Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

ControlNet徹底解説!プロンプト苦難の時代が終わる… (Pixiv Fanbox)
Content
こんにちは、スタジオ真榊です。ここ数日はこの話題でもちきりですね。そう、拡張機能「ControlNet」の衝撃的デビューで、プロンプトやi2iでポーズや構図をなんとか表現しようと苦心していた時代は過去のものになりました。
Controlnetは、参照画像からキャラクターの四肢のボーンやイラストの主線、depth(深度情報)などさまざまな情報を抽出し、イラストのポーズや構図を自由に制御できる革新的な拡張機能です。2023年2月10日に論文が投稿されるや、わずか数日でStable Diffusion用WebUI向けの拡張機能が登場。当初は1つ5GB超えのモデルを8つダウンロードしなくてはなりませんでしたが、あっという間に一つ約700MB程度に圧縮され、容易に導入できるようになってしまいました。
単に構図やポーズを指定するだけでなく、イラストの主線や輪郭を保存して新たにイラストを生成しなおすことすら可能になったため、線画の着色やマウスで描いた落書きからのいきなり完成イラスト生成といったi2iではできなかったことが次々にできるようになっています。まさに革命!
さっそく今回は導入方法の解説とともに、各学習モデルの違いや使い方を解説していきたいと思います。
(※今回はブログで前半部分までを無料公開しております)
目次
何ができる?i2iとどう違う?
Controlnet導入方法
「OpenPose」でキャラのボーンを引用する
「Depth」で深度情報を抽出しよう
「Canny」を使って主線や輪郭を引用
「Hed」で色合いや光源だけを変更しよう
「normal_map」で法線情報を参照
「mlsd」で直線だけを抽出
「openpose_hand」で手の位置も写し取る
「scribble」でマウス絵をイラストに!
「fake_scribble」でふんわり構図を写し取る
終わりに
何ができる?i2iとどう違う?
さて、本題に入る前に、controlnetがこれまでの技術とどう違うのか?どんなことができるのか?について簡単に触れておきます。
Controlnetはtext2imageの画面でも運用されるものの、見本となる画像をもとに新たな画像を生成するわけですから、本質的には「image2image」に近い技術です。これまで、AIに何を描けばいいか指示するには「言葉で説明する(プロンプトによるt2i)」か「見本画像で説明する(image2image)」の2つの方法があったわけですが、ここに「ボーン(キャラの骨組み)で説明する」「深度情報で説明する」「着色前の線画を見せて説明する」「適当に描いたトンチキ絵で説明する」「ノーマルマップで説明する」などがいきなり加わったと考えてください。要するに革命です。
では、i2iとどこが違うのか。従来のi2iは基画像の「色」を主に参照して、おおむねどの位置に何を描けばいいかをプロンプトを見ながら判断するものでした。うまくいく場合もありますが、どうしても参照元画像の色に引っ張られてしまうのがネックで、例えば自由に着色することは苦手でしたし、どこに何が描かれているかを本質的に理解するわけではないので、スカートがカーテンに化けたり、肌色に近い背景部分にキャラクターが出現したりといった現象も起きがちでした。また、白黒の線画をもとにAIが色を塗るようなこともできませんでした。
一方ControlNetは、画像から姿勢や輪郭(=ほとんど線画)や深度情報といったさまざまな情報を抽出することができる技術です。線画からいきなり完成イラストレベルに塗りを加えることもできるし、画像から線画だけを抜き出して別のイラストとして着色しなおすこともできるし、姿勢や構図だけを引用してまったく別のイラストに仕上げることもできるわけです。本質的にはi2iに似ていますが、「基となる画像から色以外の多彩な情報を読み取って、人間の意図をより正確に再現できるようになった画像生成技術」それがControlnetと言えるでしょう。
Controlnet導入方法
Controlnetをめぐっては、数日程度で情報が古くなってしまう異常事態となっていますが、とりあえず記事執筆時点(2023/02/16)の導入方法を紹介します。
1.拡張機能をインストール
WebUIの拡張機能(Extensions)タブにある「URLからインストール(Install from URL)」の画面を開きます。「拡張機能のリポジトリのURL」欄に下記のURLを入力して「インストール」ボタンを押すだけでOKです。
https://github.com/Mikubill/sd-webui-controlnet.git
インストールできたら、WebUIをリロードします。拡張機能の「インストール済」タブから、「適用してUIを再起動」しましょう。
{kind=link}
成功していれば、txt2image画面の下の方に「Controlnet」というタブが出現しているはずです。
2.モデルをダウンロード
ControlNetのモデルをダウンロードします。ControlNet-modules-safetensorsから、「control_canny-fp16.safetensors」など8つのsafetensorsファイルをダウンロードし、「stable-diffusion-webui\extensions\sd-webui-controlnet\models」フォルダに放り込みましょう。それぞれモデル名をクリックすると、リンク先に個別にdownloadボタンがあります。gitが分かる人は右上のhow to cloneを押してgitした方が早い。
{kind=link}
このようになっていればOK。あっという間にインストールが終わってしまいました。これら一つひとつがこれから説明する参考画像からの情報抽出に使われるモデルなわけです(例えば、openpose-fp16がキャラの骨組み抽出に必要なモデル)。下記を読んで「Openposeとdepthだけ使うかな」という方はその2つだけダウンロードするのでも構いませんが、全部使うと思うな…
では、さっそく実際に生成してみましょう!
「OpenPose」でキャラのボーンを引用する
{kind=link}
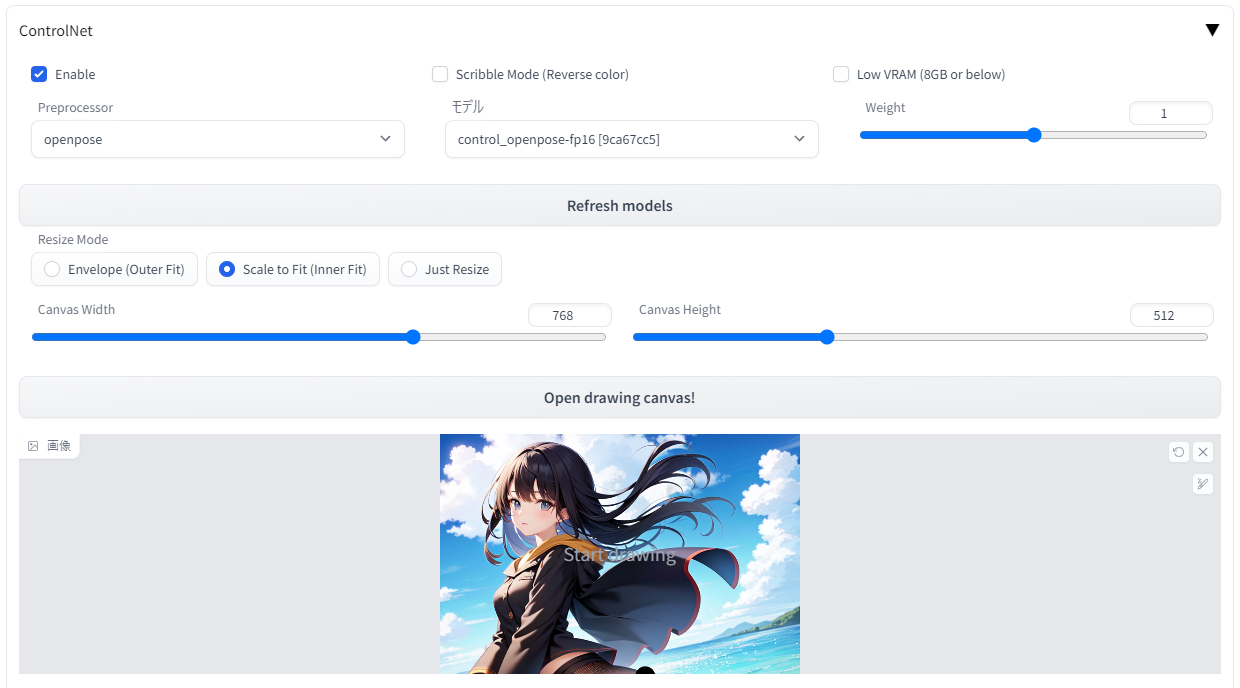
まずは8つのモデルのうち、キャラをボーン(棒人間)化してポーズを写し取ってくれる「openpose」というモデルを使って、既存のイラストから新しい画像を生成してみます。今回はこちらの女の子のポーズを借りてみましょう。
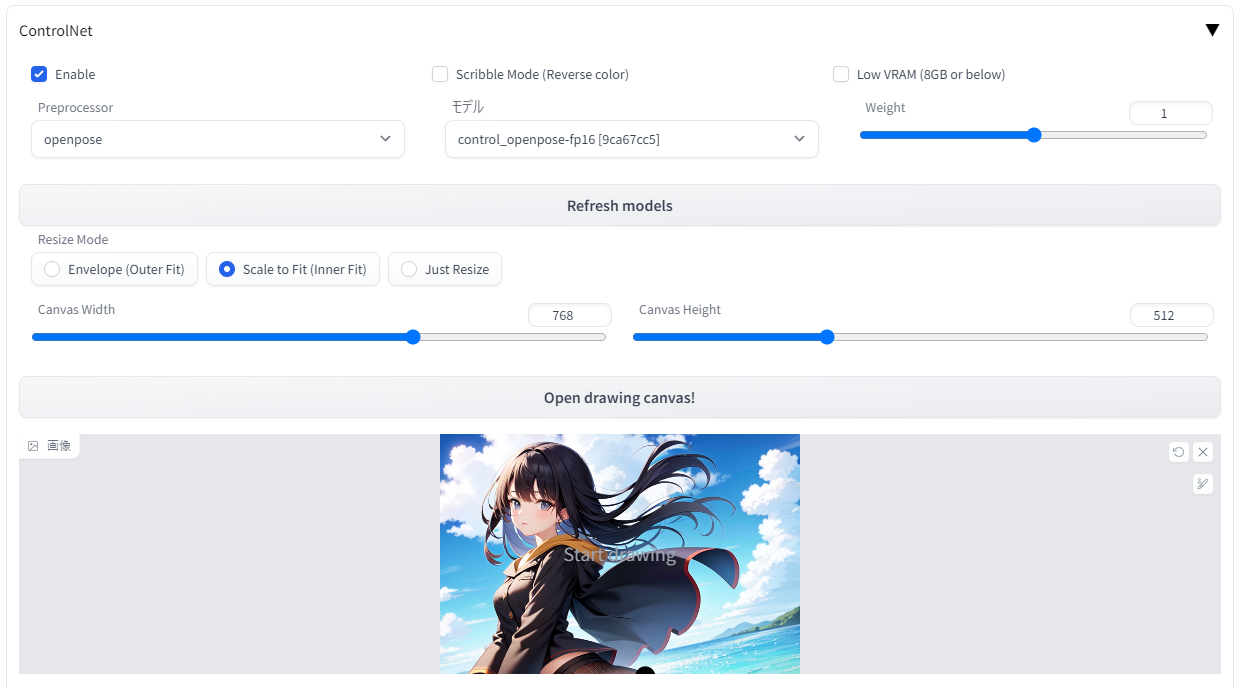
・Controlnetのタブを開いてEnableにチェックを入れ、preprocessor欄で「openpose」を、Model欄で「control_openpose-fp16」を選択します(modelフォルダにちゃんと配置したのに何も表示されない場合は、webui をリロード/再起動してみてください)
・次に「Image」欄に画像をドラッグアンドドロップ。Canvas widthとheightにはこの画像と同じサイズ(または同じ比率)を入力します。横縦を間違えないようにしましょう。
注:横縦のサイズがそれぞれ64の倍数になっていないとエラーが起こるのでご注意ください!
・Controlnetはグラフィックスメモリ(VRAM)12GB以上推奨ですが、8GB以下の環境でメモリエラーが出てしまう場合は「Low VRAM (8GB or below)」のチェックボックスをONにしましょう。画像の生成速度が大きく下がる代わりに、VRAM不足の環境でもエラーを回避して生成することができます。VRAM4GBでも動作したとの報告あり。
{kind=link}
するとこのような感じになります。Weightは元画像をどれくらい影響させるかなので、最初は「1」で。通常のプロンプト欄には、「1girl」のみを記入し、生成する画像サイズもさきほどの参考画像の比率と同じにしましょう。Hires.fixを掛けるなど、このあたりはいつもどおりの感覚でOKです。
生成ボタンを押しましょう!ぽちっとな…。最初は反応がなくてビビりますが、webUIの黒い画面を見てみると、初回のみ必要なファイルのダウンロードが行われているのでちょっと時間がかかります。
まもなくして…
{kind=link}
!!!!!
{kind=link}
!!!!!
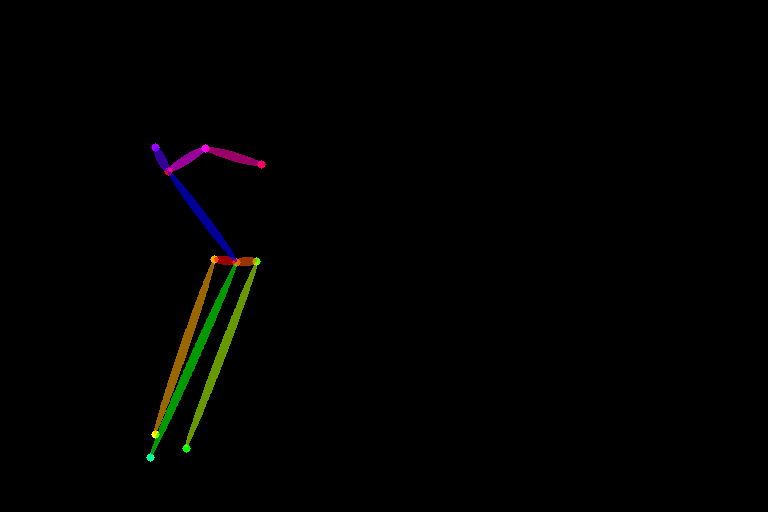
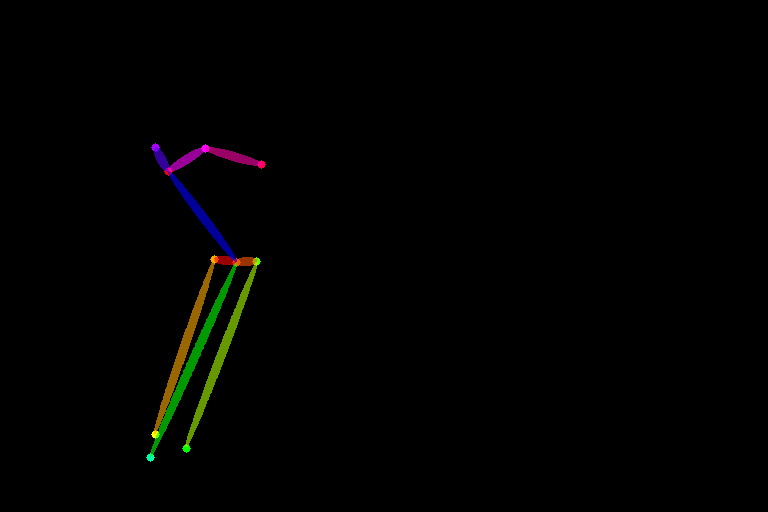
しっかり元イラストのボーン(棒人間)が検出され、構図がコピーされています!感動!!ピンクと赤の線は腕ではなく、頭部とこめかみ、耳の位置関係を表しています。これがあるので、人物が斜めにこちらを見ていることがAIにも分かるわけですね。(画像と見比べてみてください)
{kind=link}
さきほどは「1girl」でしたが、プロンプトを工夫するとこんなことも可能に。さきほどの棒人間画像は元画像の末端や指の位置まで認識していないので、プロンプトの「peace sign」に反応してこのような出力が行われるわけです。
ちなみに、参考画像によっては、学習モデルがうまくボーンを抽出できないことがあるようですが(その場合ボーン画像が真っ黒になる)、自分で棒人間画像を描いてそれを基に生成することもできます。その場合はpreprocessorを「None」にすればOKです。
「Depth」で深度情報を抽出しよう
今度は「Openpose」ではなく、「Depth」を使ってみます。これはさきほどのボーンの代わりに元画像から立体的な深度情報を擬似的に抽出し、それを参考に新たな画像を生成する方法。
使い方は、先程設定したPreprocessorを「depth」、モデルを「control_depth-fp16」に変えるだけでOKです。今度はプロンプトをぼっちちゃんにして…どん!
{kind=link}
▼元画像から抽出された深度情報
{kind=link}
▼元画像
{kind=link}
{kind=link}
こんなの泣くだろ。
今度はボーンではなく、画像の陰影などを基に奥行きを含めた深度情報を得て、それを参考に画像が出力されているのが分かると思います。Openposeとの違いは、たなびく髪の毛や手の位置まで忠実に再現されていること。髪型など輪郭が違うキャラクターを生成したい場合は「OpenPose」の方を使わないと髪型まで引用されてしまうので、このあたりは目的によってどのモデルを使うか判断すれば良いようですね。
「Canny」を使って主線や輪郭を引用
今度はCannyというモデル。こちらは画像の輪郭部分を線画のように抽出して、それを参考に画像を出力してくれるモデルです。Depthが立体的な位置関係を処理できるのに対し、こちらはあくまでイラストの主線を参考にする違いがあります。
{kind=link}
{kind=link}
Depthと違い、キャラの主線や服装の詳細、背景の雲まで詳細に写し取りながら、プロンプトを基に新たなイラストを描いていることが分かります。抽出された線画は無表情ですが、プロンプトの「smile」に反応して口元は笑顔になっていますね。
ところで、ControlNetのUI上では「Weight(重み、影響度)」を指定することができます。Cannyの「Weight:1」だと上のように忠実な写し取り方になりますが、「0.2」にすると…
{kind=link}
このように、影響度をより軽くして、プロンプトをより重視させることもできます。髪の毛の翻り方や背景の雲を見ると、表現に幅ができていることがわかるかと思います。
「Hed」で色合いや光源だけを変更しよう
「Hed」はCannyに似ていますが、元画像からより多くの情報を受け継いでくれる抽出方法。Cannyが輪郭だけを抜き出すのに対し、タッチも含めた主線の表現を抽出してくれます。つまり、線はそのままに色合いや光源の向き、質感などを変更するのに向いています。
最初の参考画像を基に「1girl」で生成すると…
{kind=link}
{kind=link}
このように、イラストの主線部分は(キャラ・背景問わず)ほぼ保持した上で、色合いや光の当たり具合だけを大胆に変更してくれます。完成状態からさらに質感をガチャるのに最適かも!もちろん色合いなどはプロンプトで詳細に指示することも可能です。
ここまで来ると、もはや画像編集ソフトが前時代的なツールに思えてきますね…。グロー効果とかグリザイユ技法を学んでたのはなんだったんだ
「normal_map」で法線情報を参照
ここからは駆け足で紹介しますよ!
normal_mapはその名の通り、下図のように元イラストのノーマルマップ(法線情報)を抽出して新たな絵を描く手法。Depthと似ているが、3dレンダリングで使われるような法線マッピングのアプローチで立体感を抽出します。さきほどのコベニちゃんのイラストを食べさせると…
{kind=link}
{kind=link}
このように、主線ではなく立体感をノーマルマップで抽出してイラストを生成することができます。
「mlsd」で直線だけを抽出
参考画像の中から「直線部分だけ」を選択して取り出す特殊な手法。ビルや小物など、無生物の構造を写し取るときに有用だが、キャラクターイラストだと出番がない。最初の女の子イラストを参考にしても、画像内にほとんど直線がなく(下図)、右下の水平線だけを写しとれているのが分かります。
{kind=link}
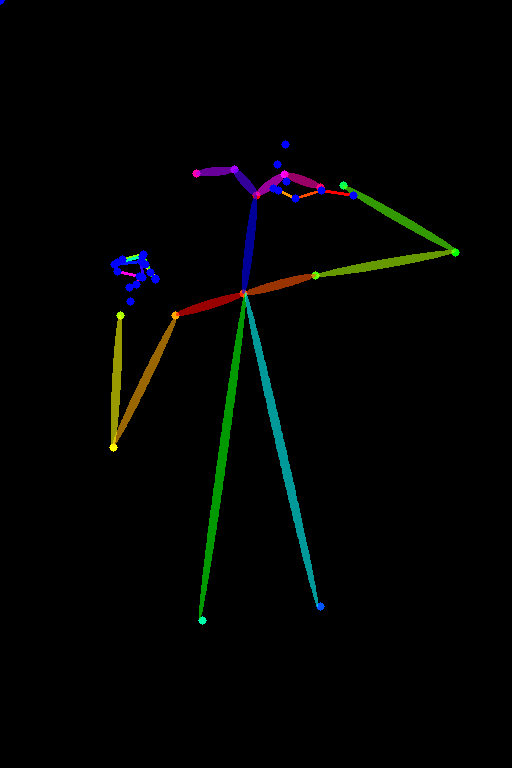
「openpose_hand」で手の位置も写し取る
通常のopenposeが四肢のボーンだけを抽出するのに対し、こちらは手指のボーンも認識できるモデル。指の位置まで詳細に写し取りつつ、元画像の主線はあえて無視したいときにこちらを使いましょう。
{kind=link}
{kind=link}
▲青いプロットが手指の位置を示していることが分かります。
「scribble」でマウス絵をイラストに!
「scribble」は主線を絶対的に重視するのではなく、ほどよく参照して描き出す手法。マウス画やラフ画を基にイラストを仕上げたいときに使えます。
賢木がマウスでちょちょっと書いたこちらのイラストを食べさせると…
{kind=link}
{kind=link}
なんてこった…
「fake_scribble」でふんわり構図を写し取る
こちらは元画像を一回マウスで描いたような落書きに変換してから、先程のscribbleで処理する方法。このひと手間によって元画像の構図やポーズをふわっと写し取ることができます。使い方はPreprocessorを「fake_scribble」に、モデルを「scribble」にするだけです。
openposeとcannyの関係でもそうでしたが、あまり元画像の主線を重視しすぎると、デザインの異なるキャラクターに入れ替えるのが難しいという問題がありました。たとえば下図のコベニちゃんイラストをそのままcannyすると、ポニテやスーツなどが読み取られてしまうわけですが、fake_scribbleに食べさせると…
{kind=link}
このようなざっくりした主線が抽出されて…
{kind=link}
{kind=link}
どん!
となるわけです。なんだよこれ、神の技術か?
ところで、これらの画像はコベニちゃん画像の背景が微妙に写し取られて、画面右に枠線ができていますね。当然ですが抽出された落書き線は消したり足したりできるわけですから、この背景線が邪魔なら…もう言わなくても分かるな。
※「segmentation」だけはなぜか私の環境ではうまくいかなかったので、きちんと試してから紹介したいと思います。
終わりに
{kind=link}
今夜初めてControlnetを試したのですが、歴史が塗り替わったといっても差し支えないほどの急激な変化に、正直言って衝撃を受けています。「i2iの手法が突然8種類増えた」というか、なんというか…。これができるようになると本当に表現手法の広がりが尋常ではないなと思うとともに、i2iパクラーの登場のとき感じた危うさを感じてしまうほどです。
でも逆に言えば、ラフ画程度の技術があれば「scribble」でいきなり画像を作れるので、わざわざ他人のものパクる意味が消失しているんですよね。絵が描けない人間にもここまで多彩な表現ができるようにしてくれるControlNetは、自分の描きたいアイデアと少しの根気さえあれば、あらゆる表現を可能にしてくれる夢の技術。これを使って他人のイラストをパクる人間は、本当に創作する気が最初からない悪人だけだと思います。
プロンプトを組んだら、マウスでおおまかな構図をささっと描く→LoRAなどを併用して「scribble」でガチャ→うまくできたものを「canny」や「openpose」で写し取ってさらにブラッシュアップ→構図を完璧にし、Hedでお好みの色合いに調整する…といったコンボ技を使えば、ガチで未来の作画技術。次回は、この技術をフルに使ってエロ創作をしたらどうなるか!?を検証していきたいと思います。
それでは現在午前4時15分!興奮して眠れそうにありませんが、出勤時間が迫っているので、賢木はそろそろ寝ます。再見!
Files