Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

今日1日でLoRAが理解る!キャラクター再現超入門 (Pixiv Fanbox)
Content
======================================
【2023/08/11更新】初心者向け設定の項目を更新しました。
======================================
こんばんは、スタジオ真榊です。今夜はようやく、LoRA制作の入門記事をお届けできます!
例によって水星の魔女最終話のキャラ再現LoRAに挑戦してみて、環境導入やつまづきがちなポイント、設定のやり方やクオリティアップのコツといったところがようやく分かってきました。今回は私と同じ完全素人の状態からでも、書かれているとおりにやればLoRA制作環境を整備でき、キャラクター再現LoRAや「うちの子LoRA」を作れるようになるところまで、詳しく紹介していければと思います。
{kind=link}
「自分もLoRAを作ってみたいな・・・」と思っても、解説サイトを読みに行くと「枚数×リピート×エポック=ステップ数」だとか「dimが、alphaが」といった謎の呪文が書かれていて回れ右した方も多いと思います。私もまさにその一人なので、今回の入門編では難しいことは極力抜きにして、「とにかくこの通りにすれば自分でもキャラ再現LoRAが作れたよ」というところを目指します。ただ、追加学習ができるスペックのグラフィックボードはご用意くださいね。
シチュエーションLoRAや画風再現LoRA、服装再現LoRA、構図LoRAなどありとあらゆる概念を追加学習することができますが、まずは一番「やってみたい度」が強かったキャラ再現LoRAから始めて正解だったなと思っています。失敗作のLoRAで画像生成すると、なぜ失敗したかがとてもよく理解できる(▼)ので、数値や操作の意味がよく理解できていなくてもズンズン進んでいきましょう。
{kind=link}
グラボは?所要時間は?追加学習の全体像
さて、StableDiffusionを楽しんでいる人であればほとんどの人がLoRAを使ったことがあると思いますが、いざ学習となると
「LoRAを作るにはRTX4070とか4090とかすごいグラボが必要なんでしょ?」
「苦労してもどうせ品質のよいものはできないので、Civitaiになければ諦めよう」
と思っている人がほとんどではないでしょうか。私も同じで、なかなか手を出せずにいたのですが、丸1日休みが取れたので一念発起。スタジオ真榊ではRTX3060(12GB)を利用していますが、思い立ってから環境導入まで1時間、完成まで丸1日程度(6つ目のバージョン)で、満足のいくキャラ再現LoRAを作ることができました。
{kind=link}
「学習開始」ボタンを押して一つのLoRAが完成するまでに掛かる時間は、私の場合1~2時間くらい。時間が掛かるのは教師データとなる画像の収集と加工、タグ付けに使うテキストデータの準備で、むしろこちらの方がLoRAの品質を左右する重要なパートです。これも1時間くらいあればだいたい整うんじゃないかなと思います。ただ、同じ方法で毎回うまくいくわけではないようで、どんな画像を何枚、どんなタグで学習するか等々で「やり直し」が発生します。初めてのLoRAはver.6で一応の完成を見ましたが、おおむねやり方を理解できたので、どんどん短縮していけるのではないかなと思います。
LoRA学習で「やってはいけないこと」
この記事を読んで下さる方の多くは、今回初めて画像生成AIの「利用」ではなく「学習」に踏み出す方だと思います。ご承知の通り、AIによる著作権侵害については利用段階と学習段階で分けて考えることが基本ですので、もう一度、6月に行われた文化庁のオンラインセミナー「AIと著作権」の内容を確認してみてください。
生成画像の利用においては、誰かの著作物と似ているか(類似性)、そして本当にその著作物に基づいて作り出されたか(依拠性)の二つによって、著作権侵害かどうかが決まります。この考え方は手描きイラストであろうとAIイラストであろうと変わりありません。一方、LoRA制作を含むAI学習の段階においては、その行為が「著作物に表現された思想又は感情の享受を目的としない」こと、ついでに「権利者の経済的利益を不当に害しない」ことが重要になります。これは手描きイラストにはない独特な考え方で、とりわけキャラ再現LoRAや画風再現LoRAの作成についてはどこにラインが引かれるか非常に分かりにくいのが難点です。
{kind=link}
ごくおおざっぱに言えば、「その学習行為によってある特定の著作物を直接楽しむことができてしまい、権利者が経済的に不利益を被る」場合はアウトになりうるのですが、ご承知のとおりLoRAを作った時点では、そのLoRAから教師データそのものを直接取り出して鑑賞することはできません。それを使って生成したときに教師データそのものの画像が出てしまう可能性は絶対にないとは言えませんが、LoRA生成者はキャラや画風の再現を試みたとしても「著作物そのもの(教師データそのもの)」を出したくて作っているわけではありません(絵師さんへの嫌がらせ目的なら別ですが・・・)。
とはいえ、めちゃくちゃに高品質なLoRAが生まれたら著作物と物凄く類似しているものが生成できる可能性もあり、素人目にはアウトともセーフとも言えそうに見えます。
画像生成AIと著作権に詳しいSTORIA法律事務所の柿沼弁護士はこの点について、
と記事で表現しており、プロの目から見ても「再現系LoRAはセーフと思われるが、アウトとの区別は相当困難」ということのようです。LoRAをめぐる判例や政府のガイドラインが出ていない以上、現時点で明確な答えはありませんので、もう一度「学習段階の御法度」を確認して、まずはトラブルにならないようしっかり自己防衛することが最も重要なことと思います。
「訴えられても勝てる理論武装をする」のではなく、「まず訴えられない」よう、ウェブ上での発言・行動に気を付けるのが一番の安全策です。
誰でもできる!LoRA環境導入
さて、LoRAの学習にはいくつかの方法がありますが、この記事では賢木が試して最も失敗が少なく、シンプルで、上級者になっても使えると感じた「Kohya_LoRA_GUI」(RedRayzさん作成)を使った方法についてご紹介します。
LoRAの学習にはKohya-ssさんが作成された「sd-script」というツールが必要なのですが、黒いコマンドプロンプト画面に半角英数で入力する作業がもう厳しい私のような文系人間のために、sd-scriptの仕組みを理解していなくても直感的に操作できるGUI(グラフィカルユーザーインターフェース:目で見てぱっと操作しやすいやつ)が存在します。特にこの「Kohya_LoRA_GUI」は見た目がシンプルにまとまっている点、入力欄にカーソルを合わせると分かりやすい説明文がポップアップする点、画面を閉じたときのパラメータを次回起動時に自動で再現してくれる点が非常に使いやすい!
Kohya_LoRA_GUIをインストールすると一緒にsd-scriptもインストールされるのも面倒がなくてよいですね。さっそく下記の手順で導入してみましょう。Python3.10とGitが既にインストールしてあれば、「3」から始めてOKです(所要時間10分程度)
1.Python 3.10.6をインストールする
「Python(パイソン)」はAI開発に使われるプログラミング言語。StableDiffusionを既に触っている方はほとんどがPython 3.10.6を導入済みと思いますが、入門記事ですので一応導入方法を書き記しておきます。
Python公式サイトにアクセスし、Python 3.10.6のインストーラーをダウンロードします。最新版ではなく、ちゃんとバージョン3.10.6を選びましょう(下図参照)。
{kind=link}
インストーラーを実行します。最初の画面で出てくる「Add Python 3.10 to PATH」にチェックを入れてから、「Install Now」をクリック。無事「setup was successful」と表示されたら「Close」をクリックでOKです。
2.Gitをインストールする
「git」はファイルのバージョン管理が簡単にできるツール。公式サイトのダウンロードページに行き、最新版へのリンクである「Click here to download」をクリックしましょう。
{kind=link}
・ダウンロードしてきたexeファイルを実行。(記事執筆時点2023/8/7は2.41.0が最新です)
・インストールボタンが出るまで「Next」を連打します。チェックマークは変更しなくてOK。「Install」が出たらクリックしてインストール。
・インストールに成功したら、「View Release Notes」は見なくていいのでチェックを外し、「Finish」。デスクトップなどを右クリックしてこちらのメニュー(Git Bash Here)が生成されていたらOKです。
{kind=link}
3.Kohya LoRA GUIをインストールする
Python3.10とGitが準備できていたら、Kohya LoRA GUIをインストールします。こちらのURL(▲)にアクセスし、「kohya_lora_gui-x.x.x.zip」をDLしましょう。(記事執筆時点の最新バージョンは1.8.2)
{kind=link}
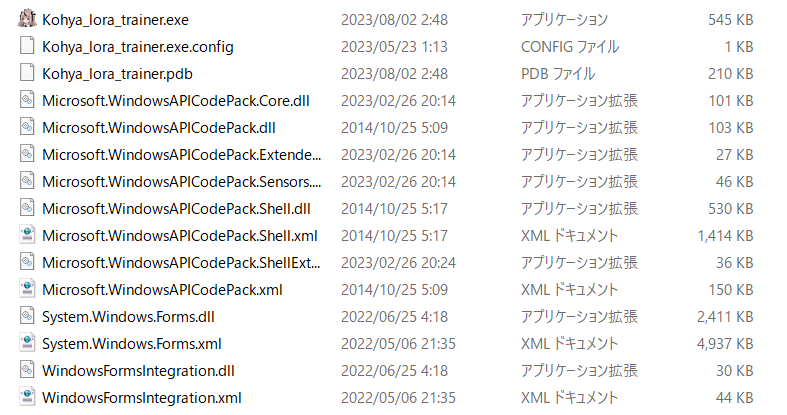
zipを解凍し、中にあるexeファイル(上のスクショだと一番上)をダブルクリックしてGUIを起動します。解凍場所はどこでも良いのですが、ストレージが圧迫されていなければ、SDwebUIのすぐ隣がいろいろな意味でおすすめです。
{kind=link}
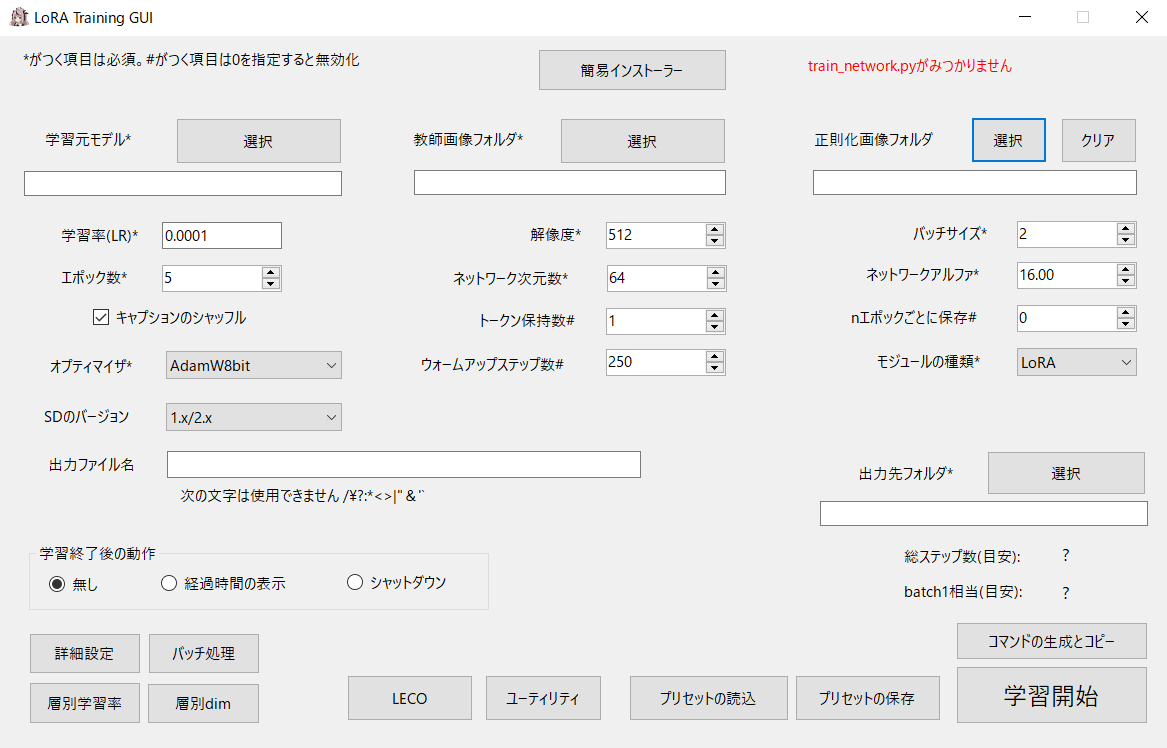
この画面が出てきたら、右上に赤字で書かれているエラーは無視して、上部にある「簡易インストーラー」をクリックしましょう。説明文を読んで、インストールボタンを押します。
{kind=link}
「フォルダはGUIが入ったフォルダと同階層を~」の意味は、例えばC:ドライブにさきほどGUIを解凍したのであれば、同じようにここでもC:ドライブに指定してね、ということです。
最後の問答をする部分がつまづきがちなのですが、This machineなどはエンターキーを押せばOKですし、「NO」と答える部分はそのまま半角英数でその2文字を打ち込んでエンターキーを押すだけです。「all」は打ち込まなくても、そのままエンターキーでOK。最後、「fp16」を選択するところだけが鬼門です!カーソルキーの「↓」を押したくなるのですが、キーボードの「1」を押さないと最初からやり直しになってしまいます。「fp16」を選択状態にすると「fp166」などと表示されることもありますが、問題ありません。何度でもやり直せますが、さほど深く考えず、fp16のところを選んでエンターキーを押しましょう。ちなみに「fp16」と打ち込んでエンターキーでも通るようです。
最後に 〇:¥〇〇¥sd-scripts> というメッセージが出たらインストールはおしまいです。黒い画面を閉じましょう。次回からは「Kohya_lora_trainer.exe」をダブルクリックすれば起動できるので、デスクトップにでもショートカットを作っておくことをおすすめします。
{kind=link}
・教師データを入れる「trainingフォルダ」を作ろう
ここで、LoRA GUIと同じ階層に教師データを入れる「training」フォルダを作っておきましょう。名前は「sozai」でも「img」でも何でもOKですが、この記事ではこれ以降「trainingフォルダ」と呼びます。「kohya_lora_gui-1.8.2」「training」「sd-scripts」の3つのフォルダがそろっていれば、環境整備は完了です。
誰LoRAを作る?必要な材料を集めよう
{kind=link}
次に、何のLoRAを作るかを決めます。今回はキャラ再現LoRAについて解説しますので、いわゆる「うちの子LoRA」など、自分が最も愛着を持てて、生成に成功したらとっても感動できるキャラクターを最初は選ぶのがオススメ!作業の負担感が段違いになります。
・枚数と品質はどうする?
教師データは20枚前後用意するといいでしょう。正面画像ばかりではなく、できるだけそのキャラをさまざまな方向から見た姿や表情、服装など、バリエーションがあると良い結果になります(ただ、遠くにぽちっと映り込んでいるレベルの画像は必要ありません)
全身画像にこだわらず、上半身のみや顔のみの画像も混ぜると、細部をよく学ぶことができます。あまり多すぎると後述する「タギング」(説明タグの準備)が面倒になるので、入門編の今回は20枚と決めて厳選してください。
教師データは多い方がいろいろな画像を出せる柔軟で高品質なLoRAになるのですが、枚数を優先して低画質な画像まで学習させてしまうと、「あ、このキャラは低画質に描いて欲しいキャラなんだね」とAIに誤解されるので、枚数よりもできるだけ高品質な画像を揃えることを優先しましょう。教師データはAIイラストでももちろんOKですし、拡張子はjpgでもpngでも構いません。
理想は「短い辺が1024ピクセル以上で、ぼけや白飛びがなく、色つきの光を浴びておらず、余計なものが写っていない、シンプルではっきりした白背景の画像」。夕焼けや夜、ネオンの光を浴びてキャラの色が変容している画像はできれば取り除いたほうがベターです。複雑なポーズや、多数の人物が写っている画像もよくないとされています。背景は「白背景にした方が良い」という説と「いや消さないほうが良い」という説と両方見かけたことがありますが、白背景にして「white background」とタグ付けするのでとりあえず問題なく感じています。
瞳や衣装の細かい部分のデザイン(ボタンやアクセサリの造形など)は学習しにくいので、生成時に溶けたりつぶれたりしてしまうことが多いです。詳細に描いてほしい部分は、アップになった画像も意識的に用意しましょう。(どこの部分のアップかタグ付け必須)
画像のサイズはすべて揃える必要はありませんが、極端に縦長や横長だとリサイズ/トリミングされてしまう恐れが生じます。できたら、フリーソフトなどで適宜正方形に近いサイズにしましょう。1辺が512ピクセルに満たない小さい画像は、SDの「Extra」タブを使って大きいサイズにスケールアップしたほうがよい結果になります。画質が悪いものはimg2imgアップスケールをしても良いでしょう。
・どこに保存する?
画像を保存する先は、先ほどの「training」フォルダの中にもう一つフォルダを作って、そこにまとめて保存します。フォルダ名は「20_〇〇」としましょう。うちの子(更木ミナちゃん)だったら、「20_zarakimina」でOK。
この数字が画像1枚あたり何回学習するかを意味しており、〇〇に入る単語がLoRAを作るときのトリガーワードになります。C:ドライブであれば「C: \training\40_zarakimina」という場所に保存しておけばOK。
画像のファイル名は全角や日本語混じりを避け、半角英数で統一しましょう。01.png、02.jpg...といったように必ずしも連番になっている必要はありませんが、画像がそろったらリネームソフトなどを使ってそのようなファイル名にしておくと管理しやすいです。
【コラム】服装にバリエーションがある場合は?
1人のキャラでも、複数の髪型/服装バリエーションがあることってありますよね。髪を結ったり下ろしたり、ウマ娘で言えば勝負服だったりトレセン学園の制服だったり体操着だったり。その場合、教師データにそれらのバリエーションが混在していて構わないのでしょうか?
答えは「構いませんが、タギングをしっかりしましょう」です。例えば、先日作ったミオリネさんLoRAは特徴のある黒スーツ姿を含めて「lastmiorine」というタグの概念として学習させているのですが、「lastmiorine,bunny girl,bunny ears」などのプロンプトで生成すれば、一応はバニー姿を作ることができます。ただ、別の服装に着せ替えたくても襟の細部などがミオリネ衣装(この場合はスーツ)に似てしまうこともあるので、キャラLoRAに服装まで覚えさせるかどうかはLoRAの用途によって判断が分かれます。
{kind=link}
タギングをしっかりすれば、「これはlastmiorineがロングヘアでアスティカシア制服を着ているところだよ、ロングヘアとアスティカシア制服は覚えないでね」と教えることもできますので、複数の容姿のバリエーション画像から学ばせることも問題ありません。ちなみに、複数のバリエーションをきちんと分けて学習し、「shobufuku」プロンプトで勝負服姿に、「taisougi」で体操着姿になるよう設定することもできますが、その解説は別の機会に譲ります。
画像を加工しよう(省略可)
さて、無事20枚程度の教師データは集まったでしょうか。全て見渡してみて、色味が違ったり、背景が偏っていたりしませんか?例えば、夜のシーンでは髪も肌も目の色も、本来の色よりずっと青みがかりますよね。
ここは大変重要なところです。たとえば、最終話ミオリネさんは夕日の中で麦畑にたたずんでいるシーンが多いのですが、これを工夫なく学習させると「ほう、lastmiorineっていうのは、髪の毛がオレンジ色で、麦畑とセットで描かれるべきキャラなんだね」とAIに誤解されてしまい、何を生成しても背景に麦畑が生じ、髪もオレンジ色に寄ってしまうはずです。隣にスレッタさんが仲良く座っていたら、間違ってスレッタさんっぽい女の子を生成してしまうかもしれません。
そこで、余計な背景はSDの拡張機能で白抜きにしたり、ClipstudioやPhotoshopを使って余計な部分を排除したり、変容している色味を元に戻したりすることがLoRAの品質向上には重要になります。この作業はけっこう手間が掛かるので、初めてのLoRA生成ではそこまでしなくて構いませんし、そもそも直す必要がない画像を選んだほうがずっと早いです。まずはこの過程をすっ飛ばして作ってみて、どんなものが生成されるか確かめてみると、「どう加工すれば直せるか」も肌感覚で分かるようになります。
{kind=link}
背景は透過や黒にするより、白抜きにして「white background」のタグを付けるのが良いとされています。sd_katanuki(▲)という拡張機能にフォルダごと読み込ませれば一括で白背景にできるのでおすすめです。使い方は、左上をwhiteにしてdirectoryタブからフォルダを指定するだけ。精度は上の画像の通り完璧ではないので、出力先を絶対同じフォルダにしないこと!(一括で全部上書きされてしまいます)
ついでに言えば、吹き出しや文字もささっと取り除いておきましょう。ジェネレーティブ塗りつぶしやLamaCleanerで一発です。
タグ付け(タギング)って何?
{kind=link}
さて、画像生成AIのデータセットは「セット」というくらいですから、画像だけではなくそれに対応した説明文(テキストデータ)が必要です。いまあなたのtrainingフォルダ内に「uchinoko01.jpg」「uchinoko02.png」...と20枚の画像が並んでいるとしたら、上の画像のように「uchinoko01.txt」「uchinoko02.txt」...と20個のテキストファイルも並んでいないと学習することができません。
{kind=link}
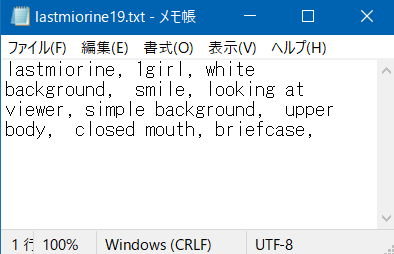
テキストファイルの中身はこんな感じで、最初にトリガーワードが書かれ、その概念(この場合は再現したいキャラ)が何をしている画像かがそののちに続きます。さきほども書きましたが、ここが非常に重要なポイント。「lastmiorine」だけなら、画面内にある全てをAIは学んでしまいますので、この画像が「lastmiorine」がどこで、誰と、どんな格好で、何をしている、どんな画風で描かれたイラストなのかをタグで指定してあげる必要があります。逆に言えば、ここで「指定しなかった」部分が全て「lastmiorine」の概念としてLoRAに刻まれるわけです。
例えば「white hair」と書かなければ白い髪に、「white shirt,black suit,formal,white collared shirt」と書かなければ黒いスーツ姿に描いてくれるようになります。逆に、これらを入れた場合、髪色や服装をプロンプトによって操作しやすくなります。つまり、タギングによって学習対象の取捨選択を行うわけです。例えば上のテキストから「looking at viewer」を除くと、こちらを見ているのがlastmiorineだと学習されてしまい、視線操作が難しくなります。
{kind=link}
Taggerをインストールして楽しよう
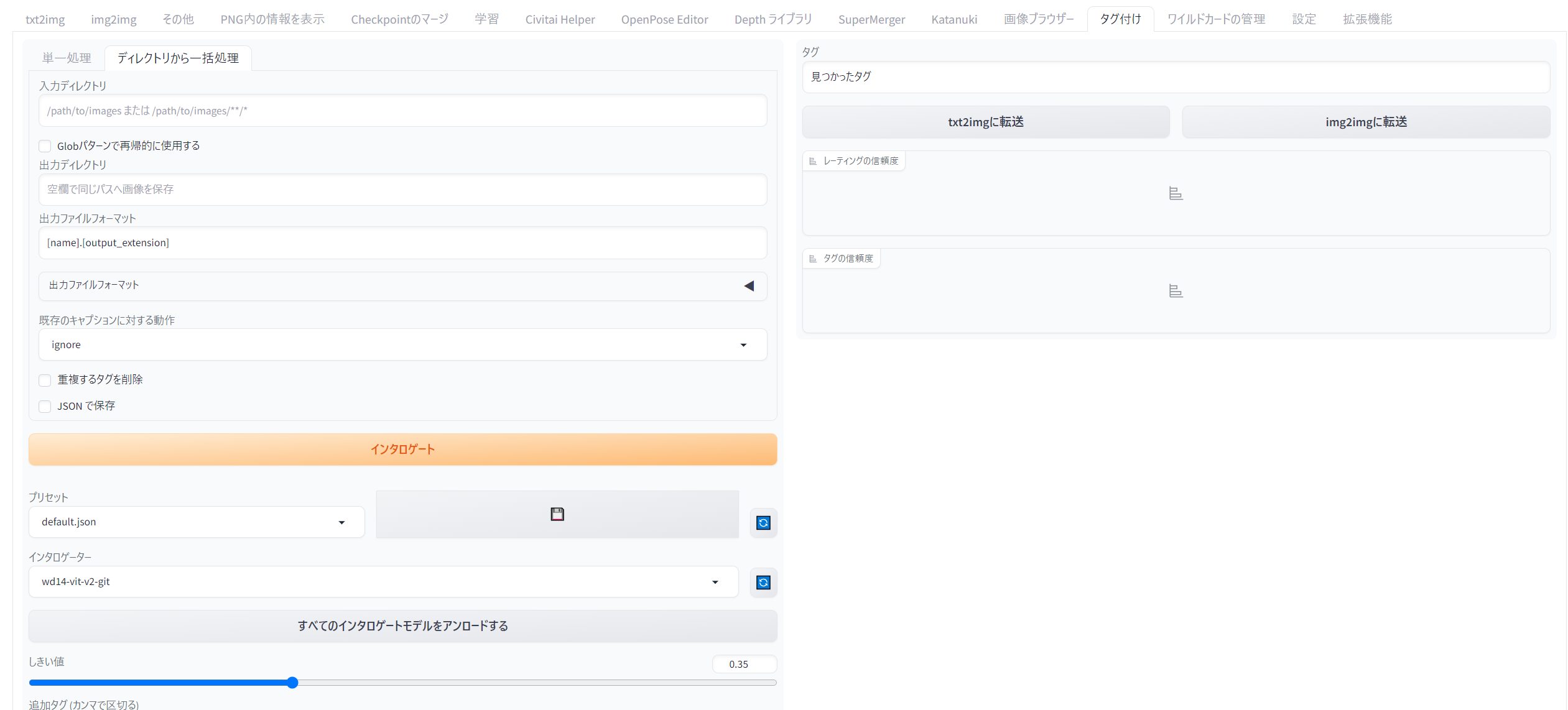
さて、手打ちで20個ものテキストデータをいちいち整えるのは大変なので、ここもAIの力を借りるとしましょう。SDwebUIの拡張機能「wd14-tagger」をインストールして、自動判別でタグを抽出してもらいます。
・インストール方法
StableDiffusion webuiのExtensionタブの一覧から「stable-diffusion-webui-wd14-tagger」を探してインストールするか、下記のURLを「Install from URL」タブで貼り付けてインストールするか、どちらでもOKです。
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
UIを再読込すると、txt2txtなどのタブに並んで「Tagger(タグ付け)」のタブが追加されています。
{kind=link}
使い方は簡単で、「ディレクトリから一括処理」タブをクリックし、「入力ディレクトリ」(タギングしたい画像データの場所)の入力欄に約20枚の画像を入れたフォルダをフルパスで指定するだけです。フォルダのアドレス部分を右クリックして「アドレスをテキストとしてコピー」して貼り付けでOK。ここで指定するのは「training」フォルダではなく、その直下の画像を入れたフォルダの方ですので、間違えないようにしましょう。
・「出力ディレクトリ」は空欄にしておきます。こうすると画像データと同じ場所にテキストが出力されます。
・「しきい値」を下げると「間違っちゃうかもしれないけどたくさんタグ付けするね」、上げると「間違いないタグだけを付けるね」の意味になります。抽出結果を見て調整しましょう。基本的にタグは多いほうがよいので、全く関係ないタグが出ない程度に下げておくのをおすすめします。
・「インタロゲーター」は何のモデルを使ってタギングするか。各モデルは初回実行時にダウンロードされ、モデルによってタグ付け結果が微妙に変わります。デフォルトで構いません。
・「追加タグ」の入力欄に入れたタグは、全てのテキストに書き加えられます。ここにはLoRAのトリガーワードにしたい単語を入れておきましょう。できれば他の意味がない、短めでオリジナルなワードがいいでしょう。私はlastmiorineとかlastsulettaを使いましたが、長すぎると思っています。
・「除外タグ」の入力欄には、どうせ消すタグを入れます。例えばミオリネさんを作るなら、「white hair」や「grey eyes」はあとで消すことになるので、入れておきましょう。ただ、なぜか「blue eyes」のようにタグ内を半角スペースで区切ると除外されません。除外タグは「blue_eyes」と半角アンダーバーで区切りましょう。
・「アンダースコアの代わりにスペースを使用する」のチェックは外しておきましょう。こうすれば半角アンダーバー区切りで抽出されるので、いらないタグを除外タグ欄に放り込みやすくなります。
・「アルファベット順にソート」:出力されるタグがアルファベット順に表記される。冒頭に呼び出し語(トリガーワード)を置きたいので、チェックは入れないようにしています(そうすれば追加タグが冒頭に来る)
これらを記入して、「インタロゲート」ボタンを押してしばらく待つと、画像データを入れたフォルダに20個のテキストデータが順次生成されます。
学ばせたい要素のタグを削除しよう
テキストデータを開いて中身を確認しましょう。今度はここから「学習したい要素を削除」していきます。
ここがつまづきポイントですので再度確認しますが、髪の白いキャラを再現する場合は「white_hair」を残すのではなく削除します。つまり、各テキストデータには、「そのキャラとセットで学んでほしくない概念」が並ぶのが正解です。例えば、教師データが全部笑顔の画像だったとしたら、「smile」を入れておかないと、笑顔の画像ばかりが出力されるLoRAになってしまいます。
これも20個のテキストデータを全て書き直すのは大変なので、不要なタグを発見したらTaggerの「除外タグ」のところに放り込んでいくのが楽です。「,」で区切ればいくつでも追加できますので、あらかた放り込めたら再度「インタロゲート」すればOK。品質向上のためには全部のテキストデータをひとつひとつ開いて目視でチェックし、意図した形になっているかを確かめますが、初めての場合この工程は面倒なら飛ばしてもOK。とにかくまずはLoRAを1回作ってみるのが大事です。
学習開始!初心者向け入力値はコレ
ここまでできたら、もうあとは学習を始めるだけです。今回の記事では、Kohyas LoRA GUIの設定について「何も考えずこう設定してください」とだけお伝えします。後で詳しい意味などをお伝えするので、まずはこの設定でやってみてください。
1.Kohyas LoRA GUIをexeファイルをダブルクリックして起動。
2.このメニューが出るので、下記のように入力する。
{kind=link}
・学習元モデル:SDwebUIのいつも使っている学習モデル(safetensorsかckpt)を指定してもよいのですが、LoRA学習と相性の良いとされる「AnyLoRA」シリーズがCivitaiで公開されているので、特にこだわりがなければこちらをオススメします。アニメ調ならこちらのAAM(AnyLoRA Anime Mix)がよいでしょう。
・教師画像フォルダ:「training」フォルダのことです。その下の、20枚の画像とテキストが格納されているフォルダではありません。trainingフォルダ内に保存されているデータ全てが学習対象になるので、もしtrainingフォルダ内に別のキャラの教師画像データを準備していた場合は別の場所に移しましょう。
・正則化画像フォルダ:別の機会に説明しますが、今回は使いません。空欄のままでOKです。要するにLoRAを使って「1girl」で生成したら全部ミオリネさんになるのを防ぐための機能だと思って下さい(別に防がなくてよいので今回は使いません)
・学習率(Lr):今回は「0.0001」と入力します。追加学習を一気にやると他の絵が描けなくなるため、わずかずつ進めていく必要があるのですが、この数値はその「どれだけわずかずつか」を示す数値です。後述するオプティマイザーによって最適な数値は変化し、最も重要な数値なのですが、今回はAdamW8bitを使うのでデフォルト値の0.0001を選びます。Adafactorを使う場合は0.001が推奨されており、この数値をどうするかによってLoRAの品質が変化します。
・解像度:教師データをどれくらいのサイズで学ぶか。基本は512にするのが無難。RTX3060以上のスペックのグラボなら「768」「1024」などを選ぶのもよいでしょう。ただ、VRAM使用率が跳ね上がります。
・エポック数:今日は「20」と入力します。こうすると、20回同じ学習作業が繰り返され、計20個の学習度の違うLoRAができます(途中経過のLoRAをいちいち作らないことも可能)
・バッチサイズ:RTX3060なら「2」。3060未満なら「1」。これは学習作業をいくつ同時並行するかを示す数値で、2なら2倍の早さでLoRAが完成しますが、GPUの負荷も大きくなります。高いスペックのグラボがあるなら3より多くても構いませんが、高倍率だと学習率が落ちるので、時短しすぎは禁物なようです。
・nエポックごとに保存:「1」にすると、10エポックなら10個のLoRAが順番にできていきます。lastmiorine00001,lastmiorine00002....といった具合にできて、最後に「lastmiorine.safetensors」ができます。初めての生成は「1」ずつにしてみて、各バージョンの生成結果がどう変わるか確かめてみるとよいでしょう。「0」だと、完成するまで途中経過のLoRAは生成されません。
・ネットワーク次元数:いわゆるdim。今日は「64」と入力します。LoRAの出来に関わる重要な数値。この数値が多いほど学習情報をたくさん保持でき、教師データの再現度が上がりますが、余計な情報まで学習してしまう恐れが強まるようです。デフォルトは8で、16、32、64、128を選んでいるLoRAをよく見かけます。
・ネットワークアルファ:いわゆるalpha。今日は「32」と入力します。「ネットワーク次元数」と深く関わる数値で、1だと「ニューラルネットのウェイト値を最大にする」という意味(分からん)。ここでは、ネットワークアルファの数値がネットワーク次元数の数値を超えてはいけないとだけ覚えておきましょう。
※civitaiを見ているとalphaをdimの半分に設定する人が多いようです。同じ値だと効果がオフになるそうで、たまにdimとalphaを64/64とか128/128にしている人も見かけます。
・オプティマイザ:今回は「AdamW8bit」を選びます。これはLoRAのデータを処理するアルゴリズムのことで、手動型と自動型があります。
・「AdamW」最もスタンダードな手動型
・「AdamW8bit」AdamWのVRAM使用量を抑えつつ同等の精度を再現したもの
・「Adafactor」学習の進み具合に応じて学習率を自動で調整してくれる便利屋さん
この程度に理解しておけば今は十分です。自動オプティマイザーの方が一般に高品質なLoRAができますが、時間が掛かります。これも好みがあるので、慣れたらAdafactorも使ってみてください(学習率を変えるのを忘れないこと)
・ウォームアップステップ数:「Adafactor」を選んだ場合は「0」にしないとエラーを吐きます。
・出力ファイル名:LoRA名になります。好きな名前を付けましょう。どうせたくさん作るので、「lastmiorine_ver1」とかが良いでしょう。ちなみに、新しいLoRAを作るときにここのファイル名を変え忘れても「このままだと上書きされちゃうけど本当にいい?」というメッセージが出てくれます。
・出力先フォルダ:わざわざ作ってもいいのですが、私は完成したら直で画像生成したいので、SDのLoRAを入れるフォルダにしています。
・SDのバージョン:デフォルトでOK。SDXL用LoRAを作る場合は変更しましょう。
・モジュールの種類:デフォルトの「LoRA」で構いませんが、ここを操作すると「LyCORIS」などを作ることもできます。
・総ステップ数:学習が何ステップ行われるかを示しています。SDのステップと似ていて、ステップを重ねるごとに学習度も上がっていきますが、どこかで頭打ちになり、やりすぎると過学習が起きて生成画像が低劣化(ガビガビ)になります。設定したエポック数や、教師画像の枚数、画像が格納されたフォルダ名の数字部分(1画像当たりのリピート回数)、バッチサイズが影響して最終的なステップ数が決まりますが、ここの部分がざっくり5000~10000になるように設定するとうまくいくようです。(やりすぎると過学習になり、プロンプトが効かなくなったり画質が低劣化したりします)
例:上のスクショでは、18枚の画像を1回あたり20回リピートする設定で、計20エポック回します。18×20×20=7200なので、計7200ステップですが、バッチサイズ2なので3600ステップ分で学習が終了します。(RTX3060で40分くらい)
入力できたら「学習開始」を押しましょう。黒いコマンドプロンプト画面が立ち上がり、上記の設定通りに学習が始まります。しばらく待つとこのように、インジケータが左から右に徐々に満ちていく様子が表示され、学習終了までの見込み時間も表示されます。
{kind=link}
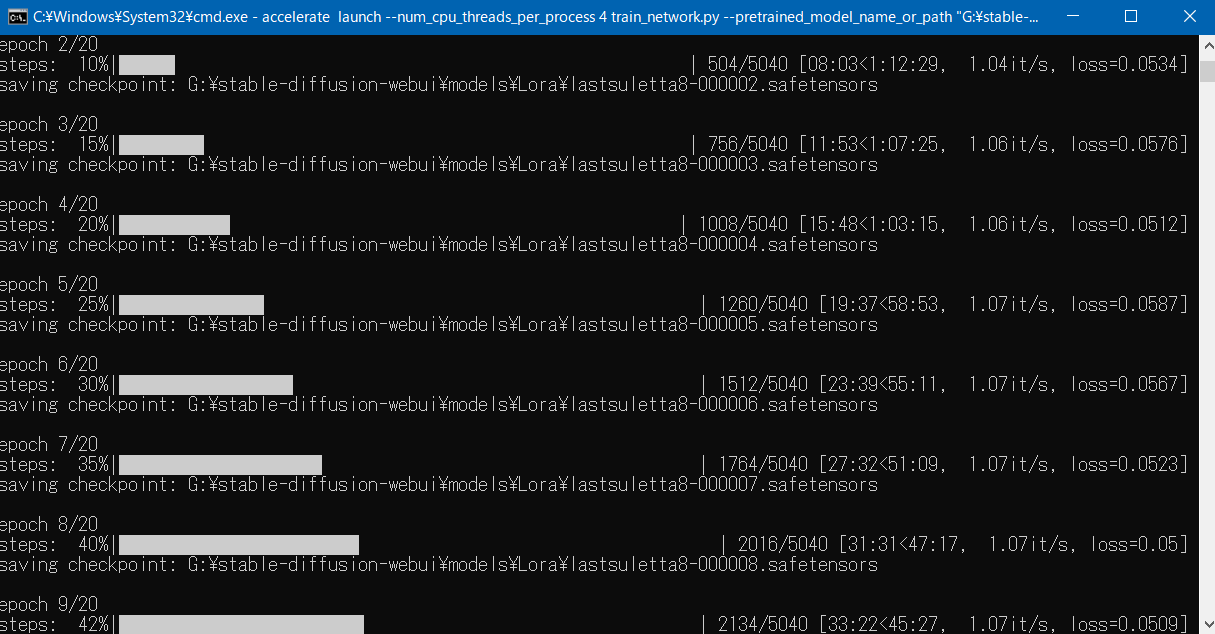
学習はこんな感じで進んでいきます。これは、5040ステップ(10080ステップの半分)を学ぶ20エポックのうち、9エポックが済んだところのスクリーンショット。右下を見ると、残り45分27秒くらいで学習が終了することがわかります。「Triton」に関するエラーが見えますが、気にしなくてOK。
恐らくかなりVRAMを使用していると思われるので、この間はローカルでの画像生成はやめておきましょう。CUDA OUT OF MEMORYエラーが起こってしまうと学習がやり直しになってしまいます。
過学習と学習不足の関係
皆さんはLoRAを利用したとき、画像が「ガビガビ」になってしまったことがよくあると思います。線が震えて定まらなかったり、目などの詳細部分が溶けてしまったり、背景に謎の光やリボンが生じたりします。これは「学習しすぎ」によって起こるものですが、LoRA制作ではこの「過学習」になる手前のギリギリを狙うのがポイントになります。
過学習の反対は「学習不足」で、エポック数や繰り返し数が足りなかったり、学習度(lr)の値が適切でなかったりすると、上手に「概念」を学べず、再現度の低いLoRAになってしまいます。LoRAは適用時に重みを操作できるので、過学習を起こすくらいしっかり学習させて、ガビガビにならない程度に重みを0.6~0.9程度に調整して使えるLoRAを目指すのがよいと思います。
{kind=link}
こちらは、上の四つが最終型のLoRAで、下の四つがその一つ前のバージョンで生成した画像です。最上段の2つの画像はいずれも「ガビガビ」が出てしまっていますが、重みを「0.8」にした二段目の2枚は、それより下の4枚よりも高品質に見えます。つまり、下の4枚は上の4枚に比べて学習不足だということが分かります。こうした「ちょうどいい学習度合い」を目指すために、さきほどのさまざまな数値やオプティマイザーの選び方が影響してくるわけですが、そもそも教師データの画像やタギングがしっかりしていないと、どんなに工夫しても高品質なものはできません。
また、逆に言えば上4枚は教師データの画風まで学べてしまっているわけなので、それを排除したい(あくまでキャラデザのみを写し取って別の画風にしたい)場合は、また異なる設定でLoRAを作っていく必要があります。例えば、それこそ画像生成によって「キャラデザだけミオリネさんだが別のタッチで生成された絵」をたくさん教師画像として作るなどの解決方法が考えられるでしょう。
・何がダメだった?失敗から学ぼう
さっそく初めてのLoRAができたら、あなた専用のトリガーワードで「うちの子」を十数枚ほど生成してみてください。教師データの画像を加工せず、タギングもさほど熱心にやっていなかったため、恐らく意図しないあれこれが生じていると思います。
意図しない背景ばかりが出ているなら、sd-katanukiなどの機能やジェネレーティブ塗りつぶしで背景を消してしまいましょう。表情やポーズ、構図が偏っているなら、タギングで排除するか、学習画像を増やしてバリエーションを出す必要があります。例えば、座っている画像には「sitting」、横からの画像には「from side」、上半身のイラストには「upper body」を入れないと、それぞれの構図のイラストばかりが出てしまうので注意しましょう。必要なタグが抜け落ちているなら、Taggerのしきい値を下げましょう。教師データに映り込んでいる他のキャラが影響していると感じるなら、ジェネレーティブ塗りつぶしやLamaCleanerで消せばOKです。
オレンジがかったり、青みがかったイラストばかりが出る場合は、教師データの色味が異なっていたため、キャラクターの正しい色味を覚えられていません。クリップスタジオなら「色調調整→カラーバランス」フォトショップなら「画質調整→レンズフィルター」を使って、逆方向の色味のフィルターを掛けてみましょう。ポイントは、本来なら白いところ(シャツや白目)が何色に変化しているかを確認すること。青く変化していたら暖色系のフィルターを、逆なら寒色系のフィルターを掛けるとよいでしょう。あまりに明るすぎたり、暗すぎたりする画像も教師データには向きません。
さきほどの画像のようにガビガビしていたり、絵が崩壊していたり、逆にキャラクターを上手に再現できていなかったりしたら、過学習か学習不足です。過学習なら、LoRAの重みを0.6~0.8程度に弱くしてみると、きれいに表示されるかもしれませんが、弱めるとキャラクターの印象も弱まってしまい、良いバランスにならなければ失敗です。「20エポック」の設定で、1エポックずつLoRAを生成する設定にしていたなら、計20個のLoRAが出力されたはずです。X/Yプロットを使って、同じSeed値でいくつかを比較してみると、過学習/学習不足でどのように絵柄が変化するのか理解できると思います。過学習ぎりぎりを目指すには、教師画像の質や枚数に対し、ステップ数や学習率、オプティマイザやdim/alphaをどう設定するかがキモになるのですが、正解はありません。まずはよい教師画像とタグを設定することが最優先で、それから設定を練っていく形になります。
良質LoRAに学ぼう
既にみなさんのほとんどはPCの中にお気に入りのLoRAを溜め込んでいると思いますが、🎴ボタンでLoRAのカード一覧を開き、右上の「i」ボタンをクリックすると、学習情報を閲覧することができます。
ss_optimizer(オプティマイザー)
ss_network_dim(ネットワーク次元数)
ss_network_alpha(ネットワークアルファ)
ss_learning_rate(学習率)
ss_num_train_images(教師画像の総学習枚数)
リピート数(フォルダ名の頭の数字)
ss_num_epochs(エポック数)
ss_max_train_steps(総ステップ数)
...などの設定を見て、良質なキャラ再現LoRAがどんな枚数・設定で学習しているかを勉強させていただくのがよいと思います。パッと見た感じ、やはり優れたキャラ再現LoRAは枚数が多い!dimとalphaは本当にまちまちですね。
一貫性のある「うちの子」をつくる
応用編として、消すのではなく「足す」こともできます。いまいち「記号」が少なくてキャラクターに統一感がないと感じる場合は、強烈に「同じ子」とわかるような記号を後付けしてしまいましょう。例えば、特徴的なリボンやヘアピン、ほくろ、傷、瞳孔の形などを描き加えたり、他のLoRAと併用して新たな20枚を生成してみるのもよいかもしれません。頭や胸の大きさ、腰や足の細さを調整したりすることで、プロンプト指示だけでは不可能だったはっきりした一貫性を出すことができるはずです。
この点については漫画化するために必須のスキルでしたので、もしこのあたりがいつでも簡便にできるようになると、究極は女性キャラと竿役を毎回LoRAで作ってしまい、大量生成することでH漫画を仕上げてしまうことが可能になります。これまでスタジオ真榊で研究してきた「差分」のテクニックを使えば、顔だけそのキャラにすることも多いに可能なはず。胸が高鳴りますね!
終わりに
ようやく課題の終わりが見えてきた思いで、大変嬉しくもあり、新たな沼に入っただけで一歩も進んでいないような気もし・・・という感じではありますが、これまで時間や余裕がなくなかなか踏み切れなかった部分に踏み込めたのは素晴らしいことでした。1月にいったん「寝取られ妻のビフォーアフター」の制作をストップしてから、なんと半年以上掛かってしまいましたが、これによってヒロイン+男性キャラ二人の容姿LoRAを作る解決策が見え始めてきました。
現在はFANZAでも比較的審査時間が掛からずに販売にたどり着けるということですので、研究成果をしっかり活かしていろいろ作っていけたらと思っています。LoRAについてはキャラ再現以外にもシチュエーション・体位・画風・構図・部位操作などさまざまな分野のものがあり、それぞれ実際に作ってみないと解説もままならないので、こちらもきっちり研究して自分のものにしたいですね。画像を使わない追加学習の新技術「LECO」についても、おいおいやってきたいと思います。
今回は入門編として初心者賢木が覚えた技術の基礎を振り返りましたが、次回は具体的な「うちの子」生成フローを画像の用意、タギング、画像加工、学習まで通して実演してみようと思っています。駆け足でわかりにくい部分や、私が勘違いしてしまっている部分などありましたら、コメントでこっそり教えていただけましたら加筆修正いたします(汗)
それでは、引き続きどうぞよろしくお願いします。スタジオ真榊でした。
<初めてのLoRAが嬉しくて作ったおまけ画像>
{kind=link}
{kind=link}
Files