Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

Controlnetが理解る!SD1.5系向けモデル15種&プリプロセッサ35種を徹底解説 (Pixiv Fanbox)
Content
こんばんは、スタジオ真榊です。こちらはStableDiffusionwebUIに大きな革命をもたらした拡張機能群「Controlnet」の大型解説記事です。2023年春に登場した「ver1.1」について、2023年4月27日時点で使用できるモデル14種とプリプロセッサ全35種のそれぞれの特徴とできることを検証しました。
「Controlnet」はひと言でいうと、ある画像をAIに参照させ、その画像に描かれたものの輪郭や立体感などを抽出することで、それをベースにした画像を生成できる機能群のこと。例えば、このように左の画像から線画部分だけを抽出し・・・
{kind=link}
プロンプトで「金髪にして」と頼むと、線画は同じでカラーの違う画像を生成することができます。つまり、現象だけ見れば「線画をAIに着色してもらう」結果になるわけです。
{kind=link}
このように線画部分だけを継承できる「Lineart」のほか、ポーズだけを継承できる「Openpose」、深度情報だけを継承できる「depth」といったさまざまなControlnetモデル(以下CNモデル)があり、それらを有効に動かすための下ごしらえをする「プリプロセッサ(前処理機能)」というものが個別に用意されています。これらを使いこなすと、このようにさまざまな絵作りができるようになるわけです。
{kind=link}
今回の記事は、CNモデルとプリプロセッサの組み合わせやパラメータ設定、それによってできることなどを詳しく解説していく「総論」的な解説。「各論」に当たる各モデルの詳しい検証記事もリンクしてありますので、ぜひご活用ください。
【★重要】Controlnetはベースモデルによって使えるモデルが異なり、こちらの記事で紹介しているのは主にSD1.5系専用のControlnet(以下CN)モデルです。AnimagineXLなど、SDXL系のモデルで使いたい場合はSDXL専用のCNモデルを使いましょう。
{kind=link}
目次
インストール&アップデート方法
モデルのダウンロード
モデルの種類とできること
プリプロセッサとは
プリプロセッサ一覧
操作画面の見方
【解説】Controlnetでできること
- invert(from white bg & black line)
- キャニー法
- 深度シリーズ
- inpaint global harmonious
- Lineartシリーズ
- openposeシリーズ
- mediapipe_face
- mlsd
- normal bae
- scribbleシリーズ
- segmentation(seg)シリーズ
- shuffle
- softedgeシリーズ(旧Hed)
- しきい値
- Tile resample
- なし-Pix2pix
終わりに
{kind=link}
インストール&アップデート方法
まずはこちらがStableDiffusion用のControlnet(ver.1.1)公式Githubです。Controlnet開発者が公開した「Forge」では、デフォルト機能として最初からControlnetが使えますが、A1111版SDwebUIでは最初に拡張機能としてインストールする必要があります。
インストールは簡単。SDwebUIの「拡張機能」タブから「URLからインストール」をクリックし、「拡張機能のリポジトリのURL」欄に「https://github.com/Mikubill/sd-webui-controlnet.git」と入力します。
{kind=link}
インストールボタンを押して少し待つと、入力欄の下にインストール完了を告げるメッセージが表示されるので、2つ隣の「インストール済」タブに移動し、「アップデートを確認」ボタンをクリック。読み込みが終了したら、「適用して UI を再起動」ボタンを押せばOKです。再読み込みに失敗したらF5キーなどでブラウザ画面を更新してください。txt2txtの画面の下の方に「controlnet」というタブができていれば成功です。
{kind=link}
アップデートの有無も確認しておきましょう。webUIの「拡張機能」から「アップデートを確認」をクリック。「sd-webui-controlnet」の欄の右端にある「アップデート」のところに「更新あり」と出たら、「適用してUIを再起動」すればOKです。
★Controlnetのタブが表示されないときは
インストールやアップデートの後、webUIが再読み込みしたのに、txt2txtの画面にControlnetのタブが表示されないことがあります。そんなときは慌てずに、いったんブラウザのwebUIタブと黒いコマンドプロンプト画面を閉じてみましょう。画面上での「再読み込み」でなくwebUIそのものを立ち上げ直せば、再びいつもの場所にウィンドウが出現しているはずです。
・それでも表示されない場合は、Controlnetのアップデートもしくはインストール作業が完了していない可能性があります。もう一度「アップデートを確認」して、「最新版」と表示されるかどうか確かめてみましょう。
{kind=link}
モデルのダウンロード
次に、controlnet1.1で使えるCNモデルをダウンロードしましょう。SD1.5系とSDXL系で使えるCNモデルと入手先は異なります。
・SD1.5系
まずはこちらのURLにアクセス。
こちらに並んでいる「.pth」で終わるモデルファイルの中から必要なものをダウンロードし、下記のいずれかのフォルダに入れましょう。どちらでも同じですが、①のmodelsフォルダの方が浅いし、他のモデルと同じ場所なのでおすすめ。ファイル名に「sd15」とあるのは、SD1.5系専用のCNモデルであることを示しています。
①「stable-diffusion-webui\models\ControlNet」
②「stable-diffusion-webui\extensions\sd-webui-controlnet\models」
「必要なものと言われても何がなんだか・・・」という状態と思いますが、最初にいくつか試してみるなら、人体のポーズを抽出できる「openpose」か、アニメ調イラストの線画を抽出できる「lineart anime」、同様に被写体の輪郭を抽出できる「canny」あたりがオススメです。それぞれのpthファイルの「1.45GB LFS↓」をクリックすればダウンロードできます。
{kind=link}
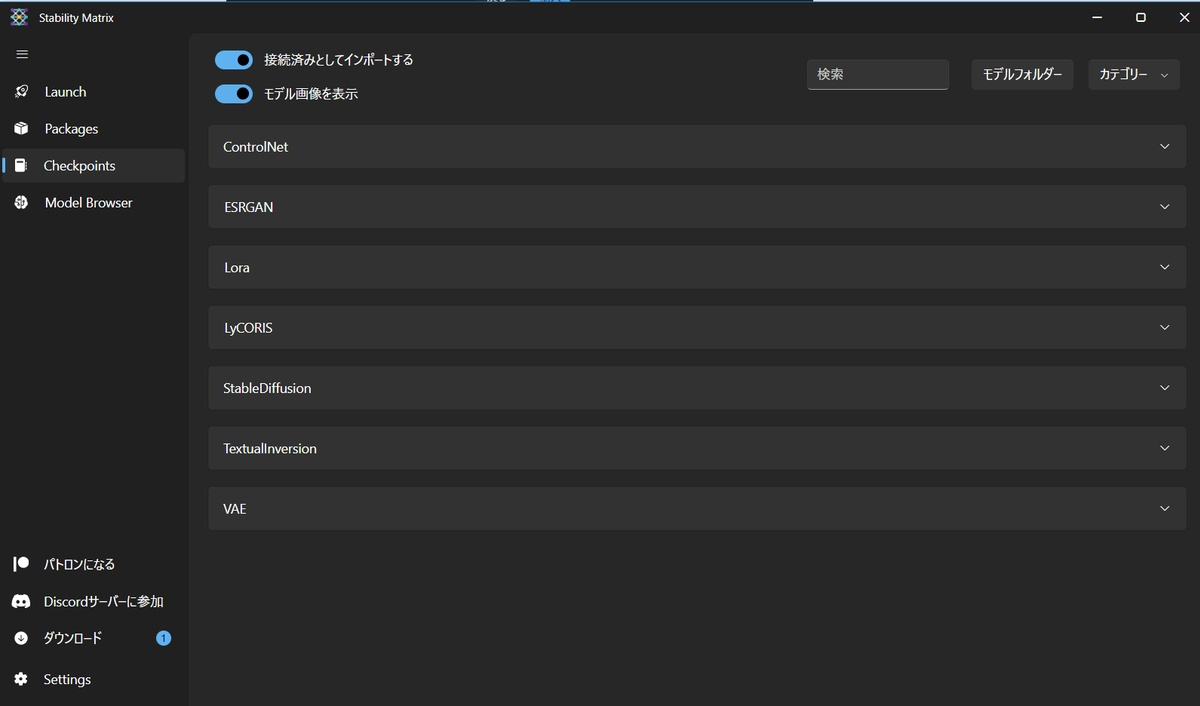
※StabilityMatrixをお使いの場合は、「Checkpoints」の欄の中にある「Controlnet」の欄に保存しましょう。ここに入れておけば、インストールした各webUIで使えるようになります。
{kind=link}
かなり大きいサイズなので、最初から全てDLせず、試したいものだけでもいいかもしれません。これらの公式pthファイルを初めて使う場合、「yaml」ファイルはダウンロードする必要はありません。(モデルにアップデートがあり、新しいものに置き換えた場合はyamlファイルもダウンロードしましょう)
ファイル容量が半分(723MB)に抑えられたfp16版も既に出ているので、わかる方は始めからこちらを試してもOKです。ただ、1.45GBの公式版と違い、対応するyamlファイル名とモデルのファイル名を手動変更で一致させる必要がありますので、その点だけご注意ください。また、未確認ですが、一部で公式版と異なる挙動をすることがあるようです。
【mediapipe faceのモデルは別の場所に】
{kind=link}
表情抽出モデル「mediapipe face」のモデルは別の場所で配布されています。こちらの一覧から「control_v2p_sd15_mediapipe_face.safetensors」を同じフォルダにダウンロードしてください。
・SDXL向け
SDXL専用のCNモデルはこちらにまとめられています。
ファイル名の冒頭は制作者を示していることが多く、「xl」と入っていればSDXL向けのCNモデルです。1.5系モデルと同じように「canny」や「lineart」といった各種モデルが用意されています。個人的な体感ですが、1.5系モデルではうまくいったことがSDXL用モデルだとうまくできないことがあり、拡張機能としてはまだ発展途上なのかなという印象があります。
{kind=link}
CNモデルの種類とできること
次に、各CNモデルがどんなことができるのかをざっと解説していきます。
キャニー法(輪郭抽出):control_v11p_sd15_canny.pth
→元画像の輪郭(エッジ)を継承した別のイラストを生成できる。元イラストの被写体をおおむねそのまま引き継げる。
Lineart(線画抽出):control_v11p_sd15_lineart.pth
→元となる写真やイラストの主線を引き継いだ別のイラストを生成できる。Cannyとよく似ているが、非常に正確に主線を再現できるCN1.1からの新機能。
LineartAnime(アニメ線画抽出):control_v11p_sd15s2_lineart_anime.pth
→アニメ調イラストの線画を着色するのに適したlineartモデル。既存のカラーイラストから線画を継承するだけでなく、自分で用意した線画を着色することもできる。
深度抽出:control_v11f1p_sd15_depth.pth
→元画像に描かれているもののうち、何が手前にあり、どこが奥にあるかの「深度情報」を推測して抽出することで、同じ構図の絵を生成できる
インペイント:control_v11p_sd15_inpaint.pth
→マスクした部分を別のものに変えられる。i2iの「inpaint」と似ているが、周囲に描かれているものを強く意識して「続き」を描けるので、工夫すると途切れたキャンバス外の続きを描かせる(=アウトペイント)こともできる。i2iのinpaintと異なり、マスクしていない部分が変容する点に注意が必要。
Pix2pix:control_v11e_sd15_ip2p.pth
→「髪を赤くして」「彼女をカウボーイ風にして」「葛飾北斎調のイラストにして」などと指示することで、元画像に任意の変化を起こせる
シャッフル:control_v11e_sd15_shuffle.pth
→元画像をパズルのピースのようにして「再構成」することで、同じ色合いの別の絵を生成できる
ソフトエッジ(旧Hed):control_v11p_sd15_softedge.pth
→キャニーとは別の輪郭抽出技術。キャニーよりもおおまかなエッジを抽出し、元イラストの被写体をおおむね引き継いだイラストを生成できる。
mlsd(直線抽出):control_v11p_sd15_mlsd.pth
→元画像の中の「直線部分だけ」を継承する特殊なモデル。曲線で構成されるキャラクターなどは無視されるので、パース構造やカクカクした背景(ビルなど)のみを引き継ぎたいときに。
法線マップ抽出:control_v11p_sd15_normalbae.pth
→元イラストの陰影を元に立体を表現した「法線マップ」を抽出することで、元画像と同じ凹凸の画像を生成できる。深度情報を読み込むdepthに似ている。
オープンポーズ(表情・ポーズ抽出):control_v11p_sd15_openpose.pth
→読み込んだ画像の表情やポーズ、手の位置や形といった位置情報だけを継承して、同じ表情・ポーズの全く別の画像を生成できる。キャニーや線画抽出だと同じ「外形」のイラストしか作れないが、こちらは「口を大きく開けている」とか「こんなポーズをしている」といった情報のみを引き継げる違いがある。表情抽出ができるモデルでは、openpose faceの他に「mediapipe_face」もある。
mediapipe face(表情抽出):openposeとは別の手法で画像内の顔面を認識し、表情を写し取れる技術。openposeはイラストから表情抽出するのがやや苦手だが、こちらは比較的抽出できるようだ。
scribble(手描き入力):control_v11p_sd15_scribble.pth
→手描きした落書きやラフを元に完成イラストを出力できるように学習したモデル。5秒で描いたマウス絵からでも、AIが完成品を推測し、整った絵を生成してもらえる。
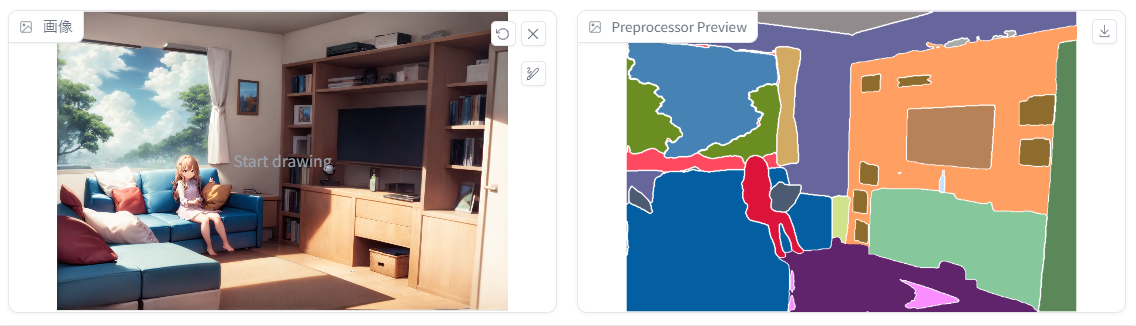
segmentation(領域分析抽出):control_v11p_sd15_seg.pth
→「描いて欲しい場所」と「描いて欲しいもの」を同時注文できる機能。入力した画像の「どこに何が描かれているか」を分析して、塗り絵のように「Person」「Sky」「Ground」などと色分けした上で、それぞれを継承した同じ構図の絵を生成できる。一見難解だが、使いこなせると非常に便利。
描き直しアップスケール:control_v11f1e_sd15_tile.pth
→入力した画像をタイルのように分割し、それぞれを個別に詳細化して元の形にくっつけることで、同じ構図の画像を高精細に生成できる「描き直し」機能。従来のアップスケールに比べ、大胆に拡大・高精細化しても画像が分裂しにくい。
※「MultiControlnet」という機能を使えば、複数のモデルを使って1枚の画像を生成することもできます。例えば、cannyとdepthでそれぞれ別々の画像から輪郭と深度情報を同時抽出したり、mlsdで背景を、openposeでキャラの位置を指定したりして、1枚の画像として合体させることなども可能です。詳しい設定方法や組み合わせなどはこちらの記事をご参照ください。
超革命!「Multi Controlnet」でできるようになったこと

こんばんは、スタジオ真榊です。前回は「Segmentation」を使った構図コントロールのやり方について紹介しましたが、今夜は「canny」や「depth」なども含め、最新のControlNetをフルに使うと何が可能になるのかについて、かなり長文で取り上げていきたいと思います。久々の大型記事ですね! ControlNetをめぐっては、「Co...
{kind=link}
プリプロセッサとは
プリプロセッサは、読み込ませる画像をControlnetの各モデルが理解できる形に前処理する「下ごしらえ」担当の機能です。例えば、「lineart」というcontrolnetモデルは黒地に白で描かれた線画を読み込んで同じ線のイラストを生成できるようトレーニングしているので、通常の線画(白地に黒で描かれたもの)をそのまま読み込ませるとネガポジ反転した変な画像ができあがってしまいます。そこで、白黒反転できるプリプロセッサに下ごしらえをさせる必要がでてくるわけです。
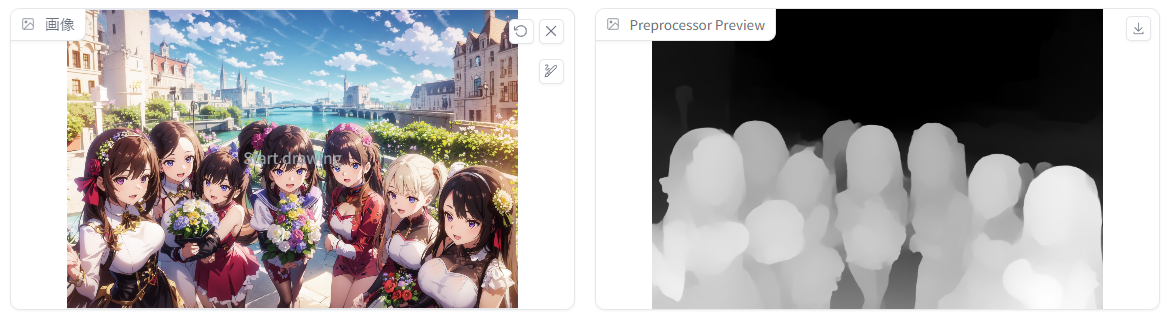
こちらの画像は、「depth midas」というプリプロセッサでカラーイラストから深度情報を抽出したスクリーンショット。
{kind=link}
これを「depth.pth」に読み込ませることで、深度情報を継承した新しい画像を生成することができるわけです。左の画像をそのままで読み込ませても、depthモデルは処理することができません。
プリプロセッサを「なし(none)」にすると、読み込ませた画像を下処理せず、そのままControlnetのモデルに送ることができます。例えばOpenpose用のポーズ情報を自分で用意した場合、既に自分で下処理済みなわけですから、プリプロセッサに掛ける必要がないため「なし」を選ぶことになります。「Pix2pix」や「Shuffle」のように、下処理をせずに読み込めるモデルもあります。
前段階のプリプロセッサと本番の各モデルの組み合わせは必ずしも一つだけではなく、求めている処理・完成像によって使い分ける必要があります。
{kind=link}
プリプロセッサ一覧
次に、それぞれのモデルに応じたプリプロセッサ一覧を見てみます。
{kind=link}
※2023年4月27日現在
invert(from white bg & black line):ネガポジ反転用
キャニー法:元画像の輪郭を抽出する
softedgeシリーズ(旧Hed):Cannyと異なる技術で、大まかに輪郭を抽出する
深度シリーズ:深度情報を抽出する
inpaint global harmonious:「inpaint.pth」用
lineartシリーズ:線画抽出用
mediapipe_face:表情抽出用
mlsd:元画像の直線部分のみを抽出する
normal bae:法線マップ抽出用。※normal midasはCN1.0のnormalmap用
openposeシリーズ:表情・手・ポーズ抽出用。
scribbleシリーズ:既存画像を落書き風に抽出する
segmentation(seg)シリーズ:領域分析用。描かれているものと場所を色分けする
shuffle:「シャッフル」用。元画像を渦状にゆがませる
しきい値:二値化処理(白と黒に分ける)
tile resample:「敷き詰めアップスケール」用
{kind=link}
操作画面の見方
{kind=link}
有効化
ここにチェックを入れることで、Controlnet機能を発動できる。入れ忘れに注意。
低VRAM
グラフィックボードのメモリ(VRAM)が8GB以下の場合はこちらにチェックを入れると、画像の生成速度が大きく下がる代わりに、VRAM不足の環境でもエラーを回避して生成することができる。VRAM4GBでも動作したとの報告あり。
Pixel Perfect
CN1.1から新設。プリプロセッサは使用する際に解像度(Preprocessor resolution)を手動で設定する必要があるが、ここにチェックを入れておくと、自動で最適なプリプロセッサ解像度が計算される。
Allow Preview
CN1.1から新設。ここにチェックを入れて、プリプロセッサ欄とモデル欄の中間にある爆発ボタンをクリックすることで、プリプロセッサが元画像から何を抽出したかプレビューしたり、抽出画像を編集したりすることができる。プレビュー画像は右上の「↓」ボタンでダウンロード可能。Lineartで抽出した線画は、画像編集ソフトで黒白反転させると通常の線画として画像編集に使える。
Controlnet weight
Controlnetの「重み」を調整できる。1(=100%)が基本で、それ以下に弱めるとControlnetで入力した抽出情報の参照度が下がる。プリプロセッサやモデルの組み合わせ、どんな画像を作りたいか等によって適切な設定は異なる。詳しくは各モデルの各論参照。
StartingControlStep / EndingControlStep
Controlnetの効果がステップ全体のどの範囲に効かせるか選ぶことができる。
0が0%、1が100%を意味しており、デフォルトでは「0でスタート、1でエンド」。こうしておくとノイズ状態(0%)から生成終了(100%)まで全てのステップにControlnetが影響するが、例えばスタートを「0.8」にすることで、全体の80%に当たるステップ数から影響が出始める。(画像生成の最後の20%だけ影響するという意味)
なぜこんな機能が必要かというと、ステップ全体に効かせると画像生成に制約が掛かりすぎて品質が低下してしまうことがあったり、手の輪郭だけを指示したいのに、全ステップにその輪郭が効いてしまうと「手しかないイラスト」ができてしまったり…という不都合をなくすため。モデルによって適切な設定は異なるが、基本は「スタート0エンド1」もしくは「スタート0エンド0.6」程度にしておき、品質低下や不都合が生じたら調整するといい。
Preprocessor resolution
プリプロセッサ(前処理)を行って生成する下処理画像の解像度。Pixel PerfectをONにすることで入力を省略することができる。手動で入力する場合、数値が64の倍数でないと自動で近似値に調整されて横縦のサイズがおかしくなるなど不都合が起きるので注意。特に線画を抽出する際は、元画像と重ならなくなってしまう。
制御(control)モード
プロンプト指示とControlnetの指示のどちらかをより強く影響させることができる。デフォルトでは両方を取り入れる「バランス」モードになっているが、例えば「my prompt is more important」を選ぶとControlnetの指示よりもプロンプト再現を優先してくれる。CNモデルによってこのモード別の生成結果は大きく変わるので、XYZ Plotを使ってテストしてみるとよい。
{kind=link}
{kind=link}
【解説】Controlnetでできること
前置きはここまでで、いよいよ本題の「それぞれのモデルとプリプロセッサを使って何ができるのか」を具体的に解説していきます。モデルよりプリプロセッサの種類から見ていく方が組み合わせや使用目的を理解しやすいので、順番に見ていきましょう!
invert(from white bg & black line)
{kind=link}
組み合わせるモデル:canny,lineartシリーズ
できること:ネガポジ反転が必要なデータを読み込ませられる
元画像をネガポジ反転させるだけのプリプロセッサ。手元にある「白地に黒い線で描かれたモノクロ画像」をControlnetで読み込ませる場合はこちらを使って、黒字に白線の画像にしてから読み込ませる。Controlnet1.1では、「背景:黒、主線:白」で読み込むモデルが多いため、自分で用意した線画やマップなどが白黒逆になっている場合はこちらを使って反転させる必要がある。
LineartAnimeで生成した結果▼
{kind=link}
▼関連記事
AIを使って「線画に色塗り」をしてもらおう!

こんばんは、スタジオ真榊です。今夜はこちらのツリーでも紹介した、線画を使ったAIイラスト生成についての記事です!線画にAIで着色するために必要ないろいろなTIPSや、controlnetの各種設定の方法、線画をできるだけそのままにしながらリッチにスケールアップする方法など、実用的な技術について解説できればと思いま...
※ちなみに、「白地に黒」の画像を反転しないまま入力するとこのようになります
{kind=link}
{kind=link}
キャニー法
{kind=link}
組み合わせるモデル:canny
できること:元画像の輪郭を継承した別のイラストを生成できる。被写体をおおむね引き継げる。
概要:元画像の「輪郭(エッジ)」を抽出するプリプロセッサ。キャニー法とは、ジョン・F・キャニー氏が1986年に編み出したアルゴリズムのこと。抽出された輪郭情報はきれいな線画にはならないので、多少がちゃがちゃして見えるが、これをCanny法を学習させたモデル(canny.pth)に読み込ませることで、元画像と同じ輪郭を引き継いだ画像が生成できる。「Lineart」シリーズの登場によって上位互換されたと思われるが、Cannyの方にアドバンテージがある場面もあるかもしれない。今後の研究課題。
パラメータ解説:Canny low/high thresholdというパラメータを操作することで、輪郭をどれほど詳細に抽出するか調整可能。
生成結果▼
{kind=link}
{kind=link}
深度シリーズ
・depth leres
{kind=link}
・depth midas(旧depth)
{kind=link}
・depth zoe
{kind=link}
組み合わせるモデル:depth
できること:元画像に描かれているもののうち、何が手前にあり、どこが奥にあるかの情報を推測して抽出することで、同じ構図の絵を生成できる
概要:抽出画像は、白いものほど手前に、黒に近づくほど奥にあることを示している。3種類のプリプロセッサによって抽出結果に差があり、「depth leres」のみ「Remove Near %」「Remove Background %」というパラメータにより背景と手前にあるものの濃さを調整可能。引き継ぐのは位置関係のみで、何が描かれているかまでは継承しないので、プロンプトによって大きく変容させられる。
生成結果(zoe)▼
{kind=link}
▼手の修正に使う方法も
「depth」にこのような素材を送り込んで、破綻した手などをきれいに修正するSDwebUIの拡張機能がある。細かいパラメータ設定にコツがあるため、詳しくは関連記事をご参照ください。
{kind=link}
▼関連記事
【ゲームエンド!?】controlnet拡張で手の描写を支配しよう!

こんばんは、スタジオ真榊です。なぜか本日突如として7年間続いたシャドウバンが解けまして、ツイッター上でたくさん通知が来て楽しい一日を過ごせました笑 18禁アカウントなのにいいんですかねイーロンさん… さて、本日は非常にエキサイティングなControlnetの拡張機能が登場しましたので、さっそく実験をしてみました...
{kind=link}
inpaint global harmonious
{kind=link}
組み合わせるモデル:inpaint
できること:マスクした部分を別のものに変えられる。i2iの「inpaint」と似ているが、周囲に描かれているものを強く意識して「続き」を描けるので、途切れたキャンバス外の続きを描かせることもできる。i2i画面のinpaintモードで使用するものと思いがちだが、t2i画面でも使用できる。(controlnetの画面上でマスクできる)
マスクしていない部分が変容してしまう不具合(?)があることに注意が必要。詳細は個別記事を参照のこと。
▼関連記事
新モデル「inpaint」でイラストの続きを描いてもらおう!【Controlnet1.1検証】

こんばんは、スタジオ真榊です。前回の「Pix2pixでイラストを変化!10種の実験で分かったこと」に引き続き、今回もControlnet1.1でできることを検証していきます。 今回紹介するのは、新モデル「inpaint」。これはその名の通り、マスクした部分を描き直すインペイント機能に特化したControlnetモデルです。とはいえ「ima...
▼生成結果
{kind=link}
{kind=link}
Lineartシリーズ
{kind=link}
組み合わせるモデル:lineart、lineart anime
できること:元イラストの主線(線画)を引き継いだ別のイラストを生成できる。自分で用意した線画を着色することもできる。
概要:「canny」とよく似ているが、CN1.1から登場したLineartシリーズはより元画像に忠実な輪郭を抽出することができる。プリプロセッサは「Lineart anime」「Lineart realistic」「Lineart coarse」「Lineart standard(白黒反転)」の4種があり、それぞれ抽出される線画の特徴が異なる。具体的な設定などは関連記事を参照のこと。
▼関連記事
Controlnet1.1爆誕!顔抽出&アニメ主線抽出&線画塗りを試してみた
こんばんは、スタジオ真榊です。AIイラスト術天下一武道会の開催真っ最中ですが、Controlnet1.1がSDwebUIの拡張機能にぃ… きたー!!! というわけで、既に午前2時なのでかなり限定的な内容にはなりますが、前置きは全てすっ飛ばして最速でアプデ方法と注意点、使用感をお伝えしていきます。今回は「FaceLandmark」によ...
①Lineart anime(アニメ調線画抽出)
{kind=link}
アニメ調イラストの線画抽出に特化したプリプロセッサで、CN1.1の目玉と言っても過言ではないほど便利。線がガタガタするCannyと違い、白黒反転させただけで線画として使えそうなレベル。LineartAnimeに読み込ませるのが基本だが、「Lineart」で読み込んでもけっこう良い結果になる。
{kind=link}
▲線画部分に矛盾しなければ、余白にプロンプト指示で好きなものを描いてもらうこともできる。これは「outdoor」を指示したもの。
②Lineart realistic
{kind=link}
{kind=link}
フォトリアル系の画像から輪郭を抽出するのに特化したプリプロセッサ。フォトリアル系の学習モデルで使用しないと、顔面の線などがイラスト調に読み込まれてホラーなテイストの画像ができてしまう。詳細に抽出されすぎる場合は「Lineart coarse」を使うと線の数を減らせる。
{kind=link}
③Lineart coarse(粗い抽出)
{kind=link}
こちらも写真からの線画抽出のためのプリプロセッサ。「Lineart Realistic」だと抽出される線が多すぎて、上の黒人イラストのようにリアルすぎる生成結果になるので、もう少し線の数を減らしたいときはこちらを使う。アニメ調イラストに適用すると、すべての線をそのまま忠実に抜くのではなく、ややラフ画風に抜き出される。
{kind=link}
▲左の画像が「coarse」、右の画像が「realistic」を使った生成画像。右のほうが線の情報量が多いことがわかる。
④「Lineart standard(白黒反転)」
{kind=link}
自分で用意した線画(白地に黒い線で描いたもの)を処理するためのプリプロセッサ。もちろんプロンプトにもよるが、送り先をLineartにするか、Lineart animeにするかで出力画像のテイストが変わる。
Lineartで読み込んだ場合▼
{kind=link}
Lineart animeで読み込んだ場合▼
{kind=link}
⑤lineart_anime_denoise
漫画からスクリーントーンの影響を除去して線画だけを抜き出せる新しいプリプロセッサ。他人の著作物から線画を抜き出すのはモラルに反するので、個人的には使いません。
{kind=link}
openposeシリーズ
{kind=link}
組み合わせるモデル:openpose
できること:読み込んだ画像に描かれた人物の表情やポーズ、手の位置や形といった位置情報「だけ」を継承して、同じ表情・ポーズの全く別の画像を生成できる。
概要:キャニーや線画抽出だと同じ「外形」のイラストしか作れないが、こちらは「口を大きく開けている」とか「こんなポーズをしている」といった情報のみを引き継げる。openpose faceによる表情抽出はリアル調の画像からなら上手に抽出することができるが、イラスト調の画像からはうまく目鼻の位置をプロットできないことが多いのが注意点。AI利用OKの「ポーズマニアックス」からスクリーンショットするなど、モデル画像を使うと便利。
▼特記事項
2023年8月、openposeの上位互換版のプリプロセッサ「DW openpose」が追加され、世界が一変した。詳しくはこちらの個別記事を参照のこと。
新プリプロセッサ「DW openpose」登場!旧Openposeよりどうスゴイ?

こんばんは、スタジオ真榊です。今夜は知らぬ間にControlnetに仲間入りしていた新プリプロセッサ「DW openpose」の検証記事です。 「DWposeという技術を使った、Openpose fullよりスゲースゴイ全身用プリプロセッサです」で説明がもう終わってしまうのですが、確かにこれ…スゴイです!(語彙力喪失) こちらの適当な5人...
▼関連記事
Controlnet1.1爆誕!顔抽出&アニメ主線抽出&線画塗りを試してみた
こんばんは、スタジオ真榊です。AIイラスト術天下一武道会の開催真っ最中ですが、Controlnet1.1がSDwebUIの拡張機能にぃ… きたー!!! というわけで、既に午前2時なのでかなり限定的な内容にはなりますが、前置きは全てすっ飛ばして最速でアプデ方法と注意点、使用感をお伝えしていきます。今回は「FaceLandmark」によ...
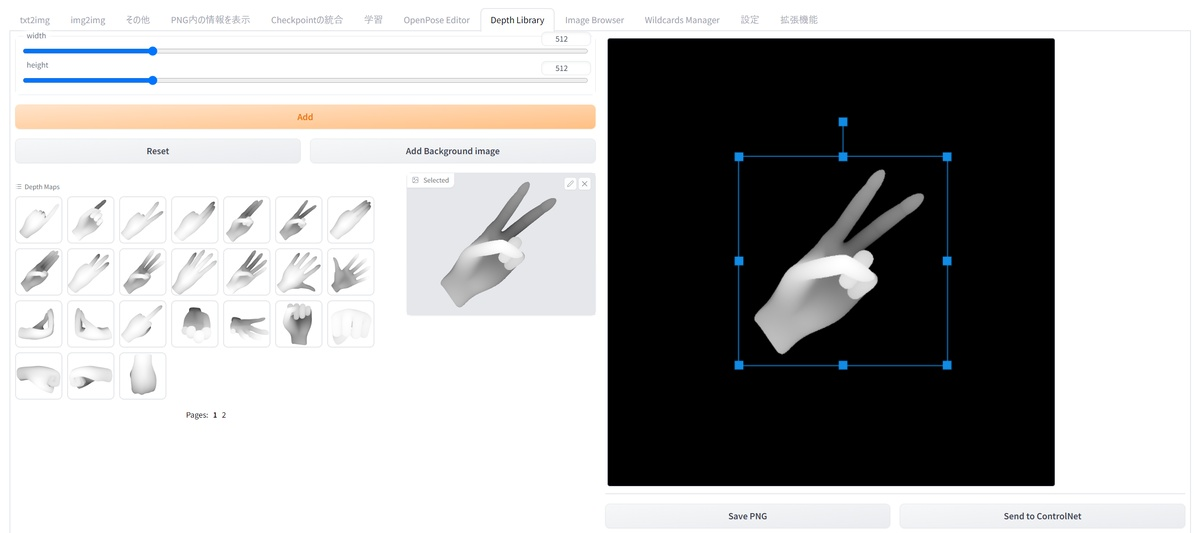
ちなみに、ポーズ情報(カラフルな某人間)は色さえ合っていれば認識するので、自分で描くこともできるし、多数のポーズが共有されているサイトもある。拡張機能「Openpose Editor」を使うことによって、元画像がなくても自分でポーズをつけることも可能。その場合はプリプロセッサを「なし」にして、直接モデルに読み込ませよう。
【OpenPose Editor導入】もっと自由にポーズをつけよう!(ControlNet解説)

こんばんは、スタジオ真榊です! ControlNet、してますか?毎晩寝不足な日々が続いていますが、今夜は前回の「ControlNet徹底解説!プロンプト苦難の時代が終わる…」に続き、具体的なポーズの付け方についての実践編です。 ControlNet公開以来、特にキャラクターのボーン(骨組み)でポーズ指定できるOpenposeをより自由...
{kind=link}
mediapipe_face
{kind=link}
組み合わせるモデル:mediapipe_face(※他のモデルと違い、上記URLから入手する必要あり)
できること:画像の表情「だけ」を継承して、同じ表情の別の画像を生成できる。
概要:Openposeの「face」と別の仕組みで抽出する表情抽出技術。openpose faceによる表情抽出はアニメ調のイラストからはうまく目鼻の位置をプロットできないことが多かったが、こちらはそうしたイラストからでも上手に抽出できる。「openpose face」が目・鼻・口の位置を忠実に再現しようとするのに対し、こちらはより表情を柔軟に解釈して、崩壊しない程度に模倣してくれるので使い勝手がよい。
「max faces」でいくつまで顔面を抽出するかを、「min face confidence」で抽出に関わるしきい値をそれぞれ設定できるが、顔面部分がキャンバス内でそれなりの大きさを占めていないと認識できない。ちなみに、openposeと同様、抽出画像は色さえ守れば自分で描いても認識してもらえる。
▼生成結果
{kind=link}
※目の位置、顔の角度、口の開き具合がそれぞれ微妙に異なるのに注目。下の図は同じ画像を「openpose face」で読み込んだもの。mediapipe faceの方が「元画像からの再現度は低いものの自然な表情」に感じられる。
{kind=link}
{kind=link}
mlsd(直線抽出)
{kind=link}
組み合わせるモデル:mlsd
できること:元画像の中の「直線部分だけ」を継承する特殊なモデル。曲線で構成されるキャラクターなどは無視されるので、パースやカクカクした背景(ビルなど)のみを引き継ぎたいときに。
概要:個人的にはあまり使う場面がないが、曲線を無視して直線部分だけを抽出してくれるプリプロセッサなので、パースの効いた町並みや室内など、直線的な無生物だけを抜き出したいときに使える。Hough value threshold (MLSD)とHough distance threshold (MLSD)の2つのしきい値を調整することで、抽出される線の量を調整可能。AIイラストは基本人体が描かれないことがあまりないので、つまりは背景用と割り切って使うことになる。
▼生成結果
{kind=link}
例えば、駅の風景をmlsdに読み込ませて、Multicontrolnetを使って同時に別のキャラクターイラストの指示と組み合わせたりすると、下の画像のように背景やパースを指定しながらキャラを呼び出すようなこともできる。が、それぞれの重みなどを微調整する必要がある上、破綻しやすいので中・上級者向け。
{kind=link}
▼左がmlsd、右がopenposeに読み込ませたもの。人物はlineart系でもよいが、線同士が干渉しあってうまく濡れないことが多いので、線を指定しないopenposeの方が破綻しにくい。
{kind=link}
{kind=link}
normal bae
{kind=link}
組み合わせるモデル:normal bae
できること:元イラストの陰影を元に凹凸を表現した「法線マップ」を抽出することで、元画像と同じ凹凸の画像を生成できる。
概要:深度情報を読み込むdepthに似ていて、キャラクターの線画ではなく輪郭を抜き出しつつ、表面の凹凸を擬似的に写し取ることができる技術。baeにおける法線マップは青が正面、赤が左、緑が上を示している。Blenderなど3DCG制作アプリケーションを使いこなせる人なら、自分で法線マップを作って読み込ませることも可能。
※normal baeはControlNet1.0における「Normalmap」の上位互換の模様。プリプロセッサ「normal midas」は旧normalmapを利用する際に組み合わせるために残されている模様なので、基本「bae」同士の組み合わせを使う。
▼生成結果
{kind=link}
{kind=link}
scribble
{kind=link}
組み合わせるモデル:scribble
できること:手描きした落書きやラフを元に完成イラストを出力できるように学習したモデル。5秒で描いたマウス絵からでも、AIが完成品を推測し、整った絵を生成してもらえる。上の画像のように、既存イラストを「落書き」化することもできる。
概要:「scribble xdog」「scribble hed」「scribble pidinet」の3種のプリプロセッサがある。それぞれ、XDoG(Extended Difference of Gaussians)、HED(Holistically-Nested Edge Detection)、PiDiNet(Pixel Difference Networks)という別々の輪郭抽出用アルゴリズムで、写真やイラストから「落書き」風に線を抜き出すことができる。使い分けは好みだが、XDoGはLineart寄りのかなり正確な線画を抜き出せる。
これらを使わなくても、マウスで描いた絵を白黒逆転させて「scribble」に送り込めば、おおむねその意図をプロンプトを参考に読み取って「いい感じ」に仕上げてくれる。かなりAIお任せ度の高いControlnet機能と言える。AIは注文が多いほどうまく描けなくなる傾向にあるので、「なんとなくこんな感じ」と指示したいときにScribbleが活躍してくれる。
◆落書きしてみよう!
落書きする場合はControlnet画面にある「メモ」のようなボタンをクリックする。
{kind=link}
すると下図のような画面が出てくるので、キャンバスサイズを指定して「create new canbas」を押せば白いキャンバスが表示される。
{kind=link}
自分で描く場合はプリプロセッサを「なし(none)」にするのを忘れないこと。
{kind=link}
上の適当なマウス絵で生成したのがこちら。
{kind=link}
5秒で描いたマウス絵でもそれなりに意図を読んでくれるので、絵が得意な人はラフ画くらいまで自分で描いてScribbleに清書させて、それをまたLineartAnimeで読み込んで…とやっていくと楽しい。こちらのツイートは、適当なマウス絵をscribbleとopenposeでいったん中間イラストにし、そこからCannyで輪郭を呼び出した上で、余計な部分を塗りつぶしてクォリティを高めた例です。
{kind=link}
segmentation(seg)
{kind=link}
組み合わせるモデル:segmentation
できること:「描いて欲しい場所」と「描いて欲しいもの」を塗り絵のような下絵を使って同時注文できる。
概要:入力した画像の「どこに何が描かれているか」を分析して、塗り絵のように「TV」「pillow」「book」などと色分けした上で、それぞれを継承した同じ構図の絵を生成できる。(下図はそれぞれの色が何を示しているかの参考画像)
{kind=link}
他の機能に比べて難解なので敬遠してしまいがちだが、使いこなせると非常に便利なので、ぜひ関連記事の解説をご覧ください。Controlnet1.0では「ADE20K」という規格だけだったが、1.1から「COCO」という規格が追加された。ADE20Kは150色、COCOは182色の概念を塗り分けられる。
{kind=link}
(▲例えば「river」の水色(#0BC8C8)で塗ったところには川が描かれるが、少し色が違うと「ドア」(#00ADFF)になってしまう)
プリプロセッサは「seg_ofade20k」「seg_ofcoco」「seg_ufade20k」の3種。前の2つがCN1.1から新たに導入された「Oneformer」という規格なので、基本的にこちらを使う。「ufade20k」を使うと、CN1.0のsegmentationでも使われていた「Uniformer」でade20kの塗り分けが行われる。
▼関連記事
【ControlNet革命】「Segmentation」で構図を支配しよう!

こんばんは、スタジオ真榊です。このところAIと著作権をめぐる投稿が続いてしまったので、しばらくは本題に戻って、いつものStableDiffusionを使ったAIイラスト術について紹介していきたいと思います。今回はControlnet機能の一つ「Segmentation」の活用法についてです! 「ControlNet徹底解説!プロンプト苦難の時代が...
{kind=link}
shuffle
{kind=link}
組み合わせるモデル:shuffle
できること:元画像をパズルのピースのようにして「再構成」することで、同じ色合いの別の絵を生成できる
概要:色合いやトーンを引き継ぎたいときに使う。例えば、cannyやLineartで女の子の線画を指示しておいて、Multicontrolnetで森の画像を「shuffle」すると、その色合いやトーンを参考に線画が塗られることになる。(▼)
{kind=link}
ただ、プリプロセッサで「shuffle」してゆがませるとその渦巻きに生成結果が引っ張られることがあり、使いこなすのがなかなか難しい。実はプリプロセッサ「なし(none)」で読み込ませても色合いなどを認識するので、目的によって使い分ける。Lineartなどで描きたいイラストの線画を確定しておき、好みの色合いのイラストをshuffleで同時に読み込んで、そのトーンに塗ってもらうのが分かりやすい使い方か。詳しくは関連記事参照。
▼関連記事
【Controlnet1.1検証】新モデル「Shuffle」でイラストを"再構成"しよう!

はいこんばんは、スタジオ真榊です。前回の「Controlnet1.1爆誕!顔抽出&アニメ主線抽出&線画塗りを試してみた」に引き続き、今回もControlonet1.1の検証記事をお届けします。 これから検証するのは、「Shuffle」「Pix2Pix」「Inpaint」の新顔3種モデル。前回紹介した「新Openpose」と「LineartAnime」はControlnet1....
{kind=link}
softedgeシリーズ(旧HED)
・Softedge Pidinet
{kind=link}
・Softedge Hed
{kind=link}
組み合わせるモデル:softedge
できること:キャニーとは別の輪郭(エッジ)抽出技術を使い、キャニーよりも大まかな輪郭抽出をすることができる。
概要:CannyやLineartと異なり、パキッとしていない主線も取り出せるのがsoftedgeの強み。プリプロセッサは「softedge hed」「softedge hedsafe」「softedge pidinet」「softedge pidisafe」の四種あり、それぞれ使用される輪郭抽出のアルゴリズムが異なる。「safe」と付いているのは、CN1.0にあった抽出時のエラー問題を起こりにくくしたものとのこと。公式によると、次のような違いがあるらしく、基本的には SoftEdge_pidinetを使用するのがオススメのようだ。
エラーの起きにくさ
SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
生成物の品質
SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
CN1.0ではsoftedgeでなく「HED」と表示されていたもの。1.0ではCannyとの違いがはっきりしなかったため、あまり目立たなかった印象があるが、今回のsofedgeは「以前のモデルと比較して大幅に改善された」と公式が胸を張っており、要研究。実際に品質も良く感じる。
▼生成結果(Softedge Pidinetによるもの)
{kind=link}
{kind=link}
しきい値
{kind=link}
組み合わせるモデル:?
できること:元画像を二値化して白黒画像に変換する。
概要:はっきり白黒に分けられていない線画を読み込むなど、特殊な状況で使うのだろうか。以前はこれで線画をCannyに読み込ませる方法があったが、白黒反転がボタン制でなくなったため、使いどころが限られた印象。
Controlnetで使える機能はどんどん増えており、グレースケール画像を着色することに特化したモデルも登場しているようなので、「しきい値」を掛けて読み込ませるモデルが出てくるのかもしれない。
{kind=link}
Tile resample
{kind=link}
組み合わせるモデル:tile
注意:当初は未完成のモデル「control_v11u_sd15_tile」が公開されていたが、2023年4月25日付で完成品「control_v11f1e_sd15_tile」がアップされた。v11uを利用している場合は削除&置き換えが必要。置き換えを行った場合は、「control_v11f1e_sd15_tile.yaml」も同じフォルダにダウンロードしておくこと。
できること:「画像の全体構造を維持しながら、ディティールを置き換える」ことができる、入力した画像の「詳細描き直し」とでも言うべき機能。入力した画像をタイルのように分割し、おのおののタイルの細部を高精細に置き換えてから、また元の形にくっつける。通常、これをノイズ除去強度高めで行うと、プロンプト指示がそれぞれのタイルに個別作用してイラストがバラバラになってしまう。しかし、Tileを使うとそれぞれのタイルを生成する際にプロンプトを「取捨選択」して、構図を維持しながら描き直しをしてもらえる。
{kind=link}
これは768x512サイズの画像を「Tile」と「TiledDiffusion」を併用して3072x2048サイズにアップスケールし、リッチに書き込みを増やしたもの。元画像を維持しながら、細部をほどよく無視して描きなおしていることが分かる。
難解なモデルなので、これもぜひこちらの関連記事をご参照ください。
アップスケール?描き直し?新モデル「Tile」ができること
こんばんは、スタジオ真榊です。今夜は2023年4月25日付で完成したばかりのControlnet1.1用モデル「Tile」についての報告です。Controlnet1.1で使えるものの中でもひときわ異質なこのモデル。アップスケール用なのか?それともCannyやDepthのように構図を写し取るためのものなのか?いろいろと検証してみました。 ※Contro...
{kind=link}
「なし(None)」
Shuffle、Tile、Pix2pix(ip2p.pth)はプリプロセッサがなくても機能する。外部サービスを使うなどして、プリプロセッサを使わずに抽出済み画像を用意した場合も「なし」を使うことになる。以前保存しておいた抽出データを再使用する場合も同じ。(Openpose、Normalbaeなど)
Pix2pix
{kind=link}
組み合わせるモデル:ip2p(※元画像をプリプロセッサなしで読み込ませる)
できること:通常のプロンプトとは異なる「指示プロンプト」を使い、「このイラストをこうして」と注文できる。
概要:「髪を赤くして」「彼女をカウボーイ風にして」「葛飾北斎調のイラストにして」などと指示することで、元画像に任意の変化を起こせる画期的機能。指定した場所以外にも影響が出てしまうが、上の画像のようにimage2image画面のinpaintと組み合わせて、効果が出る場所を限定(コントロール)するとよい。詳しくは関連記事を参照のこと。
▼関連記事
「Pix2pix」でイラストを変化!10種の実験で分かったこと【Controlnet1.1検証】

こんにちは、スタジオ真榊です。前回の記事に引き続き、今夜もControlnet1.1の新モデル検証の続きをお届けしたいと思います。 今回検証するのは「Pix2pix」。前回はイラストの要素をばらばらにして再構成する「Shuffle」について研究しましたが、Pix2pixは再構成ではなく「変化」を扱う新技術です。Controlnetのアップデ...
{kind=link}
終わりに
以上、モデル15種&プリプロセッサ35種にわたる長い解説となってしまいましたが、最後までお読みくださってありがとうございました。Controlnet1.1は次々にアップデートが重ねられており、各モデルも非常に多岐にわたる機能を備えているので、今後はこの記事を「ハブ」のようにして、各論に当たる個別記事を掘り下げていければと思います。
特に「Tile」はまだ2日前に公開されたばかりですので、これからどんどん研究していきたいですね。今後もこの記事は細かくアップデートしていきますので、どうぞよろしくお願いいたします!
また、先日ツイッターのフォロワーさんが1万人を超えました。すてきなお祝いイラストをくださった皆さま、本当に嬉しかったです!ありがとうございました。
この記事を読んでくださった皆様のContorolnet研究が実を結びますように。
スタジオ真榊でした。
Files