Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

超革命!「Multi Controlnet」でできるようになったこと (Pixiv Fanbox)
Content
こんばんは、スタジオ真榊です。前回は「Segmentation」を使った構図コントロールのやり方について紹介しましたが、今夜は「canny」や「depth」なども含め、最新のControlNetをフルに使うと何が可能になるのかについて、かなり長文で取り上げていきたいと思います。久々の大型記事ですね!
ControlNetをめぐっては、「Controlnet徹底解説!プロンプト苦難の時代が終わる…」で紹介して以降も、日々精力的なアップデートが続いています。特に界隈で話題なのが「Multi Controlnet」ですよね。これ、同時に複数の抽出機能を使ってイラストを生成できる技術なのですが、本当にヤバイ聖杯中の聖杯です。触ったばかりだと「何に使えるのか分からない」「何と何をどう組み合わせればいいのか分からない」状態に陥りますが、使い方さえわかればAIと一気に仲良しになれます!
短期間に異次元の進化を遂げたControlnetで、具体的にどんなことが可能になったのか。さっそく見ていきましょう~!
Multi controlNetの登場
{kind=link}
2023年2月22日に追加された拡張機能「Multi ControlNet」は、複数のcontrolnet機能を同時に発動させて画像生成ができる革新的なアップデートです。text2imageだけでなく、image2imageの際も使うことができます。例えば、「Depth+Openpose」や、「segmentation+canny」、「canny+canny」といった組み合わせによって、複数のイラストからキャラクターを一つのイラストに呼び出したり、構図を完全に固定して各要素だけを入れ替えたり、キャラクタ-はそのままに背景だけを差し替えるようなことが可能になります。
起動方法
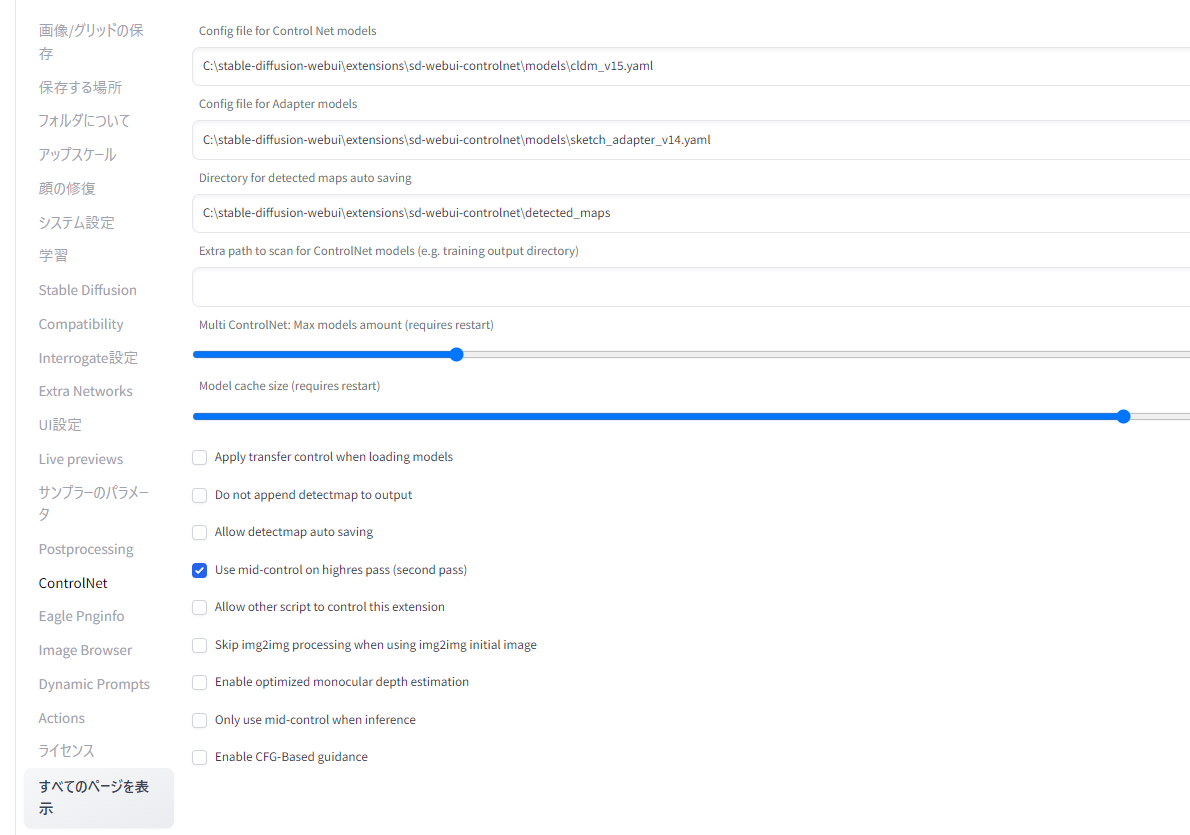
Multi controlnetを使えるようにするには、WebUIの設定タブのControlnetのタブを開き、「Multi ControlNet: Max models amount (requires restart)」のつまみを「2」以上にすればOK。t2iなど通常の生成画面に「Control model-0」「Control model-1」「Control model-2」…と、Controlnetの操作タブがその数だけ表示されるようになります。複数のControlnetを使用するときは、それぞれの操作画面の「Enable(有効)」をオンにすることを忘れないようにしてください。
設定画面につまみがない場合は、拡張機能のタブからControlnetを最新版にアップデートする必要があります。アップデート後は「UIの再読み込み」ではなく、WebUI自体を再起動しないと反映されないのでご注意ください。
{kind=link}
▲設定画面のつまみ
と、ここでちょっと脱線。Multi Controlnetの説明に入る前に、アプデで追加されたり、これまで説明していなかったControlnet機能についてざっと紹介しておきます。ちなみに、以前は縦に「Control model-0」「Control model-1」...と操作画面が並んでいたのですが、アップデートでタブごとに分けられるようになりました。Ctrl+Vでの画像貼り付けがミスしにくくなったので大変ありがたい!
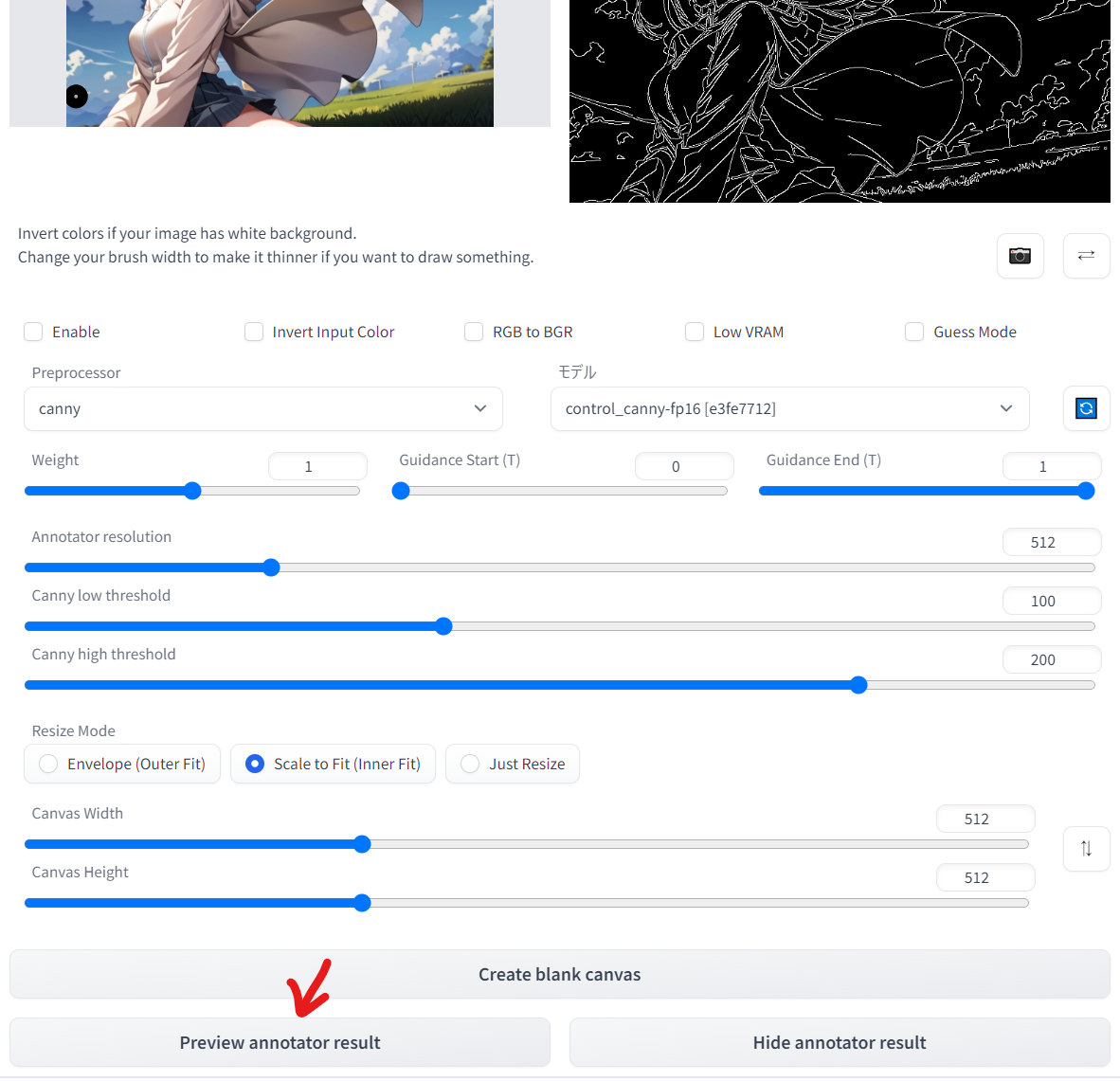
「preview annotator resultボタン」の実装
アップデートにより、controlnetの操作画面下部に「preview annotator result(抽出結果を見る)」「hide annotator result(抽出結果を非表示にする)」というボタンが追加されています。このボタンにより、いちいち画像生成の結果を待たなくても、参照画像からどのような情報が抽出されるのか事前に確かめることができるようになりました。
{kind=link}
ココです
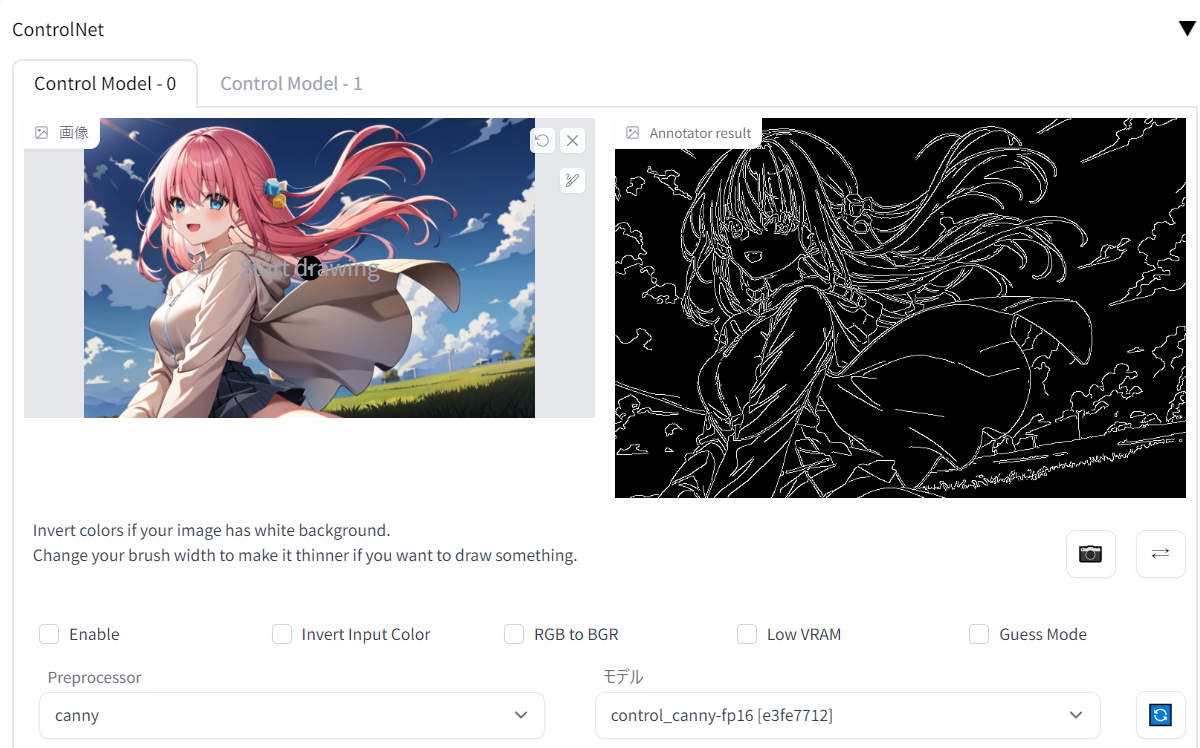
「Annotator resolution」などの値を動かしてもう一度「preview annotator result」を押すことで、白黒画像の抽出処理を調節することができるようになっています。表示された白黒画像を右クリックでダウンロードしたり、別のControlnet画面にそのままドラッグすることも可能。もちろんCanny以外の抽出機能でも同様のことができるので、いろんな設定を試してどんどん活用していきましょう。
抽出データ画像を保存しよう
{kind=link}
controlnet機能で抽出したデータ画像はUI画面上には表示されるものの、Outputなどのフォルダには自動保存されません。生成結果から右クリック保存することもできますが、ついつい忘れてしまうことも多く、「あのとき抽出したボーンを保存しておけばよかったなあ」と思う場面もあったと思います。
そうした場合はWebUIの設定タブから「ControlNet」を開き、「Allow detectmap auto saving」にチェックを入れてみましょう。これ以降、controlnetのpreprocessor(前処理)で抽出されたボーン(棒人間)やCannyの輪郭、depth情報といった画像が自動保存されるようになります。保存先はデフォルト設定だと「stable-diffusion-webui\extensions\sd-webui-controlnet\detected_maps」。設定画面の「Directory for detected maps auto saving」の欄で自由に設定できます。
※画像生成終了時に保存されるので、「preview annotator result」で表示しただけではフォルダに残りません
プロンプトいらず?「Guessモード」
{kind=link}
「Guess Mode(推測モード)」というボタンも追加されています。これは「非プロンプトモード」のような機能で、プロンプト欄に何も描き込まずとも、参照画像から抽出された情報に最大限注目して同様のものを自由に描くようAIに指示するモード。例えば、プロンプト欄がブランク(空白)の状態で観覧車の写真を「Canny」で読み込ませると、AIはその輪郭から「これは観覧車だろう」と自分で推測して、観覧車を描くことができます。逆に何が描かれているか特定できない輪郭やdepth状態を読み込ませると、AIはそこから連想できるさまざまなものを描き出します。
ただ、これはまだ実験中の機能のようで、期待通りに動かないことも多いです。どういうものなのかだけ理解しておけばOKというところでしょうか。ちなみに、Multi controlnetが発動している場合はどれか一つの画面でGuessモードがONになると、全てのControlnetにその効果が及ぶとのことです。
Guidance Start/Endで何ができる?
{kind=link}
Guidance StartとGuidance Endという設定値も追加されました。これは、「Enable」にしたControlnetの影響が画像生成のどのステップから及ぶかを示すもの。基本は0でスタート、1でエンドということで、ノイズ状態から生成終了まで全ステップに影響しますが、例えばスタートを0.8にすることで、全体の80%に当たるステップ数から影響が出始めます。(画像生成の最後の20%だけ影響するという意味)
この機能は、例えば「画像の細部に対して強力にControlnetを影響させたいが、全体の絵作りにまで影響はさせたくないときに、生成途中から影響をStartさせる」ために使うことができます。例えば、手の形だけを描いたCannyを影響させて正しい手のイラストを生成したいけれど、最初からそのCannyを読みこませると「手しかないイラスト」ができてしまうようなときに、この機能を使って調整することになります。
Multi Controlnetで何ができるのか?
さて、本題に戻りましょう。「なんかすごそう!でも具体的に何ができるの?」と思ってしまうMulti controlnet機能ですが、実用性があると感じられたいくつかの活用法を紹介していきます。
何ができるかの前に、前提として説明したいのが、「何ができないのか」。例えば、次のような背景のみの画像とキャラクターのみの画像を用意して、いずれもCannyで輪郭を抜いて合成しようと試みたとします。何が起きるでしょうか?
{kind=link}
生成結果はこちら。
{kind=link}
背景に観覧車、手前にキャラクターが来てくれればよかったのですが、それぞれの輪郭が一つに溶け合ってしまって、AIが何を描けばいいのか混乱していることが分かります。
これはもちろん、観覧車の輪郭とキャラクターの輪郭両方が重ね合わされた状態で生成されてしまったからですね。つまり、AIとB別々の要素を同居させたい場合に特に注意しないといけないのが、「別々の被写体の抽出位置が重なると失敗する」ということです。
{kind=link}
こちらはキャラクターの「Depth」と、さきほどの観覧車の「Canny」を重ねたもの。こちらはなぜ失敗したのかがより分かりやすいですね。キャラクターと観覧車の情報が溶け合ってしまい、完全に抽象画と化してしまっています。
では、Muliti controlnetが得意なことは何なのか。複数のControlnetを組み合わせて何ができるのか。いろいろと試して分かったのは、
【Ⅰ】A要素とB要素が同じものを「別の表現で」指示する場合
【Ⅱ】A要素とB要素が別のものだが、画面上で干渉しない場合
この2つの条件下でなら、Multi Controlnetは真価を発揮します。順番に見ていきましょう。
【Ⅰ】別の表現で同じものを指示
①A要素とB要素が同じものを「別の表現で」指示している・・・というのは、例えば参照画像が全く同じで、segmentationとdepthの双方で似た画像の生成を指示するような場合です。
こちらのイラストをご覧ください。
{kind=link}
Segmentationを使って、キャラクターのシルエットと背景に描かれているものを抜き出したものです。このままsegmentation単独で画像生成すると…
{kind=link}
シルエットの中にどのように四肢が配置されるのか、AIが迷っているのが分かると思います。脚が3本になってしまったり、脚が来て欲しいところにリボンが配置されてしまったり。こうした誤解を解くために、Multi Controlnetを使ってもう一つControlnet操作画面を開きます。Segmentationに加えて、「depth」を同時に作用させてみましょう。
「segmentation+depth」
{kind=link}
右側の白黒画像がdepthによる抽出結果。これによって、シルエット内にキャラクターの四肢やスカートがどのように配置されるのかが明確に指示されました。depthは色が濃い(白い)部分ほど手前にあることを示していますので、例えば左足については、「膝が手前側に、足先(靴)は画面奥にある」とAIは理解してくれます。
画像生成してみると…
{kind=link}
さきほどはイラストごとにバラバラだったポージングを、参照元画像と同じにすることができました! これまではプロンプトかi2iで運任せにするしかなかった「ヒトと生成AIの不自由な関係」ですが、Controlnetという通訳の登場によって大きく改善されたことが分かります。
では、この技術は具体的にどんな場面で活かせるのでしょうか。
①新次元のバリエーションガチャ
{kind=link}
まず、構図を固定してさまざまなバリエーションをガチャできるようになります。このウェディングドレス画像も、さきほどのフィギュアスケートと同様に、構図をしっかり固定しながらいろんなウェディングドレスを描いてもらったものです。
これまでは、あるプロンプトで良い画像が出ても、手や細部が崩壊しているとか、印象が異なるといった場合は、Seed値を固定してちょっとずつプロンプトを変えたり、variation機能を使って類似画像の可能性を追ったりすることしかできませんでした。ところが、この「segmentation+depth」を使えば、気に入った画像の構図をしっかりと維持しながら、キャラクターの容姿や背景の様子、露光やタッチなどをプロンプトで大胆に操作することができるようになります。「プロンプトや各種設定を書き換えると構図自体が大きく変わってしまう」という懸念をこれで克服できるということですね。
②正確性と緻密さを兼ね備えたアップスケール
構図を維持しながら細部を変更する「ガチャ」だけでなく、構図を強力に固定して強strengthのアップスケールを掛けることもできます。
前回の記事で、こんなくだりがありました。
{kind=link}
「segmentation機能を使ってせっかく目当ての構図(▲)を出せたのに、人物が小さすぎてアップにすると破綻している」+「かといって人物がきれいに見えるほど強Strengthでhiresしたりアップスケールi2iすると、別の部分まで違うイラストに書き換えられてしまう」…
これを解決するのが、Multi Controlnetを使ったアップスケール方法です。
{kind=link}
こちらの画像(▲)をできるだけそのまま維持して、人物部分がまともに見えるようにアップスケールするにはどうしたらいいでしょうか。さきほどは「segmentation+depth」を使いましたが、今度は「segmentation+normalmap」を使ってみましょう。2種類のcontrolnetによる強力な干渉で、家具の配置や人物の特徴はそのままに、i2iで幅2048ピクセルまで大胆に引き上げてみます。
{kind=link}
上から「i2i元の画像」「i2i元の画像を作るために作ったsegmentation」「i2i元のnormalmap」です。これらが融合してできたのがこちら。
{kind=link}
いかがでしょうか。元画像の印象をほとんど変えずに、キャラクターのアップスケールに成功していると思います。i2iで大きくサイズアップを図ると、どうしても元画像からの乖離が目立つのですが、Controlnetで構図を維持することで思い切ったクォリティーアップが図れるようになるわけです。
【Ⅱ】A要素とB要素を画面上で競合させない方法
さて、ここまで見てきたのは、複数のControlnetを使って同じ絵柄を指定する方法でした。フィギュアのイラストも、リビングのイラストも、2つのcontrolnetが同じものを違う方法で指定していましたね。これなら最初の観覧車のイラストのような競合は起きないのですが、今度は「A要素とB要素が別のものだが、画面上で競合しない場合」の活用方法を見ていきましょう。
別々のイラストをControlnetで読み込んで1つのイラストにできるということであれば、つまりは「2つの画像から『いいとこ取り』ができる」ということ。特に背景とキャラの画像を簡単に組み合わせることができるとなれば、より自分の想定している画作りができることになります。でも、どうやったらさきほどの「観覧車人間」のような失敗をせずに生成できるでしょうか。
まず思いつくのは、指定した要素が「キャンバス上で重なり合わない位置にある」場合です。
{kind=link}
画像引用:https://github.com/Mikubill/sd-webui-controlnet
これは「Canny+Canny」とでも言うべき合成方法ですね。観覧車+人間の実験では、輪郭線がもろに重なってしまったために「観覧車人間」ができあがりましたが、こちらは2つのcannyの被写体がそれぞれ重なり合わない位置にあるので、ごく自然に混ぜ合うことができています。背景はcanny情報にはありませんが、プロンプトで指示したものなのでしょう。
でも、これならわざわざMulticontrolnetを使わなくても、ソースAとソースBを画像編集ソフトで1枚にして、単一のCannyとして生成しても結果は同じです。もっとMulti controlnetならではの活用方法はないのでしょうか。
「Segmentation+Openpose」
代表的な活用方法の一つが、「Segmentation+Openpose」によって、既存の画像に人物を挿入する合成方法です。こちらのツイートがその例。
手順は簡単。見本画像からSegmentationで抜き出した塗り絵を「OpenposeEditor」の「Add Background image」機能で背景にし、ソファの上にボーンを座らせます。
{kind=link}
(イメージ▲ 生成に使う実際のpngは黒背景)
できたボーン画像をOpenposeで読み込み、もう一つのControlnet操作パネルで無人の部屋のSegmentationを組み合わせればOK(どちらも既に抽出済みなのでpreprosessorはオフにします)。
Segmentationの塗り絵の中に「Person」を示す部分がなくても、AIはOpenposeの指示とプロンプトにある「1girl sitting on sofa」の意図を読み取って、「塗り絵には描かれてないけど、ここに人物を描けばいいのね」と理解してくれます。うまくいかない場合はWeightを調整しましょう。前回の記事ではSegmentationの塗り絵をペイントソフトで書き加える方法を紹介しましたが、この方法でペイントソフトを使わなくても人物を挿入することができます。
他にもまだある「魔法のような使い方」
「背景にキャラを加える」なんていうのはまだまだMulti Controlnetの序の口です。他にもさまざまな組み合わせをすることで、魔法のようなイラスト生成が可能になります。
{kind=link}
例えばこちらの「Scribble+Openpose」の組み合わせでは、自分で描いたトンチキなラフにどのようなポーズを意図しているかをopenposeで「念押し」することができます。自分で描かず既存イラストのおおまかな構図を利用したい場合は「Fake Scribble+Openpose」の組み合わせ。「元イラストのおおまかな輪郭を強力に指示」しつつ、プロンプトによってその他の要素を強く動かすことができるようになりますね。
{kind=link}
こちらは「Canny+Segmentation」。まずはさきほど作った白背景のイラストをCannyで読み込み、左下と頭部の異物をペイントソフトで消し、ついでに顔も塗りつぶします。今度は同じイラストをSegmentationで読み込んだ後、クリスタで人物部分のみを別レイヤーに抜き出し、背景をペイントソフトで空色とビル色と床色で塗りつぶし。元イラストの輪郭を維持したまま、背景を描き足してもらいつつ、大幅にアップスケールしました。つまり最後のイラストは「Scribble+Openpose+Canny+Segmentation」で作られたことになりますね。
この「Canny+segmentation」は、線画着色にも使える組み合わせ。自分で人物の線画を描ける場合は、それを事前処理なしのcannyで直接読み込んで、背景に描いてほしい要素をsegmentationで指定すればOKです。自分では線画しか描いていなくても、skyやriverを意味する色で背景を細かく指定できるので、「自分の線」をしっかりと維持しながら「おおまかにこのへんにこれを描いて」と指示することができます。自分の絵をAIに着色させ、背景までお任せで描いてもらうという夢のような使い方で、まさにAIアシスタント時代の到来ですね。主線を自分で描けるわけですから、「masterpiece顔」からの完全脱却が可能になるわけです。
他にも、先程の犬画像のように「Canny+Canny」で別々のイラストのキャラクターを一つのキャンバスに取り込んだり、「Canny+depth」を使って崩壊した手を強制的に直したり、「i2iレタッチ+Canny+Segmentation」で健全絵のNSFW差分を作ったりすることも可能です。これらの手法はここに書ききれないので、今後個別記事で一つ一つ解説したいと思います。
終わりに
Controlnetをうまく使うコツは、どうやら「これが譲れない要素だよ」とAIに教えてあげることのようです。譲れない要素がキャラクターのポーズなのか、背景の配置なのか、むしろキャラクターは固定しないでほしいのか。こちらのニーズによって、使う機能を使い分けるのがポイントです。
いろいろと複雑なようにも見えますが、要するに「ここにこれを必ず描いてね。それ以外はプロンプトに書いたことを参照して自由に描いてね」というのが、Multi Controlnetでできること。うまくいかないときはControlnetのWeightをうまく折り合いがつくように操作してあげると良い結果が出るようです。
Controlnetは研究して研究してようやく分かってきたら、アップデートでさらにできることが増えるという狂気の世界に突入していますが、明らかに人類の革新を感じる超技術ですね。今後もどんどん組み合わせと活用方法を紹介していきますので、今月もどうぞよろしくお願いします。
それでは皆様、素晴らしきControlライフを!スタジオ真榊でした。
Files