Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

レタッチ(inpaint)機能が理解る!修正&入れ替え徹底解説 (Pixiv Fanbox)
Content
こんばんは、スタジオ真榊です。今夜の記事は、image2imageを画像の一部だけに掛けて修正できる「レタッチ機能」についてです!設定値と生成結果が直感的に結びつきにくいので、みんななんとなく体感でなんとかしている(そしてたいていなんとかならない…)のが、このレタッチ機能。いろいろな実験結果と共に、ようやく理解できた設定の使い分けや活用法について紹介していければなと思います。
「レタッチ機能でこんな事ができるよ!」という動画を作ってみたので、まずはこちらをどうぞ。
この動画では、レタッチ機能を使って背景の描き直し、余計な被写体の除去、小物の置き換え、表情チェンジといった作業を行っています。誰でも再現できるように、レタッチの基本的考え方や具体的操作方法を解説していきたいと思います。AIイラストの動画化のやり方も後半に紹介します!
目次
レタッチ(inpaint)の基本
設定画面の見方
マスクされたコンテンツとは?
実験1:「マスクされたコンテンツ」比較
- 「埋める」
- 「オリジナル」
- 「潜在空間でのノイズ」
- 「潜在空間における無」
実験2:余計なものを消してみよう
実験3:色を変えてみよう
- 色替え絶対攻略法
実験4:背景を大きく変えてみよう
実験5:小物を入れ替えよう
おまけ:動画化のやり方
終わりに
レタッチ(inpaint)の基本
さて、img2imgのタブの中にある「レタッチ(inpaint)」機能は、UI画面上で黒く塗りつぶした(マスクした)部分をAIに描き直してもらうi2i機能です。通常のi2iが画面全体に及ぶのに対し、一部だけを書き換えられるのがレタッチということ。もちろん逆に「マスクした場所を残して、それ以外を書き換えてもらう」ことも可能です。
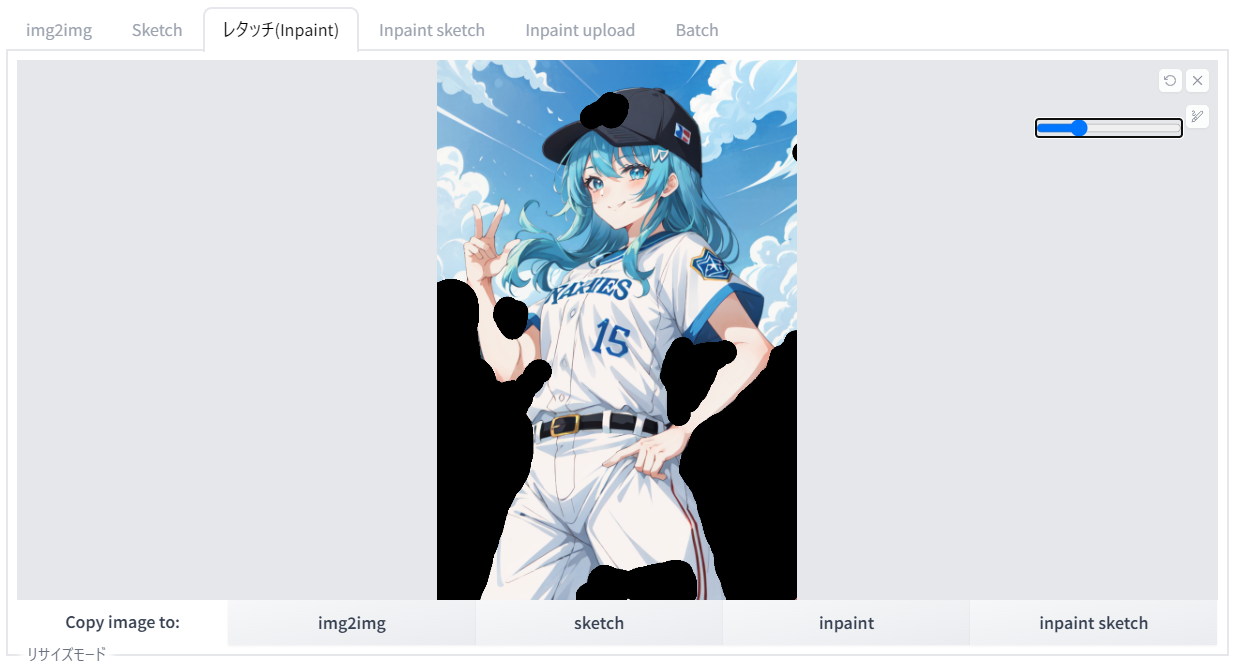
例えば、口を開けているイラストをレタッチして、閉じている形にしたい場合。まずはこうして、レタッチしたい部分をマスクで覆います。画面右上のボタンを使うと、ペンの太さを調整したり、一つ前の描き込みに戻したりすることができます。
{kind=link}
プロンプトは、元画像のプロンプトを一部書き換える(or書き足す)方法でもいいのですが、このようにごく一部だけ書き換える場合は、「2girl,maid costume,~ closed mouth」とするのではなく、プロンプト欄はシンプルに「closed mouth」のみの方がうまくいくことが多いです。なぜ「2girl」や「maid costume」といったプロンプトがないのに口の位置が破綻しないかというと、レタッチといっても本質的にはi2iですので、元のイラストからclosed mouthが描かれる位置は自然と特定されるのですね。
逆に、広い範囲をマスクして大きく描き直してもらう場合は、元のプロンプトに書き足す(書き換える)方がうまくいくようです。
{kind=link}
こちらはレタッチではなく、通常のimage2imageを使い、「closed mouth」のみのプロンプトで生成したもの。プロンプトが「closed mouth」しかないので、当然全体の絵も変わってしまっていますが、「閉じた口」の位置はあってますよね。なら、この口のところだけを切り抜いて元画像に合成しちゃえばいいじゃん!ということで、その工程を自動でやってくれるのがレタッチ機能なわけです。「元画像を複製して」「プロンプト通りにi2iして」「マスク部分にはめ込む」を一工程でやってくれる機能と考えて下さい。
基本的には「出したいもの」「変えたいもの」をプロンプトで指示するのですが、邪魔なものを消したいときにはネガティブプロンプトを使うこともできます。さっきの例で言えば、「open mouth」をネガティブ指定しても口を閉じさせられるでしょう。マスク部分だけをピンポイント修正する機能だと考えるのではなく、「これから画面全体をi2iするぞ!あとでマスク部分に合成お願いね」というマインドで臨むことがレタッチの基本です。
設定画面の見方
さて、次に設定画面の解説です。
{kind=link}
ここが本当に分かりづらいですよね。各設定が意味していることやその効果が直感的に想像できないので、生成結果にどう影響するのか分からないままに使っている(またはあきらめた)人が多いのではないかと。賢木も同じなのですが、ここからはいろいろと実験しながら体感的に分かってきたことを体系立ててお伝えしていきたいと思います。
まずは各数値の解説から。
「マスクぼかし」
マスクされた部分のふちをほどよくぼかすための機能。UI画面上では分かりませんが、数値を大きくするとマスクのブラシがスプレー状になると思ってください。0だとマスク部分の境目が目立って、レタッチ部分が周囲から浮いてしまいます。逆に大きすぎると、意図した範囲外までi2i効果が及んでしまったり、マスクしたと思ったところがしっかり覆えてなかったりするので、ほどほどの数値にしましょう。
{kind=link}
上の画像は、街の風景をマスクして室内(in door,room)に入れ替えたもの。ぼかしが小さいと、マスクの境目がはっきりして、髪の間から元の風景が見えてしまっていますね。よくわからない場合はまず4~10pixelくらいにして結果を見てみると良いでしょう。
「マスクモード」
マスクされた部分をレタッチするか、それとも逆かを選べる設定。書き換えたい場所を塗りつぶすのと、残したい場所を塗りつぶすのと、どっちが塗りやすいかで使い分けましょう。
「画像を修正する範囲」
・「全体像」とすると、元画像全体をプロンプトに従ってi2iした上で、元画像にマスク部分だけを合成してくれる。直感的に何が起こるかわかりやすく、崩壊しにくいので、こちらが基本。
・「マスクのみ」にすると、マスク部分のみをまず指定のキャンバスサイズにクローズアップしてプロンプト通りに描いた後、元のサイズに縮小するという特殊なやり方になる(下画像参照)。拡大してからi2iするので、マスク部分が高画質になるものの、周囲となじまないこともあるので中・上級者向け。キャラの顔のクオリティーアップや、遠景にある被写体の破綻修正などに使える。ノイズ除去強度が強いと破綻するので注意。
{kind=link}
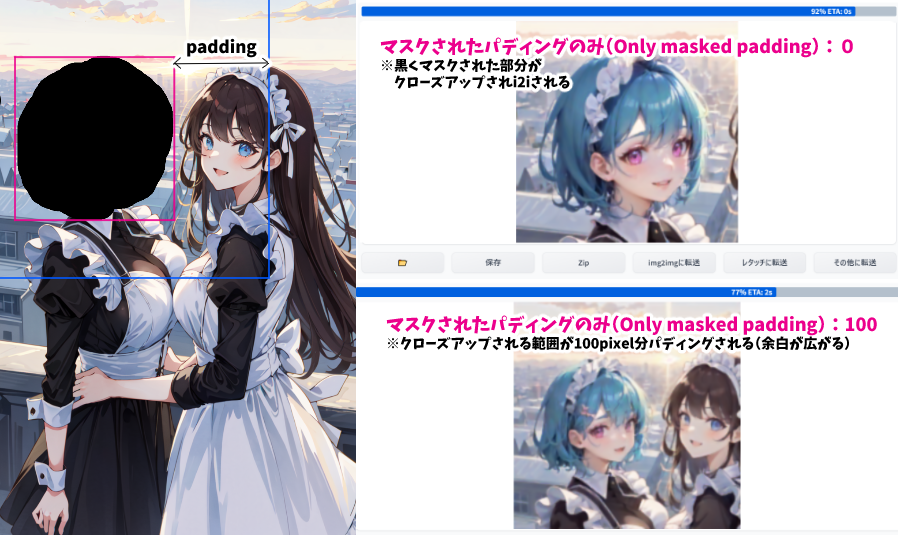
「マスクされたパディングのみ(Only masked padding)」
マスクモードを「マスクのみ」にしたとき、どれくらいクローズアップしてからi2iするかを決めるためのスライダー。「0」にするとマスク部分を一番小さく囲う四角形にクローズアップされる(▽下図・ピンクの四角)が、高い数値にするとその四角形の周囲に余白(パディング)が追加される(▽下図・青の四角)ため、より広い範囲を参照してAIがお絵かきできるようになる(▽画像右下)
{kind=link}
差し替え用のクローズアップ画像は、最終的にはマスクの形に切り取られてはめ込み合成されるので、このスライダーを0にしても100にしても、黒髪の女の子の顔などが書き換えられることはありません。では何のためにある設定かというと、あまりクローズアップしすぎると何が描いてあるのかAIが理解できず、上手にi2iできないケースがあるため。「差し替え用の画像は視野を広く持って描いてね」と頼みたいときに、Only masked paddingを広げましょう。
「ノイズ除去強度」…通常のimg2imgと同じで、プロンプトによる修正と元画像のどちらを重視するかのパーセンテージと考えましょう。1.0だとマスク周辺との調和を考えずにプロンプト重視でレタッチする。0だと元画像と同じものが出る。0.5だとマスク周辺と調和を考えつつ、プロンプトもできるだけ再現できるように頑張ってくれる。大きく書き換えるなら強めにするが、プロンプトによっては元画像と位置がずれて見当違いの画像が生成されてしまうので注意。ノイズ除去強度を強くしつつ崩壊を防ぐには、ControlnetのCannyを使おう。
「リサイズモード」「幅」「高さ」・・・レタッチする際にキャンバスサイズを変えることもできます。元画像と同じ比率であればそのまま拡大縮小されますし、比率が異なる場合は「リサイズモード」の指定を参照して処理結果が決まります。慣れてくると、レタッチと同時にアップスケールすることもできます。
====================================
…と、ここまではおおむね理解できるんじゃないでしょうか。
問題はこれです。「マスクされたコンテンツ」。
マスクされたコンテンツとは?
「今から追いつく!AIイラスト超入門」でも書いた通り、画像生成AIは無数の教師データからの深層学習によって、無意味なノイズから「存在しない元画像」を想像してノイズを除去し、この世に存在しない画像を出力する仕組みです。i2iの場合はノイズではなく、入力した画像を基にノイズ除去を始めるため、構図の似た画像を出力できるわけですね。「マスクされたコンテンツ」という設定項目は要するに、マスクで塗りつぶされたところをこれからi2iで修正するにあたって、ノイズからスタートするか、もとの画像からスタートするか、塗りつぶしや「無」からスタートするか選びなさい、ということです。
StableDiffusionWebUIの公式解説を見るとイメージが分かりやすいです。
{kind=link}
(https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
よりスクリーンショットで引用)
意味のないノイズからプロンプトによって画像生成するのがt2iの仕組みなら、指定画像を基に生成するのがi2i。これを踏まえて上の画像を見ますと、要するに、「オリジナル」でレタッチするときに起きる現象は、通常のi2iと同じなわけです。元画像に描かれているものや色を手がかりに、新しいプロンプトを参照してi2iしているだけです。「潜在ノイズ」なら、ノイズからプロンプトに従って画像生成するわけですから、マスク部分で起きる現象はよりt2iに近い現象になります。元画像の色などに引きずられにくくなり、よりプロンプト通りのものを描けるので、大きく絵柄を変えたいなら「オリジナル」より「潜在ノイズ」を選ぶことになります。
埋める(=周囲の色で塗りつぶし)はそこにもともと描かれていたものを強くぼかした上でi2iするイメージなので、余計なものを消して周囲になじませるときに有効そうです。「無」は、周囲の色にひきずられずに大きく描き直したいときに使うのでしょうか?
ここまではなんとなく想像できるのですが、実際に生成結果がどう変わるのかが分かりにくいですね。そこで、いろいろと実験を行ってみました。
実験1:「マスクされたコンテンツ」比較
{kind=link}
こちらが元画像。これをレタッチして、口を閉じさせてみましょう。プロンプトは「closed mouth」のみ。ノイズ除去強度の影響がどれくらいあるのか、そして「マスクされたコンテンツ」によってそれがどう変わるのかを調べてみます。マスクぼかし
は「32pixel」、サンプリング回数は「25回」に固定して実験しました。(ほかの設定値は元画像のt2i生成時と同じ)
「埋める」
{kind=link}
「埋める✕0.1」のみ、周囲に調和する色で塗りつぶして、そこからノイズを除去しきれなかった感じが残っています。よく見ると、金髪の子の口の左側が他の部位より露出していますね。マスクした範囲が口元だけで小さいのに、マスクぼかしが32pixelと大きすぎたため、ふちがスプレー状になって口全体をマスクしきれていなかったことが分かります。
0.3以降は概ね閉じられていて、かつ数値が上がるごとに笑顔になってますね。ただ、金髪の子の口の左側はマスクしきれなかった部分の名残で、口が閉じきれていないものが多いように見えます。
「オリジナル」
{kind=link}
「オリジナル✕0.1」は、ほぼ、口を開けた元のイラストそのものという感じ。0.5で閉じましたが、0.7以降は金髪の子が再び口を開ける結果に。元画像が口を開いた状態なので、それが引き継がれてしまったのでしょう。元画像の色や形に引っ張られず大きく描き直したい場合は、「オリジナル」を使わないほうがよいことが分かります。
【ちょっと脱線】
昔書いたNovelAIの解説記事「顔だけ変えたい!表情差分を作る方法」では、NovelAIにこうしたレタッチ機能がないために、元画像の表情にガウスぼかしをかけてi2iするという苦肉の方法を紹介していました。そうしないと元画像の表情に引っ張られてしまい、うまく別の表情に差し替えられないからですが、webUIのレタッチにおける「オリジナル」でもそれと同じことが起きていることがわかります。元画像の描写に引っ張られたくなければ、ぼかしを掛けるか「無」で塗りつぶすかノイズから再出発するしかないよね、ということです。
潜在空間でのノイズ
{kind=link}
0.5まではノイズが残ってしまい、使い物にならない感じ。0.7からはノイズが除去されて、それ以降は特に変化がないようです。
潜在空間における無
{kind=link}
0.3までは「無」で塗りつぶされたままという感じ。0.5以降は形になりました。前の子はきれいに閉じていますが、後ろの子はわずかに口が開いているイラストも混じっています。「無✕0.5」は一番いい生成結果のように見えます。
仮説を立ててみる
これらの結果から立てられる仮説は、
・ノイズ除去強度が弱いと完成前の状態で出力されてしまうので、基本的に0.5以上が無難。ステップ数もある程度多くしないとダメそう
・「埋める」にするとノイズ除去強度によって生成結果が変わるが、ほかは余り変わらなかった
・「オリジナル」にすると元画像の影響が残るので、大きく描き直したい場合は「埋める」や「潜在空間でのノイズ」「無」にしてしまった方が良さそう
・マスクぼかしを大きくしすぎてうまく元画像が覆えていないと、期待した結果にならない
というところ。これらを踏まえて、別の実験をしてみます。
実験2:余計なものを消してみよう
次はこれらの仮説を基に、「埋める」で余計なものを消す実験をしてみましょう。
{kind=link}
こちらの指三本お姉さんの中指?薬指?を消してみます。
{kind=link}
「オリジナル」にすると元の指を参照してまた6本目の指が書き直されてしまうので、さきほどの考察を踏まえて「埋める」にしてみました。すると、
{kind=link}
ちょっと根本が変ではありますが、割ときれいに消えました。プロンプトは「peace sign」のみ。ディティールのおかしさはアップスケールするときになじませられるので、これくらい綺麗になっていれば十分です。余計な指以外にも、写り込んだ邪魔ものはたいてい「埋める」でうまく消せます。
実験3:色を変えてみよう
{kind=link}
さきほどの青い髪のメイドさんをピンク色の髪に変える実験です。i2iは基本「色」に注目して対象を書き換えるので、目の色くらいなら変えられても、髪の毛のように広い範囲を違う色に変えるのはかなり苦手。青がピンクに変わるほど強く掛けると、それ以外の部分も元画像からかけ離れてしまう恐れがありますが、どうなるでしょうか。
設定は「全体像」✕「元画像と同Scale」「同Step」「同seed」で、同じプロンプトの冒頭に(pink short hair:1.3)を加えました。
①埋める
{kind=link}
0.5は継ぎ目がうまくいったが、ノイズ除去強度が足りずピンク髪にならない。0.7以降はノイズ除去強度が強すぎて、ピンク髪にはなったがうまく合成できない。
②オリジナル
{kind=link}
0.7まではオリジナルの青い髪の印象が強すぎて、ピンク髪にできない。0.9でピンクになったものの、できたものは「①埋める」とほぼ同じアンバランスな結果に。
③潜在空間でのノイズ
{kind=link}
i2iよりt2iに近い「ノイズ」を試す。0.5まではノイズが残ったが、0.7で奇跡のバランスが成立した。0.9以降はほぼこれまでと同じ結果。
④潜在空間における「無」
{kind=link}
「無」はノイズとほぼ同じ結果になった。0.7が奇跡のバランスで、それ以上はこれまでとほとんど同じものができる。
色替え絶対攻略法
今回はたまたま「ノイズ」と「無」の0.7が正解だったわけですが、実践でこんなに何度も実験を繰り返していたら途中で心が折れてしまうでしょう。なんとか元の形を保ちながら、確実に色だけ変える方法はないでしょうか?
そう、Controlnetを使えばいいんですね。
{kind=link}
これはControlnetのCannyで輪郭を強調しつつ、「全体像」✕「潜在空間におけるノイズ」✕「ノイズ除去強度1.0」で赤髪に変えたところ。強度1.0だと普通は崩壊してしまうところを、Cannyによる輪郭保持力で狙い通りの結果を出しています。
これを応用すれば、赤髪にしながら髪型すら変えることもできます。
{kind=link}
こちらは左の子を「red long hair」に変えたところ。後ろ髪が通りそうなところを広くマスクした上で、「Canny」で抽出した線画をクリスタで取り込み、白いペンで後ろ髪を描き直しました。これをpreprosessor:noneで取り込んで出来たのが最後の1枚。しっかり左の子だけを赤いロングヘアに変えることができました。
よくみると右手のカフスが2つあったり、黒髪の子の左手がちょっと変だったりするので、そこをレタッチで修正します。カフスを消すには「埋める」、左手修正には「オリジナル」を使いました。
{kind=link}
これをさらにi2iして好みの感じにアップスケールすると…
{kind=link}
不自然なポイントもうまく馴染ませることができました。
このように、形はそのままで色だけ変えたい場合はControlnetを併用すれば、何回も実験を繰り返さなくても望み通りの結果を得ることが可能になります。レタッチとControlnet、とりわけCannyは最強のコンビですね。
実験4:背景を大きく変えてみよう
今度はこちらの野球娘さんのイラストをレタッチしてみます。冒頭で紹介した動画作品に使ったイラストですね。実は他にもたくさん野球娘さんを生成したのですが、この娘が一番ボールを持たせたくなる手をしていたので、このイラストをレタッチすることにしました。
{kind=link}
修正したいポイントがいくつもありますね。バッグ2つが邪魔なのと、スタジアムの屋根のラインが左右でつながっていません。ついでに、帽子とひざのマークもなんだかイメージと違うので、消せるかどうか試してみましょう。
{kind=link}
このように、関与する部分を大きめに塗りつぶします。股や腕の間にもスタジアムがわずかに写り込んでいるので、ここにもマスクするのを忘れないようにしましょう。
プロンプトは「baseball stadium,clowd,simple black cap」とします。これは元画像をイメージせず大きく描き直してもらいたいので、「潜在空間でのノイズ」を選びます。「オリジナル」にすると元のバッグがまた描かれてしまうからです。
{kind=link}
大きくスタジアムが描き直されました。帽子やひざのマークも消したかったのですが、別のものに差し替わっただけでうまく消えませんでしたね。
実験5:小物を入れ替えよう
今度はひざの刺繍を消しつつ、帽子もユニフォームの色と同じ白に変えてみます。髪の毛の「W」型のヘアピンも消したいので、ネガティブに「hair pin,hair ornament」を加えます。刺繍やヘアピンは「埋める」で消し、帽子は「white baseball cap」というプロンプトを加えて、「潜在空間でのノイズ」で描きなおしてもらいます。
塗りつぶすときは帽子だけを綺麗に塗りつぶすのではなく、おおまか・大きめ・ざっくりと周囲を塗った方がうまくいくようです。周囲に描いてあるものと馴染むように描いてもらわないといけないので、境界線がはっきりするような縁取りの仕方は逆効果になるためです。
{kind=link}
かなりイメージ通りに寄ってきました。よく見ると、腰の左側のふちが空色が写り込んで青く塗られてしまったり、前髪に帽子の名残があったりするのですが、こうしたディティールのミスはアップスケールによってなじませることができます。この画像は現在1152✕768pixelなので、i2iで2048✕1360pixelにアップスケールします。ノイズ除去強度を0.5とそこそこ強めに掛けることで、不自然な部分が残らないようにしましょう。
{kind=link}
強く掛けることで全く違う絵になってしまうのを防ぐため、さきほどと同様にControlnetのCanny(▲)を使い、輪郭の崩壊を防ぎながらアップスケールすることにします。
→「超革命!Multi Controlnetでできるようになったこと」参照。「正確性と緻密さを兼ね備えたアップスケール」という項目で、controlnetで構図を維持しながらアップスケールする方法を解説しています。
{kind=link}
元画像の輪郭をしっかりと保持しながら、細部をアップスケールできました。前髪の不自然なポイントや、ズボンの青染みが消えているのが分かるでしょうか。あとは、右手に野球のボール⚾を持たせたいですね!
手を塗りつぶして「holding baseball ball」のプロンプトでレタッチしてみたのですが、AIはあまり野球のボールの再現がうまくなく、変な縫い目の球体ばかり出たのでレタッチは断念。今回はフリー素材のボールイラストを「illustAC」からお借りして合成してしまいます。ボールの影を入れ、縁取りを書き、細部を調整して文字入れをしたら…
{kind=link}
完成です!
おまけ:動画化のやり方
冒頭に紹介したツイートのように、AIイラストを動画化をする方法も解説しておきます。あの動画は「Screen to GIF」というフリーソフトを使って、クリスタの画面をキャプチャした後、スマホの動画編集アプリ「VLLO」でエフェクトや音楽を合成しています。つまり、切り替わる順に画像をレイヤーで重ねておいて、録画ボタンを押したら一生懸命消しゴムで消したり、レイヤーを紙芝居みたいに切り替えたりして「GIFを撮ってる」んですね(笑)
{kind=link}
▲クリスタのレイヤー図
Screen to GIFの使い方については、「シーンデータをGIF動画にする方法」という記事で解説しているので、ご参考まで。AIイラストではなくコイカツのキャプチャのやり方ですが、やることはほぼ同じです。失敗したら撮り直せますし、コマを複製したりカットしたりして「後から修正」もできるので、根気さえあれば誰でもイラストAI動画作品が作れますよ!
{kind=link}
こちらがVLLOの画面。かんたんな操作でGIF動画に音やエフェクトをつけられます。テンプレート」というのの中にキラキラエフェクトやじゃーんと光が飛び出すエフェクトが入っているので、GIFのタイミングに合わせてタイムラインに載せ、長さを調整するだけ。他にもさまざまな音楽や効果音が用意されており、字幕や図形を入れたり、自分の声を吹き込むことも可能です。ここまでやってしまうと、もはやクリエイターみたいですね笑
終わりに
そんなわけで、非常に長くなりましたがレタッチ機能の解説記事でした。マスクされたコンテンツの意味と、マスクぼかしのサイズに気をつけることだけ分かれば、かなり自由にレタッチができるようになるので、ぜひいろいろ試してみてください!
このところ、先日公開した記事「今から追いつく!AIイラスト超入門」が本当にたくさんの方に読んでいただけて、すごく喜んでいます。ツイッターのフォロワーさんも1000人単位で増えましたし、応援のコメントもたくさん頂けて、社畜生活の合間に夜なべして頑張った甲斐がありました。記事をリツイートしてくださったり、温かいコメントをくださったりした皆様のおかげです。ありがとうございました。
{kind=link}
特に、はてなブログのトップページに記事が載ったのはびっくりしました。一生懸命やっていると、たまには人生いいことがあるものですね。
それでは皆様、素晴らしきレタッチ生活を!
スタジオ真榊でした。
Files