Home
Home

 Artists
Artists
 Search
Search
 Recent
Recent
 Random
Random
 Posts
Posts
 DMs
DMs
 Tags
Tags
 Random
Random
 Importer
Importer
 Import
Import
 FAQ
FAQ
 Account
Account
 Register
Register
 Favorites
Favorites
 Login
Login

デユイの日記2 (Pixiv Fanbox)
Content
I haven't been posting anything for the last 2 days so I kinda feel bad about it, but at the same time I don't reeeeeeeeally have anything to show for the last 2 days because it's either commission, school work and some random stuff I got really into lately.
So remember when I told you guys I am REEEEALLLY into Silver Wolf lately? Yeah I really hoped there was some kind of Silver Wolf ASMR specifically for the JP voice actor "Kana Asumi", but there wasn't. Like sure she did ASMR before but she used a different voice for them so it didn't feel right. (there was also some silver wolf rizuna asmr cosplay too BUT THAT WWASNT WHAT I WAS LOOKING FOR RIGHT NOW) SO I WAS LOST. I COULDNT SATISFY MY THIRST AND DESIRE. So I was like sure I could be satisfied with just listening to cutie Silver Wolf's voicelines, which I could I guess get by watching Playthrough videos of her events/missions. But the problem is that there's usually a lot of downtime and noise that I can't thoroughly enjoy it.
I couldn't sit tight. I couldn't focus on drawing. I HAD TO FIND A SOLUTION. THE ONLY SOLUTION, GET THE RAW AUDIO FILES AND PUT THEM TOGETHER.
SO I WENT DOWN THE RABBIT HOLE, FIND THE SOURCE AUDIO FILES, EXTRACT THE PCK FILES, THEN CONVERT THEM TO MP3 BUT THEN CONVERT THEM AGAIN FOR WAV FILE BECAUUUUUUUUUUUUUUUSE I NEED IT FOR WHAT IS TO COME. ALSO I TOTALLY DID NOT EXTRACT THE PCK SOURCE FILES FOR IT BECAUSE ITS BORDERLINE AGAINST TOS, IS IT STILL TOS IF I SAY I JUST OBTAINED THE FILES ONLINE´???
ここ2日間、何も投稿していないから、ちょっと悪い気分かな。でも、同時に、ここ2日間、委託作業や学業、最近は興味を持ったさまざまなことに取り組んでいたから、本当に見せるものがないっていうのもあるんだ。
さて、君たちに言ったこと覚えてるかな?最近、銀狼にすっごくはまっているって。そう、本当に「銀狼」のASMRが、特に声優の「Kana Asumi」さんのものがあればいいなと思ってたんだけど、なかったんだよ。もちろん、彼女は以前にASMRをやったことはあるけど、そのときは違う声を使っていて、それが違和感を感じさせたんだよ。それに、銀狼のリズナさんのASMRコスプレなんかもあったけど、今はそれを求めているわけじゃなかったんだ。
だから、私は迷子になっちゃったんだ。渇望と欲求を満たせなくて。だから、可愛い銀狼のボイスラインを聞いて満足しようと思ったんだ。イベントやミッションのプレイスルー動画を見れば、それができるかもしれないって思ったんだけど、問題はそうするとたいてい待ち時間やノイズがあって、それをじっくり楽しむことができないことなんだよ。
落ち着いていられなかったし、絵を描くことにも集中できなかったんだ。解決策を見つけなければならなかった。唯一の解決策、それは生のオーディオファイルを手に入れて、それらを組み合わせること。
だから、私はウサギの穴に入っていったよ、ソースオーディオファイルを見つけ、PCKファイルを抽出し、それをMP3に変換し、そしてまたWAVファイルに変換したんだ。なぜなら、これからのことにそれが必要だからね。
THE AUDIO FILES ARE NOT SORTED, THEYRE COMPLETELY RANDOM. SO HOW CAN I GET ALL THE SILVER WOLF AUDIO FILES WITHIN THE EXACTLY 27907 AUDIO FILES. MATHEMATICALLY SPEAKING IF I REALLY WANTED TO DO IT, I WOULD TAKE AROUND 77 HOURS OR 2.8 DAYS TO LISTEN TO ALL OF THEM WITHOUT BREAKS ASSUMING THE AVERAGE VOICE LINES ARE 10s LONG. I USED TO DO THAT ACTUALLY BACK THEN WHEN I WAS DOING MY CLARA VIDEO AND WAS LOOKING FOR FITTING CLARA VOICE LINES (https://youtube.com/shorts/DkdlEzdt6qk)
HOWEVER IM NOT THAT CCRAZY SO I HAD TO BE SMART
SO WHAT COULD I DO???
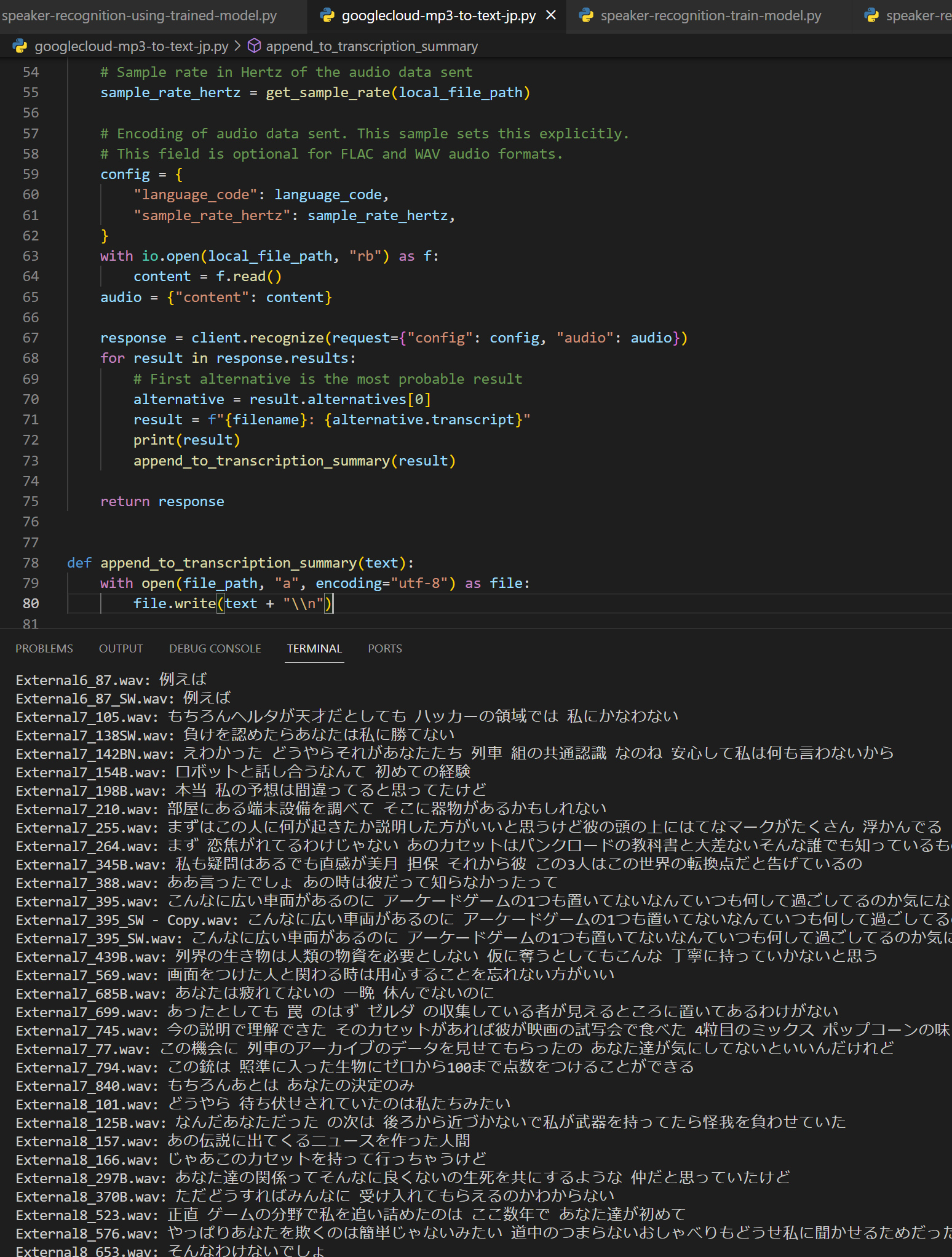
INITIALLY MY IDEA WAS USING THE GOOGLE CLOUD SPEECH API I WILL JUST WRITE A PYTHON CODE THAT RUNS THROUGH ALL THE VOICE LINES AND WRITES DOWN THE TRANSCRIPTION INTO A TXT FILE, THUS I COULD SEARCCH FOR SILVER WOLVES' VOICE LINE BASED ON WHAT SHE SAYS AND KEYWORDS.
オーディオファイルは整理されていなく、完全にランダムだから、どうやって正確に27907の銀狼のオーディオファイルを手に入れるか?数学的に言えば、それを本当にやりたいなら、休憩なしでそれらをすべて聞くのに約77時間または2.8日かかると仮定して、平均的なボイスラインが10秒であるとします。実際、私は以前、私のクララのビデオを作成していたとき、適切なクララのボイスラインを探していたときにそれを行っていました。(https://youtube.com/shorts/DkdlEzdt6qk)
ただし、そこまでクレイジーではないので、賢くやらなければなりません。では、どうすればいいのでしょうか?最初のアイデアは、Google Cloud Speech APIを使用することでした。Pythonコードを書いて、すべてのボイスラインを通過し、トランスクリプションをテキストファイルに記録するだけで、彼女が言ったことやキーワードに基づいて銀狼のボイスラインを検索できるようになります。
{kind=link}
I TRIED TO RUN THROUGH LIKE A FEW THOUSAND FILES AND I THINK THE FREE TRIAL CREDIT WOULD ACTUALLY WORK HOWEVER I FELT IT WOULD STILL TAKE TOO LONG ITS TOO INEFFICIENT
何千ものファイルを試しましたが、無料トライアルクレジットを実際に使えると思います。でもそれでも時間がかかりすぎて非効率的だと感じたんだ。
{kind=link}
AIGHT GUYS SO WHAT WOULD BE A BETTER APPROACH? WELL ITD BE COOL IF THE COMPUTER WOULD JUST LISTEN TO ALL THE AUDIO FILES FOR ME AND TELL ME WHICH ONE IS SILVER WOLF AND GIVE IT TO ME
「わかった、すごいね!どうやってそれが可能なんだろう?」
「スピーカー識別!!!」、話している人を識別する方法だよ、ちょうど私の用途にぴったりだったから、良いAPIやサービスがないか調べてみたんだ。そして、Microsoft Azureに実際にそのようなサービスがあることを見つけたんだけど、なんと、それが一般には利用できなくて、特定の人々だけに提供されているってことが判明したよ。
AIGHT GREAT HOW WOULD THAT BE POSSIBLE?
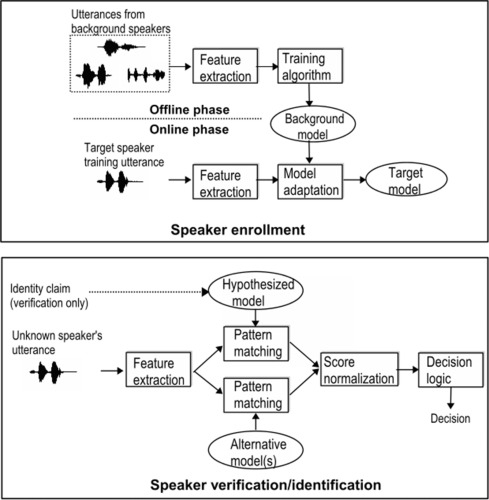
SPEAKER RECOGNITION!!! THE METHOD OF IDENTIFYING WHO IS TALKING, PERFECT FOR MY USE CASE SO I LOOK UP IF THERE IS ANY GOOD APIS OR SERVICES I COULD BORROW AND I SAW MICROSOFT AZURE ACCTUALLY HAD A SERVICE LIKE THAT UNTIL THEY HIT ME WITH THE GODDAMN GATEKEEP ITS ONLY AVAILBLE FOR SPECIFIC PEOPLE
それでは、どうやってそれを実現できるか考えてみましょう。話者識別ですね!誰が話しているかを識別する方法、私の用途にはぴったりです。それで、良いAPIやサービスがあるか調べてみました。Microsoft Azureにはそのようなサービスがあることを見つけましたが、特定の人々にしか利用できないという制約があるようですね。
{kind=link}
THEN IM LIKE AIGHT BITCH ILL DO IT MYSELF
SO I LOOKED UP SPEAKER RECOGNITION ALGORITHMS AND METHODS UP MYSELF AND DISCLAIMER THIS IS MY FIRST TIME DOING ANYTHING REALLY WITH MACHINE LEARNING
MY FIRST ITERATION WAS USING SHORT TERM FEATURES FORM THE PYAUDIOANALYSIS LIBRARY ON PYTHON THEY SEEM TO HAVE A LOT OF HELPFUL LIBRARIES REGARDING AUDIO ANALYSIS AND SPEAKER RECOGNITION SO IT WAS ONE OF THE BEST TOOLS FOR THIS CASE TO USE
それで、それから俺が「わかった、自分でやるぜ!」って感じになって、スピーカー識別のアルゴリズムと方法を自分で調べてみたんだ。ちなみに、これが実際にはじめての機械学習をやることだったから、その点をお伝えしておくよ。
最初の試みでは、PythonのPyaudioanalysisライブラリを使ってショートタームフィーチャーを使ったんだ。音声解析とスピーカー識別に関する便利なライブラリがいくつかあるみたいで、このケースには最適なツールの一つだったんだよ。
{kind=link}
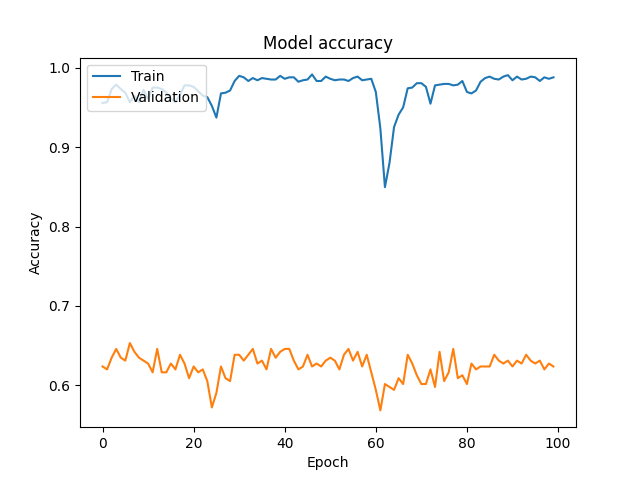
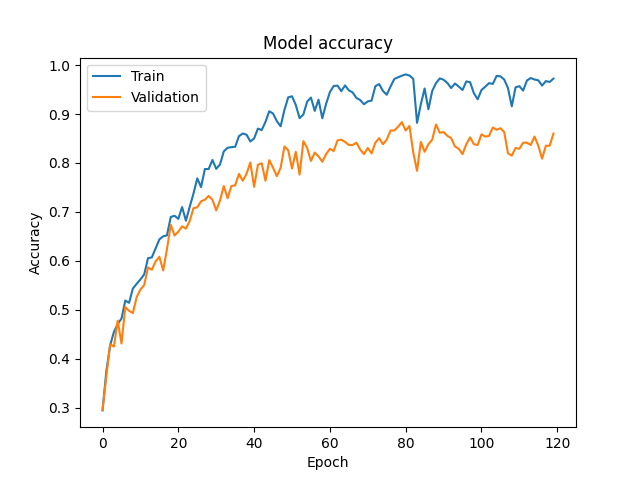
SO THE INITIAL PLAN IS WE TAKE ALL THE FILES WHICH HAVE TO BE WAV FILES NOT MP3 FILES BTW BECAUSE WAV FILES ARE LOSSLESS AND WE NEED THE SAMPLE DATA TO BE AS GOOD AS IT GETS AND EXTRACT INFORMATION FROM IT USING SHORT TERM FEATURES, INFORMATION LIEK I QUOTE "energy in the signal, the frequency content, and statistical properties of the audio segment" FROM WHICH ONE CAN NUMERICACLLY DETERMINE WHICH PERSON IS SPEAKING. SO ONCE WE HAVE ALL THAT DATA WE SCALE IT TO THE SAME FORMAT, SPLIT IT INTO TESTING AND TRAINING DATASETS AND USE MACHINELEARNING TO CREATE A MODEL FROM WHICH WE ULTIMATELY CAN FINALLY PREDICT WHICH CHARACCTER IS SPEAKING FROM A VOICELINE
最初の計画は、すべてのファイルを取ること。それはMP3ファイルではなく、WAVファイルでなければならない、ちなみに。なぜなら、WAVファイルはロスレス(音質の損失がない)だからで、サンプルデータをできるだけ優れたものにしたいんだ。そして、それからそのデータから情報を抽出するんだ。具体的には、「信号のエネルギー、周波数の内容、およびオーディオセグメントの統計的な特性」といった情報を抽出するんだ。これを使って、数値的に誰が話しているかを決定できるんだ。だから、一度そのデータを手に入れたら、同じ形式にスケーリングし、テストデータとトレーニングデータに分けて、機械学習を使ってモデルを作成するんだ。最終的には、声のラインからどのキャラクターが話しているのかを予測できるようになるんだよ。
{kind=link}
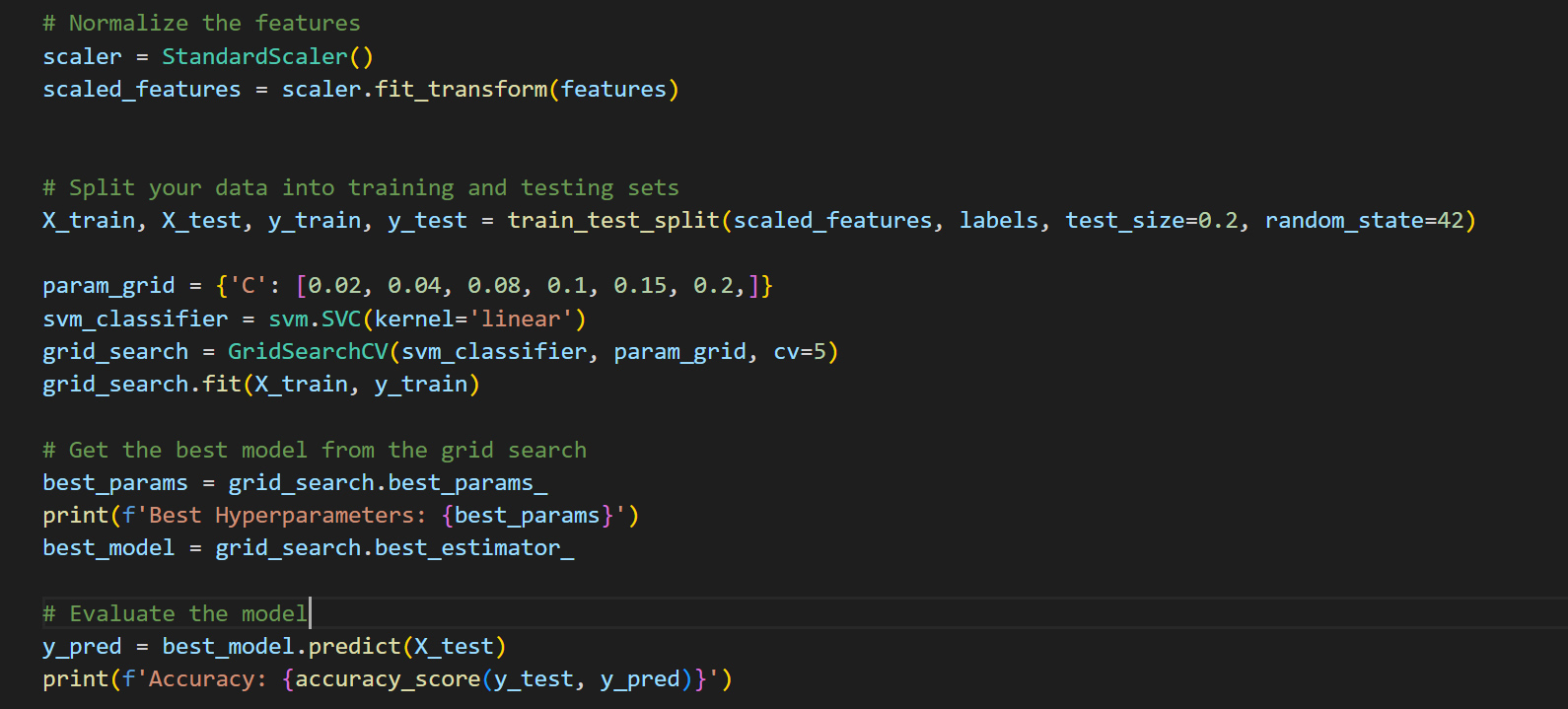
HOWEVER AFTER SOME RESEARCH I HEARD SEVERAL THINGS SUCH AS MFCC IS BETTER THAN USING SHORT TERM FEATURES FOR SPEAKER RECOGNITION AS IT STORES BETTER INFORMATION AS WELL AS DEEP LEAERNING USING NEURAL NETWORK IS BETTER THAN THE MACHINE LEARNING THAT IVE BEEN USING ALSO TO FURTHER ENHANCE OUR MODEL WE USE GRIDSEARCHCV TO FIND THE MOST OPTIMAL HYPERPARAMETERS
SO THATS WHAT I DID
でも、ちょっと調べてみたら、いくつかのことを聞いたんだ。たとえば、スピーカー識別には短期特徴よりもMFCC(メル周波数ケプストラム係数)の方が良い情報を保存できるとか、ニューラルネットワークを使ったディープラーニングの方が、これまでの機械学習よりも良いとか。さらに、モデルをさらに向上させるために、GridSearchCVを使って最適なハイパーパラメータを見つけるんだ。だから、それをやってみたよ。
{kind=link}
AND THEN AFTER SOME ITERATIVE PROGRESS OF IMPROVING THE DATASET BY FINDING MORE VOICE LINES FOR EACH CHARACTER THAT SOUNDS SIMILIAR TO SILVER WOLF SO THE TRAINING CAN MORE EASIER DISTINGUISH BETWEEN THEM TWO UNTIL I FINALLY GOT A MODEL THAT WAS GOOD ENOUGH AND THEN I NOW ONLY HAVE TO GO THROUGH AROUND 5% OF THE INITIAL 30K VOICECLIPS
AND NOW I HAVE PRETTY MUCH ALL THE VOICE LINES AND AM LISTENING TO IT
ALSO THERE WAS A TON OF OTHER OPTIMIZATION TECHNIQUES THAT I TRIED OUT LIKE L2 REGULARIZATION AND EARLY DROPOUT AND HYPERPARAMETER FINETUNIGN AND ALL THAT CRAP SO I COULD STOP MY MODEL FROM OVERFITTING BUT I WONT BOTHER YOU WITH THE DETAILS ANY FUIRTHER
それから、データセットを改善するために何度か試行錯誤しながら、シルバーウルフに似た声のキャラクターの追加のボイスラインを見つけることで、トレーニングがより簡単にそれらを区別できるようにしました。最終的に、十分に良いモデルを手に入れ、今では初めの30,000のボイスクリップの約5%しか聞く必要がありません。そして、ほぼすべてのボイスラインを手に入れ、それを聞いています。
それに加えて、L2正則化、早期ドロップアウト、ハイパーパラメータの微調整など、試した最適化テクニックがたくさんありました。モデルが過学習しないようにするために、それらの詳細についてはあまり詳しく説明しませんが、頑張ったんだよ。
{kind=link}
{kind=link}
ところで、ペナコニーのOSTと「White Night」を聞いて楽しんでいるんだ。ぜひ聞いてみてね!
BTW IVE BEEN JAMMING TO THE PENACONY OST AND WHITE NIGHT PLS LISTEN: https://open.spotify.com/album/4qJdhQLcSfAAm3yxf66ylq
欲しい人がいたら、シルバーウルフのASMRファイルを共有するよ
ALSO HERES THE SILVER WOLF ASMR FILE IF YOU WANT TO LISTEN TOO:
読んでくれてありがとう!
THANKS FOR READING!! _(´ཀ`」 ∠)___(´ཀ`」 ∠)___(´ཀ`」 ∠)__
Files