Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

【Controlnet1.1】新モデルをフルに使って試す「写真とイラストの融合」 (Pixiv Fanbox)
Content
こんにちは、スタジオ真榊です。皆さんGWの真っ只中でしょうか?賢木は休みでも休みじゃなくてもSDwebUIをめっちゃ楽しんでおります!
さて今日はControlnet1.1の全体検証とまとめ記事が一段落ついたのを受けまして、以前のこちらのツイートのように「CN1.1の最新モデルを組み合わせたらどんなことができるのか?」を検証してみたいと思います。
写真とイラストの融合はできるのか?
controlnet1.1をフルに使うと言っても、色々な組み合わせ方があるわけですが、まず最初に思いついたのが自分で撮影した写真をイラスト化できるのか?ということ。賢木は(もちろんド素人ですが)スマホで写真を撮るのが大好き。「いろいろな場所で撮影した風景写真をイラストに取り込むことができたら、作品の幅が非常に広がるのでは」と常々思っていました。
これを思いついたのは、こちらの「wama@iphoneで3Dスキャンする人」さんのツイートを拝見したとき。
写真を繋ぎ合わせて一つの3Dデータにしてしまい、スマホの中に保持していつでもどんな画角でも呼び出すことができる…いまはこんなことが簡単にできてしまうのですね。
例えば、あるホテルの室内をiphoneで3Dスキャニングしておけば、あとで室内のいろんな背景を自由に画角を動かして再現できるわけです。それを漫画作品の背景にもし使えたとしたら、なんと画像生成AIの弱点だった「背景の同一性」を難なく担保できてしまうのですよ。例えば、エロゲなんかでは室内の背景素材があったとしたら、せいぜい「昼」とか「夜」とか「ズームアップ」といった差分を作るくらいで、その前でキャラの立ち絵をカチャカチャ動かして場面を表現していたわけですが、もし実在の室内データを3Dで保持できたら、ベッド上でもソファに座っているところでも入室時のコマでも、なんでも簡単に背景素材画像にすることができます。3Dにするときにもちろん画質は落ちますが、基本的な主線や凹凸さえ保持できていればControlnetでイラスト化できるわけですし、撮影OKな場所であれば権利問題もクリアできますね。
とまあ、夢は広がるばかりなのですが、そもそも今回の主題である「風景写真とイラストとの融合」ができなくては取らぬ狸の皮算用。できるのか?できないのか?まずは検証をやってみましょう。
というわけで撮影に行ってきた
はい、というわけで今回は東京は銀座の歌舞伎座に行ってまいりました。個人情報の関係でぼかしを入れていますが、自分で公道上で撮影した資料写真ですので、著作権法上問題はない写真と思います。
{kind=link}
こちらをi2iするのではなく、Controlnetを使うことによって、イラストの素材として使ってみようと思います。
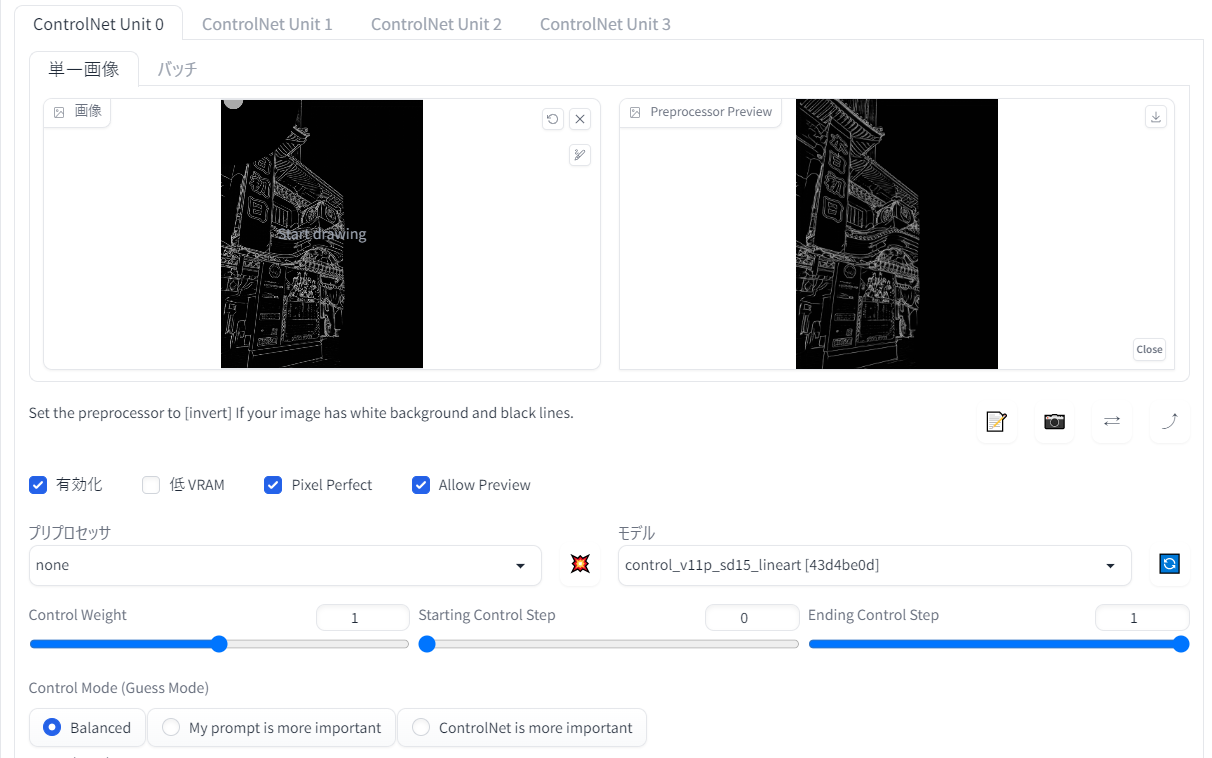
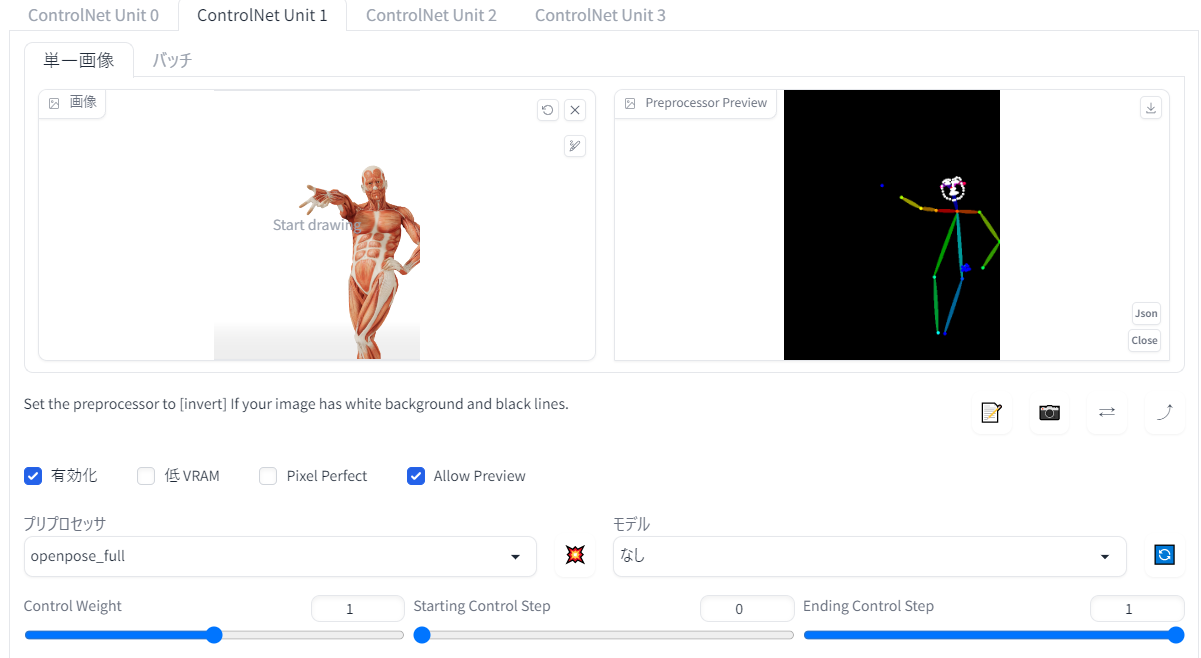
まずは、この主線を保ちながら女の子のイラストを合成することを試してみました。ごくスタンダードな方法として、資料写真を「Lineart」で読み取り、「Openpose full」で右下にこちらを向いた人物を指定します。さて、Lineartにもいろいろなプリプロセッサがあるのですが、一番向いていそうなのは「Lineart realistic」ですよね。とりあえず
realistic以外も全部試してみました。
{kind=link}
左から「Coarse」「Anime」「Realistic」です。一見して分かるほど、それぞれの特徴がよく出ていますね。やはり右の「Realistic」が良いので、こちらを採用することにします。ちなみに、クリスタで白黒反転するとこんな感じで抽出されていることがわかります。
{kind=link}
この右下に人物を配置したいのですが、こちらをそのまま使うと、人物とこの線画がぶつかりあって崩壊してしまうので、邪魔になりそうな部分を黒で塗りつぶします。
{kind=link}
これをプリプロセッサ「none」で読み込ませて、右下には「ポーズマニアックス」さんから素材をいただいてポージングしたキャラクターを配置。
{kind=link}
{kind=link}
プロンプトはとりあえず「1girl, smile, standing,white sailor uniform with purple ribbon, purple pleated skirt, black shiny hair, wearing red glasses, side ponytail with purple ribbon, (japanese building:1.2), blue sky,open mouth, 18 years old, sideburns, purple eyes, masterpiece, extremely detailed CG, official art, high resolusion, looking at viewer, wind」としました。
生成結果がこちら。
{kind=link}
うーん、思ったほどうまくいきませんでした。
失敗の理由は明らかで、もともとの背景から線画化できていなかった部分にAIが何を描けばいいか迷ってしまっていることや、「japanese」というプロンプトに引っ張られて女の子の服が一部着物風?になってしまったことなどが見て取れます。何よりも、実在の風景写真を取り込む場合は、主線だけを維持しても、その場所を知っている人間からするとまったくの別物に見えてしまう。これが最大の問題です。
背景と人物を分けて生成しよう
ということで、背景と人物をいっぺんに出すと互いに干渉して低画質になってしまうことがわかったので、それぞれを別々に生成してみることにしました。今回はi2iではなくControlnetを使うことにこだわりたいので、Lineart realisticとDepth zoeを使ってt2iしました。Depthを併用したのは、さきほどの失敗から学んで構造物の奥行きを取り入れたかったためです。
プロンプト:architecture, bridge, building, city, day, east_asian_architecture, outdoors, real_world_location, scenery, sky, tokyo
{kind=link}
depthを採用したことで、特に画面の左下の処理がうまく行っていることがわかります。seed値によってさまざまな結果が出るので、小さいサイズでいくつか作例を試してみました。今回は使いませんでしたが、「normalbae」を使って法線マップを抽出しても面白かったかもしれません。
{kind=link}
{kind=link}
こちらの画像が気に入り、覚えたてのモデル「Tile」でアップスケール&詳細化してみることにしました。個別記事でも紹介しましたが、「Tile」は元画像の構造を維持しながら、低劣なディティールを破棄して新しいディティールに置き換えてくれる非常に画期的なモデルです。
アップスケール?描き直し?新モデル「Tile」ができること
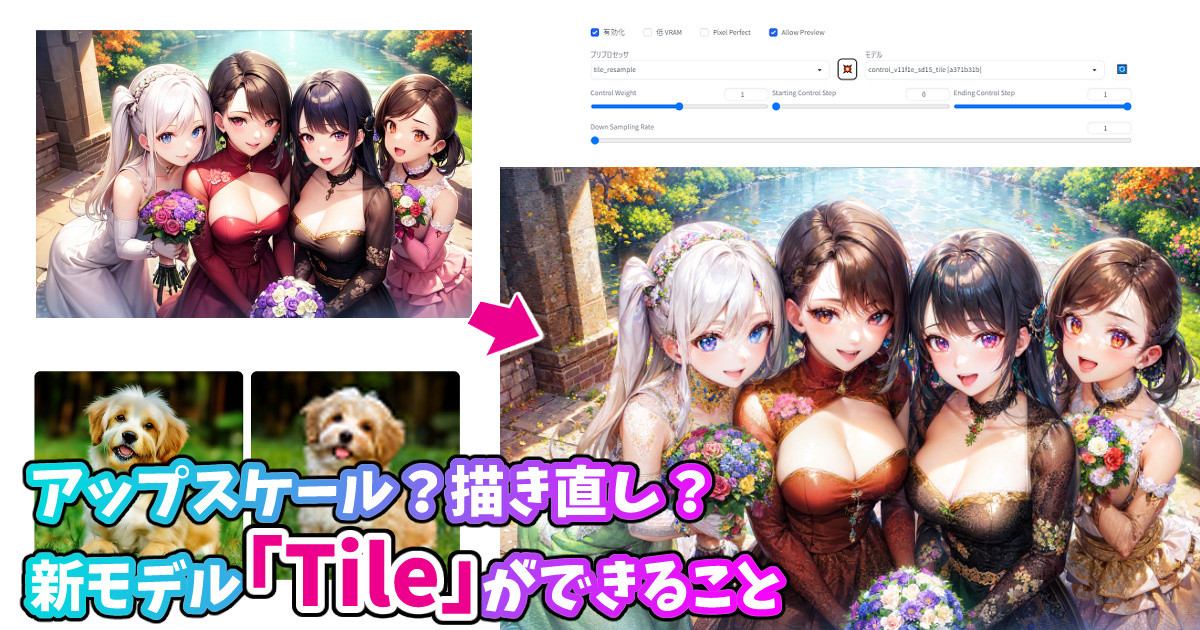
こんばんは、スタジオ真榊です。今夜は2023年4月25日付で完成したばかりのControlnet1.1用モデル「Tile」についての報告です。Controlnet1.1で使えるものの中でもひときわ異質なこのモデル。アップスケール用なのか?それともCannyやDepthのように構図を写し取るためのものなのか?いろいろと検証してみました。 ※Contro...
Tile+Depth+Lineartの同時掛けで、大きい1024x1536サイズで出力します。Tileには、先程のイラストをダウンサンプリングせずそのまま読み込ませました。その結果、
{kind=link}
かなり画質を上げつつ元画像の構図を写し取ることに成功しました。さらにtiled diffusionと組み合わせてより大きなサイズにしても良いのですが、今回は実験なのでこのサイズで完成までこぎつけてみようと思います。
先ほどの色合いには建物の古めかしさは出ているのですが、イラスト感をもっと出したいので、画像編集ソフトで色調補正することにしました。
{kind=link}
空の色が崩壊してしまいましたが、建物部分にこのようなレトロな虹色感を出したかったので、これはこれとして採用。今度はおなじみ「人力マージ」によって、空の部分がいい感じにできているこちらのイラストと合成します。
{kind=link}
構造物はほぼそのままに、空の部分だけを置き換えると…
{kind=link}
このような感じにできました。
人物のイラストを生成しよう
さてここからが難題。とりあえず背景はできましたが、人物のイラストとどう組み合わせたらいいのでしょうか。とりあえず、背景のない透過pngを得るべく、このような画像を作りました。AIで抜き出しやすいよう、プロンプト「simple white background」を使用しています。
{kind=link}
大丈夫、履いてますよ!手や下半身はどうせ見切れてしまうし、背景が真っ白でなくとも特段問題はないので、こちらの画像を採用することにしました。
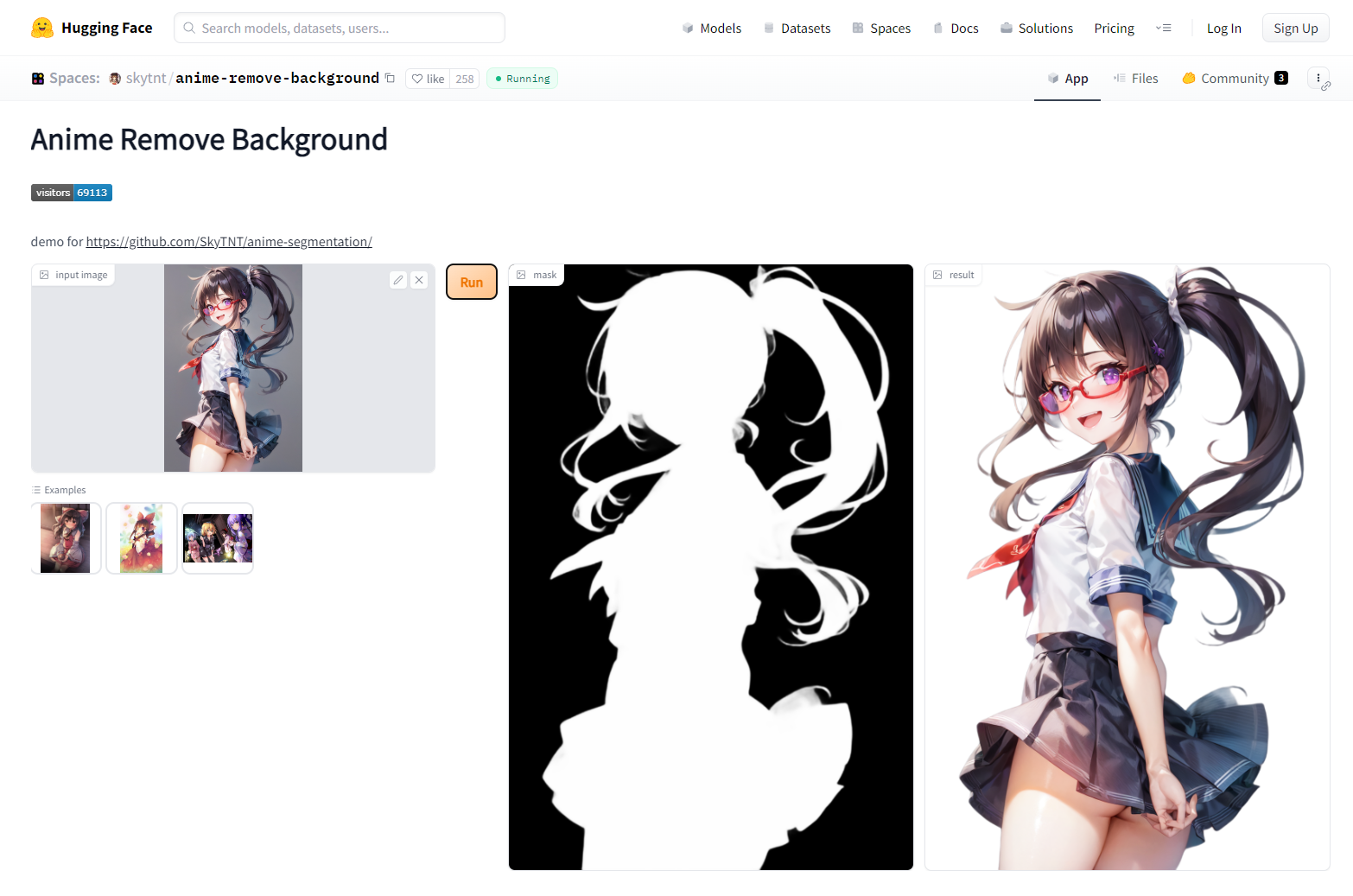
ABG removerという拡張機能を使うと、最初から背景を透過したイラストを画像生成することもできるのですが、好みの画像が出るまで大量にガチャするときには無駄な作業になってしまうので、今回は使いませんでした。
代わりに、以前も紹介した「anime-remove-background」を使って背景を切り抜きます。気に入った画像を放り込むだけで簡単に切り抜いてもらえるので重宝しています。
{kind=link}
できました!こちらをさきほどのイラストに合成すると…
{kind=link}
人物と背景を同時生成することによる低劣化を避けながら、意図した構図にすることができました。
次に問題になるのが「人物の浮き」です。このままではレイヤー合成したことがまるわかりですので、背景と人物を馴染ませてやる必要があります。
なじませる方法は実にいろいろあるのですが、今回は逆光をうまく使いたいので、グロー効果を使って馴染ませることにしました。CLIPSTUDIOにはデフォルトでグロー効果のオートアクションがあるのでとても簡単。まずは背景だけを表示させてグロー効果を掛けてみました。
{kind=link}
こちらはわかりやすいようキャンバス右側にだけグロー効果を掛けたもの。強すぎると輪郭がボケてしまうので、レイヤー透明度をいじりながら好みの強さに調整します。
キャラクターにも同様に掛けるのですが、画面全体がグローする(=光り輝く)と光学的に変ですし、どこを見たらいいのか分からないイラストになってしまうので、カメラ側からみて光が周りこまないはずのところは柔らかい消しゴムで消してしまいます。見せたいところは線が集まるところなので、それを意識してメリハリをつけました。
{kind=link}
パキッと浮いていたキャラの輪郭がグロー効果によって少し馴染んだと思います。
今度はキャラクターが溶けすぎている印象があったので、さらに線画を重ねて色トレスを試みます。人物をLineArtAnimeで線画化し、クリスタで白黒反転。さらに「輝度を透明度に変換」を使って線画を切り出したのがこちら。
{kind=link}
これをさきほどのイラストに重ねます。
{kind=link}
さらに色トレスを加えます。色トレスとは、線画の上に周囲の色と馴染む色を重ねることで、線画部分だけが悪目立ちしないようなじませる技術のこと。
まず背景をレイヤー複製して線画の一つ上に配置し、強めにぼかします。「明るさとコントラスト」で明るさを低く、コントラストを高くします。そうしたら「下のレイヤー(つまり線画のレイヤー)でクリップ」を選ぶと…
{kind=link}
線画が真っ黒ではなく、周囲の色に馴染む形で色に濃淡がつきました。
あとは髪の毛の末端など余計な線を消して、残したい部分だけを残しましょう。
{kind=link}
いい感じですね!
あとは大きく目を引く「本日初日」のフォントが気になるので、ここも加工します。
{kind=link}
Lineart realisticで線画化したものを切り抜いて重ね、破綻しているところを簡単に塗り重ねました。
{kind=link}
これで完成!
背景のイラスト化と人物の合成は光の向きによっていろんな方法があるようです。門外漢の賢木が解説するよりも、プロによる解説がいろんなところで見られるので、ぜひ検索してみてください。
元の素材写真とフェード加工で重ねてみると、シームレスに重なっていて不思議な感じ。人力マージに写真そのものを混ぜても面白かったかもしれません。
今回使用したモデルは「Lineart anime+Lineart realistic+depth zoe+tile」の4つ。他にも、進化したSegmentationやOpenposeをうまく活かす方法がたくさんあるので、ぜひいろいろ検証していきたいと思います。
例によってVLLOで動画化もしてみました。とっても楽しい!
それではGW中ですので、今日はこのへんで。皆様も楽しい連休をお過ごしください。私はこれから、楽しみにしていたグリッドマンユニバースを見に行きます!
シーユーアゲイン!バイバイ!(by天国大魔境)
Files