応用」

終わりに
特にControlnetとLoRAについては革新的な技術なので、できるだけ早めに覚えておくと上達が早いと思います。一番イラストのクォリティそのものが上がるのは、優れた学習モデルを入手することと、画風に合ったアップスケールの手法を身につけること。性能のよい学習モデルはツイッターやDiscordなどですぐ話題になるので、アンテナを貼っておくと良いでしょう。
{kind=link}
ここまで長い文章を読んでくださり、ありがとうございました。最後に、スタジオ真榊のツイッターアカウントを貼っておきます。最新情報はこちらでお知らせしているので、ぜひフォローしてみてくださいね。
これを読んでくださったあなたが、素晴らしいAI生成ライフを送れることを祈っています。
Special Thanks
かけうどん様、zzz AIお絵描き(drawing)様、CONV(こんぶ)@AIart様、Canpon1992X様、マチネ フク様、ツバサ天九様、きせのん様、桃色りりあ様、Myrr.様、もりそば@AI画像垢様、moriπ様(順不同)多くのAI術師さま
NovelAIしか触ったことがなく、ローカル生成をどうやって始めたらいいのかわからず右往左往していた賢木を優しく教えてくださいました。本当にありがとうございました。
Files