Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

【限】最適化 (Pixiv Fanbox)
Downloads
Content
前回した、リストの「最適化」ですが、
あれは、純粋に必要なエイリアスを、
「前からの要素を拾っていって最大効率になる手法」といえます。
⇒つまり貪欲法です。
ここで別途、疑問に思ったのが
「辞書データとして使用している、cmdict全体を「もし録ったら」というダミーデータを仮に作って(*1)、oto.iniを生成させ、それを上記の貪欲法の手法で単語を抜き出せば、cmudict全体からミニマライズした英単語リストが作れるのではないか?」という疑問です。
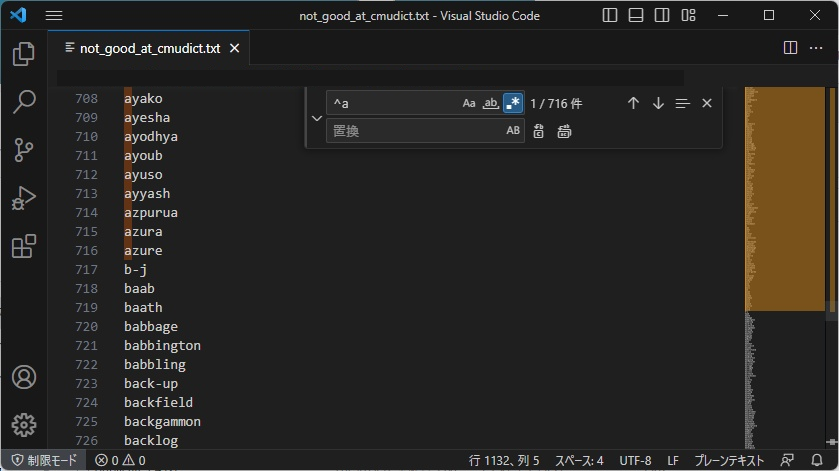
結果、それらしいリストにはなります。ただ以下の図を見てもらえれば分かりますが、正確にはあまりよくないリストになります。
ソートされた単語リストを使えば、当然、前から単語が選ばれがちになります。
{kind=link}
1132単語で収録できるようですが、そのうち716個が「a」から始まるものとなってしまいます。これはよくありません。
これを、プログラミングよわよわでも実装できそうな、多点出発局所探索法を使用して、最適化を行いました。
50回試行させると最終的に200個くらい減って、904単語を録ればcmudict全体の音素を録れるリストができました。
逆にこの結果から、
リストの英単語数が900ぐらいを超えているのであれば、読みやすさを重視するあまり、冗長部分が過分になっていることがわかります。
じゃあ、
「自分が作っていたリストでそれをこれやったらいくつ減るのかな?わくわく!」
って思って実行してみました。
その結果、617単語だったところ、571単語まで減り、更に46語も減らすことができました。かなり現実的なリストになってきてる実感が湧いてきていて、自分としてもなかなか良いものができつつあるんじゃないのかな?と思ってしまうところであります
(*1)ダミーデータを作る処理
index.csvを分解して、
=====sample.txt=====
ダミーラベル時刻 ダミーラベル時刻 sil
ダミーラベル時刻 ダミーラベル時刻 ラベルname
…
ダミーラベル時刻 ダミーラベル時刻 sil
===== =====
という感じで分解するものを作れば「録った」ことになる。
…まぁ、いちいち実際にtxtファイルを作らずにデータとして処理した方が速そうですが…
Files